 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving OCR using internal document redundancy
Aug 20, 2025Current OCR systems are based on deep learning models trained on large amounts of data. Although they have shown some ability to generalize to unseen data, especially in detection tasks, they can struggle with recognizing low-quality data. This is particularly evident for printed documents, where intra-domain data variability is typically low, but inter-domain data variability is high. In that context, current OCR methods do not fully exploit each document's redundancy. We propose an unsupervised method by leveraging the redundancy of character shapes within a document to correct imperfect outputs of a given OCR system and suggest better clustering. To this aim, we introduce an extended Gaussian Mixture Model (GMM) by alternating an Expectation-Maximization (EM) algorithm with an intra-cluster realignment process and normality statistical testing. We demonstrate improvements in documents with various levels of degradation, including recovered Uruguayan military archives and 17th to mid-20th century European newspapers.
Redefining Temporal Modeling in Video Diffusion: The Vectorized Timestep Approach
Oct 04, 2024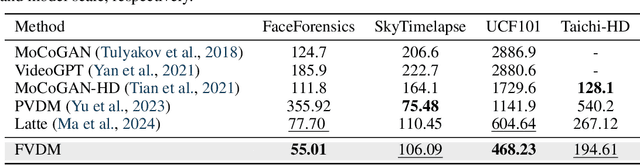
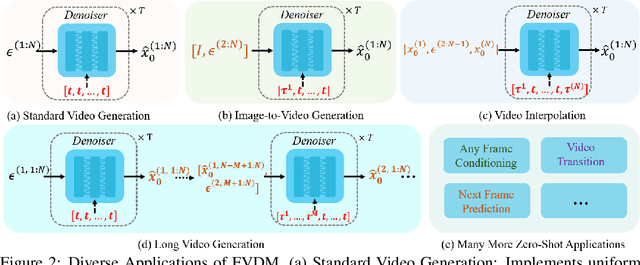
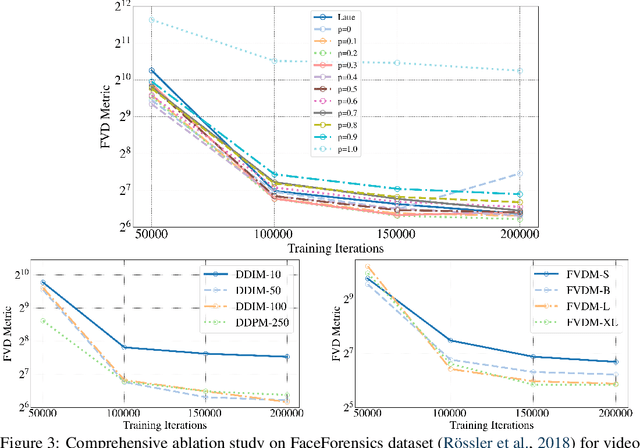

Diffusion models have revolutionized image generation, and their extension to video generation has shown promise. However, current video diffusion models~(VDMs) rely on a scalar timestep variable applied at the clip level, which limits their ability to model complex temporal dependencies needed for various tasks like image-to-video generation. To address this limitation, we propose a frame-aware video diffusion model~(FVDM), which introduces a novel vectorized timestep variable~(VTV). Unlike conventional VDMs, our approach allows each frame to follow an independent noise schedule, enhancing the model's capacity to capture fine-grained temporal dependencies. FVDM's flexibility is demonstrated across multiple tasks, including standard video generation, image-to-video generation, video interpolation, and long video synthesis. Through a diverse set of VTV configurations, we achieve superior quality in generated videos, overcoming challenges such as catastrophic forgetting during fine-tuning and limited generalizability in zero-shot methods.Our empirical evaluations show that FVDM outperforms state-of-the-art methods in video generation quality, while also excelling in extended tasks. By addressing fundamental shortcomings in existing VDMs, FVDM sets a new paradigm in video synthesis, offering a robust framework with significant implications for generative modeling and multimedia applications.
Reducing False Alarms in Video Surveillance by Deep Feature Statistical Modeling
Jul 09, 2023
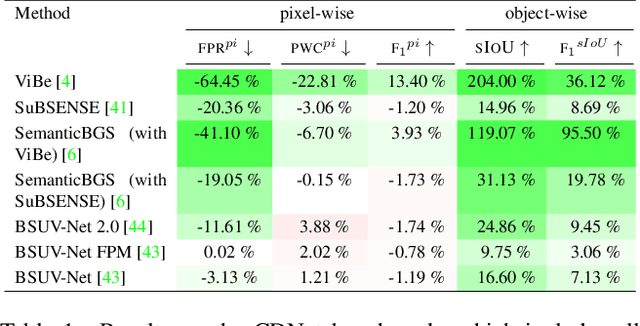
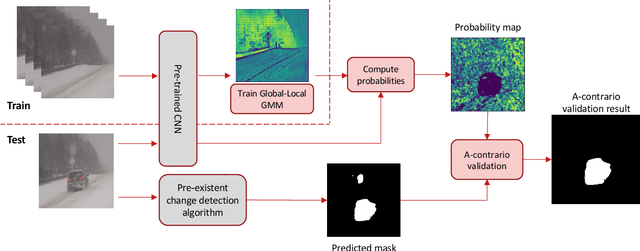
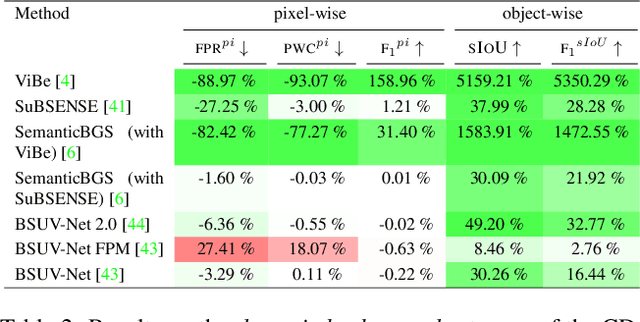
Detecting relevant changes is a fundamental problem of video surveillance. Because of the high variability of data and the difficulty of properly annotating changes, unsupervised methods dominate the field. Arguably one of the most critical issues to make them practical is to reduce their false alarm rate. In this work, we develop a method-agnostic weakly supervised a-contrario validation process, based on high dimensional statistical modeling of deep features, to reduce the number of false alarms of any change detection algorithm. We also raise the insufficiency of the conventionally used pixel-wise evaluation, as it fails to precisely capture the performance needs of most real applications. For this reason, we complement pixel-wise metrics with object-wise metrics and evaluate the impact of our approach at both pixel and object levels, on six methods and several sequences from different datasets. Experimental results reveal that the proposed a-contrario validation is able to largely reduce the number of false alarms at both pixel and object levels.