 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-precision camera distortion measurements with a "calibration harp"
Dec 22, 2012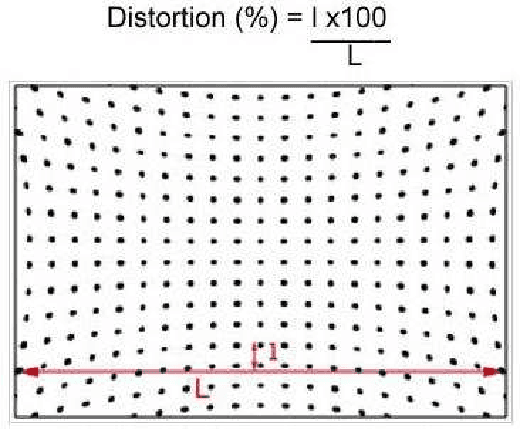



This paper addresses the high precision measurement of the distortion of a digital camera from photographs. Traditionally, this distortion is measured from photographs of a flat pattern which contains aligned elements. Nevertheless, it is nearly impossible to fabricate a very flat pattern and to validate its flatness. This fact limits the attainable measurable precisions. In contrast, it is much easier to obtain physically very precise straight lines by tightly stretching good quality strings on a frame. Taking literally "plumb-line methods", we built a "calibration harp" instead of the classic flat patterns to obtain a high precision measurement tool, demonstrably reaching 2/100 pixel precisions. The harp is complemented with the algorithms computing automatically from harp photographs two different and complementary lens distortion measurements. The precision of the method is evaluated on images corrected by state-of-the-art distortion correction algorithms, and by popular software. Three applications are shown: first an objective and reliable measurement of the result of any distortion correction. Second, the harp permits to control state-of-the art global camera calibration algorithms: It permits to select the right distortion model, thus avoiding internal compensation errors inherent to these methods. Third, the method replaces manual procedures in other distortion correction methods, makes them fully automatic, and increases their reliability and precision.
Are You Imitating Me? Unsupervised Sparse Modeling for Group Activity Analysis from a Single Video
Aug 27, 2012
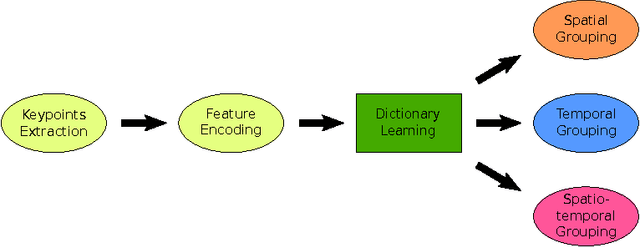
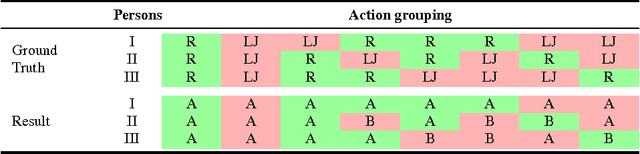
A framework for unsupervised group activity analysis from a single video is here presented. Our working hypothesis is that human actions lie on a union of low-dimensional subspaces, and thus can be efficiently modeled as sparse linear combinations of atoms from a learned dictionary representing the action's primitives. Contrary to prior art, and with the primary goal of spatio-temporal action grouping, in this work only one single video segment is available for both unsupervised learning and analysis without any prior training information. After extracting simple features at a single spatio-temporal scale, we learn a dictionary for each individual in the video during each short time lapse. These dictionaries allow us to compare the individuals' actions by producing an affinity matrix which contains sufficient discriminative information about the actions in the scene leading to grouping with simple and efficient tools. With diverse publicly available real videos, we demonstrate the effectiveness of the proposed framework and its robustness to cluttered backgrounds, changes of human appearance, and action variability.