 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization Limits in Vehicle Re-Identification
Jun 01, 2026Vehicle re-identification focuses on retrieving images of the same vehicle from a gallery given a query image. Upon closer inspection of commonly used datasets, we observe that vehicles with few visual differences-e.g., the same make, model, and color-appear in both the training and test sets. As a result, methods that effectively memorize the training data tend to perform well on these test sets but struggle to generalize to other datasets. In this paper, we address this issue by proposing a novel evaluation approach that more effectively measures generalization capability to unseen vehicle types. To further study generalization performance, we also propose splitting the evaluation based on view, allowing us to differentiate the effect of viewpoint robustness from that of same-view re-identification. Our findings reveal that most state-of-the-art methods struggle with unseen vehicle types, and that their robustness to viewpoint changes and attention to detail are limited to vehicle types seen during training.
An Industrial Dataset for Scene Acquisitions and Functional Schematics Alignment
Feb 17, 2026Aligning functional schematics with 2D and 3D scene acquisitions is crucial for building digital twins, especially for old industrial facilities that lack native digital models. Current manual alignment using images and LiDAR data does not scale due to tediousness and complexity of industrial sites. Inconsistencies between schematics and reality, and the scarcity of public industrial datasets, make the problem both challenging and underexplored. This paper introduces IRIS-v2, a comprehensive dataset to support further research. It includes images, point clouds, 2D annotated boxes and segmentation masks, a CAD model, 3D pipe routing information, and the P&ID (Piping and Instrumentation Diagram). The alignment is experimented on a practical case study, aiming at reducing the time required for this task by combining segmentation and graph matching.
Remote Sensing Change Detection via Weak Temporal Supervision
Jan 05, 2026Semantic change detection in remote sensing aims to identify land cover changes between bi-temporal image pairs. Progress in this area has been limited by the scarcity of annotated datasets, as pixel-level annotation is costly and time-consuming. To address this, recent methods leverage synthetic data or generate artificial change pairs, but out-of-domain generalization remains limited. In this work, we introduce a weak temporal supervision strategy that leverages additional temporal observations of existing single-temporal datasets, without requiring any new annotations. Specifically, we extend single-date remote sensing datasets with new observations acquired at different times and train a change detection model by assuming that real bi-temporal pairs mostly contain no change, while pairing images from different locations to generate change examples. To handle the inherent noise in these weak labels, we employ an object-aware change map generation and an iterative refinement process. We validate our approach on extended versions of the FLAIR and IAILD aerial datasets, achieving strong zero-shot and low-data regime performance across different benchmarks. Lastly, we showcase results over large areas in France, highlighting the scalability potential of our method.
Structure Tensor Representation for Robust Oriented Object Detection
Nov 15, 2024



Oriented object detection predicts orientation in addition to object location and bounding box. Precisely predicting orientation remains challenging due to angular periodicity, which introduces boundary discontinuity issues and symmetry ambiguities. Inspired by classical works on edge and corner detection, this paper proposes to represent orientation in oriented bounding boxes as a structure tensor. This representation combines the strengths of Gaussian-based methods and angle-coder solutions, providing a simple yet efficient approach that is robust to angular periodicity issues without additional hyperparameters. Extensive evaluations across five datasets demonstrate that the proposed structure tensor representation outperforms previous methods in both fully-supervised and weakly supervised tasks, achieving high precision in angular prediction with minimal computational overhead. Thus, this work establishes structure tensors as a robust and modular alternative for encoding orientation in oriented object detection. We make our code publicly available, allowing for seamless integration into existing object detectors.
Exploring Robust Features for Few-Shot Object Detection in Satellite Imagery
Mar 08, 2024



The goal of this paper is to perform object detection in satellite imagery with only a few examples, thus enabling users to specify any object class with minimal annotation. To this end, we explore recent methods and ideas from open-vocabulary detection for the remote sensing domain. We develop a few-shot object detector based on a traditional two-stage architecture, where the classification block is replaced by a prototype-based classifier. A large-scale pre-trained model is used to build class-reference embeddings or prototypes, which are compared to region proposal contents for label prediction. In addition, we propose to fine-tune prototypes on available training images to boost performance and learn differences between similar classes, such as aircraft types. We perform extensive evaluations on two remote sensing datasets containing challenging and rare objects. Moreover, we study the performance of both visual and image-text features, namely DINOv2 and CLIP, including two CLIP models specifically tailored for remote sensing applications. Results indicate that visual features are largely superior to vision-language models, as the latter lack the necessary domain-specific vocabulary. Lastly, the developed detector outperforms fully supervised and few-shot methods evaluated on the SIMD and DIOR datasets, despite minimal training parameters.
Portraying the Need for Temporal Data in Flood Detection via Sentinel-1
Mar 06, 2024


Identifying flood affected areas in remote sensing data is a critical problem in earth observation to analyze flood impact and drive responses. While a number of methods have been proposed in the literature, there are two main limitations in available flood detection datasets: (1) a lack of region variability is commonly observed and/or (2) they require to distinguish permanent water bodies from flooded areas from a single image, which becomes an ill-posed setup. Consequently, we extend the globally diverse MMFlood dataset to multi-date by providing one year of Sentinel-1 observations around each flood event. To our surprise, we notice that the definition of flooded pixels in MMFlood is inconsistent when observing the entire image sequence. Hence, we re-frame the flood detection task as a temporal anomaly detection problem, where anomalous water bodies are segmented from a Sentinel-1 temporal sequence. From this definition, we provide a simple method inspired by the popular video change detector ViBe, results of which quantitatively align with the SAR image time series, providing a reasonable baseline for future works.
Reducing False Alarms in Video Surveillance by Deep Feature Statistical Modeling
Jul 09, 2023
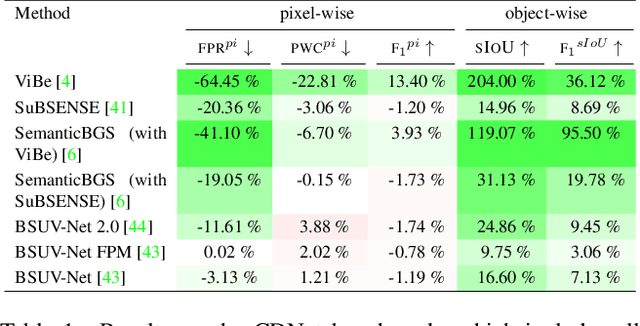
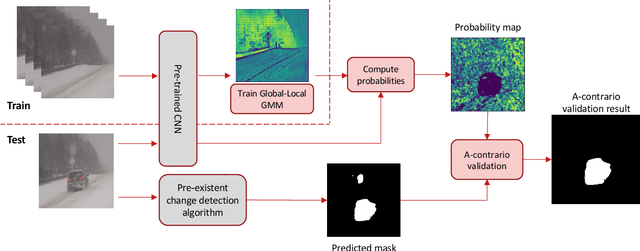
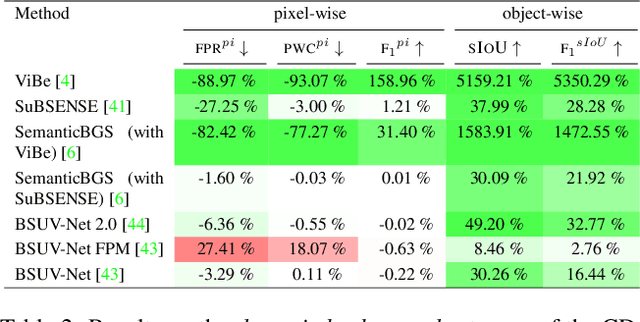
Detecting relevant changes is a fundamental problem of video surveillance. Because of the high variability of data and the difficulty of properly annotating changes, unsupervised methods dominate the field. Arguably one of the most critical issues to make them practical is to reduce their false alarm rate. In this work, we develop a method-agnostic weakly supervised a-contrario validation process, based on high dimensional statistical modeling of deep features, to reduce the number of false alarms of any change detection algorithm. We also raise the insufficiency of the conventionally used pixel-wise evaluation, as it fails to precisely capture the performance needs of most real applications. For this reason, we complement pixel-wise metrics with object-wise metrics and evaluate the impact of our approach at both pixel and object levels, on six methods and several sequences from different datasets. Experimental results reveal that the proposed a-contrario validation is able to largely reduce the number of false alarms at both pixel and object levels.
The whole and the parts: the MDL principle and the a-contrario framework
Dec 13, 2021
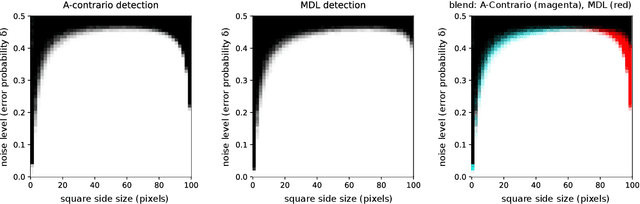


This work explores the connections between the Minimum Description Length (MDL) principle as developed by Rissanen, and the a-contrario framework for structure detection proposed by Desolneux, Moisan and Morel. The MDL principle focuses on the best interpretation for the whole data while the a-contrario approach concentrates on detecting parts of the data with anomalous statistics. Although framed in different theoretical formalisms, we show that both methodologies share many common concepts and tools in their machinery and yield very similar formulations in a number of interesting scenarios ranging from simple toy examples to practical applications such as polygonal approximation of curves and line segment detection in images. We also formulate the conditions under which both approaches are formally equivalent.
Psychophysics, Gestalts and Games
May 25, 2018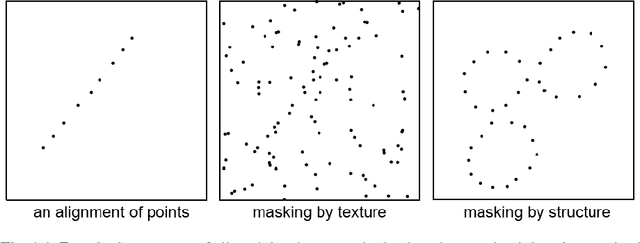


Many psychophysical studies are dedicated to the evaluation of the human gestalt detection on dot or Gabor patterns, and to model its dependence on the pattern and background parameters. Nevertheless, even for these constrained percepts, psychophysics have not yet reached the challenging prediction stage, where human detection would be quantitatively predicted by a (generic) model. On the other hand, Computer Vision has attempted at defining automatic detection thresholds. This chapter sketches a procedure to confront these two methodologies inspired in gestaltism. Using a computational quantitative version of the non-accidentalness principle, we raise the possibility that the psychophysical and the (older) gestaltist setups, both applicable on dot or Gabor patterns, find a useful complement in a Turing test. In our perceptual Turing test, human performance is compared by the scientist to the detection result given by a computer. This confrontation permits to revive the abandoned method of gestaltic games. We sketch the elaboration of such a game, where the subjects of the experiment are confronted to an alignment detection algorithm, and are invited to draw examples that will fool it. We show that in that way a more precise definition of the alignment gestalt and of its computational formulation seems to emerge. Detection algorithms might also be relevant to more classic psychophysical setups, where they can again play the role of a Turing test. To a visual experiment where subjects were invited to detect alignments in Gabor patterns, we associated a single function measuring the alignment detectability in the form of a number of false alarms (NFA). The first results indicate that the values of the NFA, as a function of all simulation parameters, are highly correlated to the human detection. This fact, that we intend to support by further experiments , might end up confirming that human alignment detection is the result of a single mechanism.
From line segments to more organized Gestalts
Mar 18, 2016

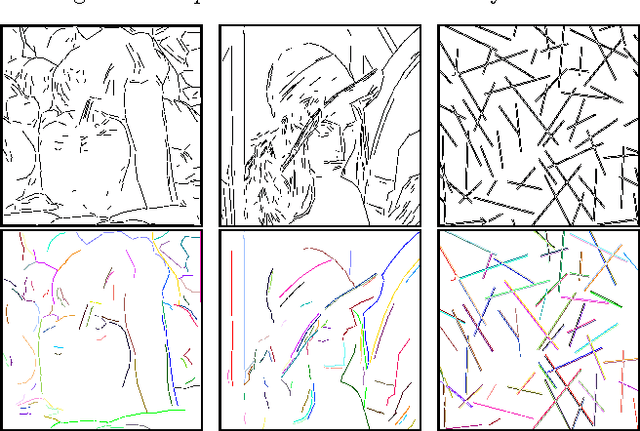
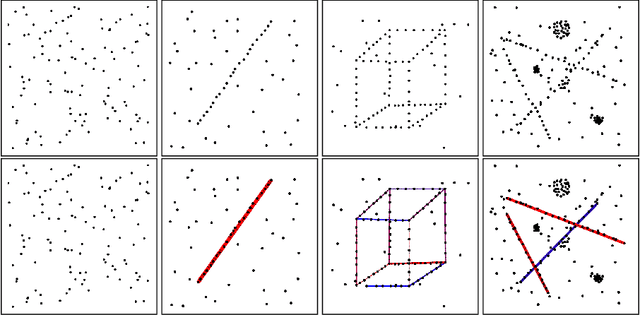
In this paper, we reconsider the early computer vision bottom-up program, according to which higher level features (geometric structures) in an image could be built up recursively from elementary features by simple grouping principles coming from Gestalt theory. Taking advantage of the (recent) advances in reliable line segment detectors, we propose three feature detectors that constitute one step up in this bottom up pyramid. For any digital image, our unsupervised algorithm computes three classic Gestalts from the set of predetected line segments: good continuations, nonlocal alignments, and bars. The methodology is based on a common stochastic {\it a contrario model} yielding three simple detection formulas, characterized by their number of false alarms. This detection algorithm is illustrated on several digital images.