 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMACARONS: Mapping And Coverage Anticipation with RGB Online Self-Supervision
Mar 06, 2023



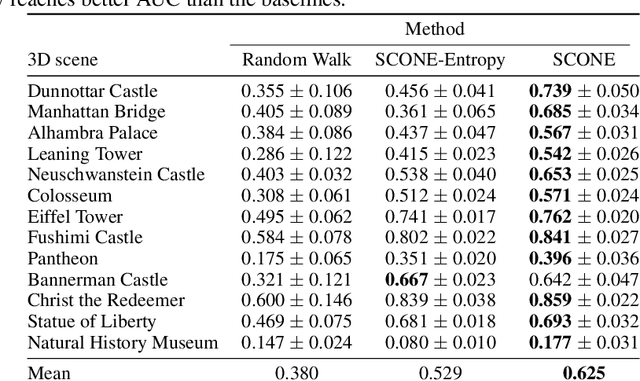
We introduce a method that simultaneously learns to explore new large environments and to reconstruct them in 3D from color images only. This is closely related to the Next Best View problem (NBV), where one has to identify where to move the camera next to improve the coverage of an unknown scene. However, most of the current NBV methods rely on depth sensors, need 3D supervision and/or do not scale to large scenes. Our method requires only a color camera and no 3D supervision. It simultaneously learns in a self-supervised fashion to predict a "volume occupancy field" from color images and, from this field, to predict the NBV. Thanks to this approach, our method performs well on new scenes as it is not biased towards any training 3D data. We demonstrate this on a recent dataset made of various 3D scenes and show it performs even better than recent methods requiring a depth sensor, which is not a realistic assumption for outdoor scenes captured with a flying drone.
SCONE: Surface Coverage Optimization in Unknown Environments by Volumetric Integration
Aug 22, 2022
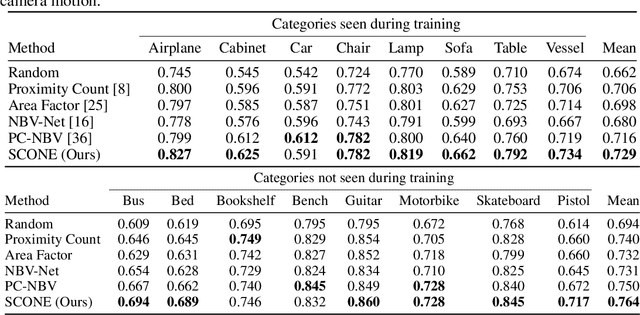
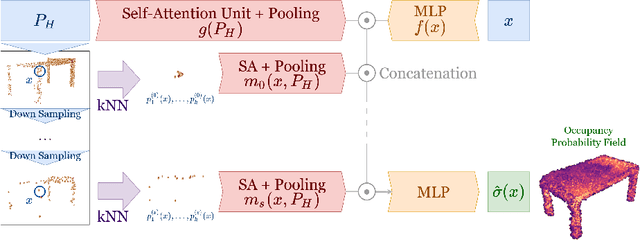
Next Best View computation (NBV) is a long-standing problem in robotics, and consists in identifying the next most informative sensor position(s) for reconstructing a 3D object or scene efficiently and accurately. Like most current methods, we consider NBV prediction from a depth sensor. Learning-based methods relying on a volumetric representation of the scene are suitable for path planning, but do not scale well with the size of the scene and have lower accuracy than methods using a surface-based representation. However, the latter constrain the camera to a small number of poses. To obtain the advantages of both representations, we show that we can maximize surface metrics by Monte Carlo integration over a volumetric representation. Our method scales to large scenes and handles free camera motion: It takes as input an arbitrarily large point cloud gathered by a depth sensor like Lidar systems as well as camera poses to predict NBV. We demonstrate our approach on a novel dataset made of large and complex 3D scenes.
Improving neural implicit surfaces geometry with patch warping
Dec 17, 2021
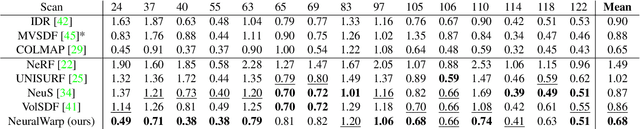


Neural implicit surfaces have become an important technique for multi-view 3D reconstruction but their accuracy remains limited. In this paper, we argue that this comes from the difficulty to learn and render high frequency textures with neural networks. We thus propose to add to the standard neural rendering optimization a direct photo-consistency term across the different views. Intuitively, we optimize the implicit geometry so that it warps views on each other in a consistent way. We demonstrate that two elements are key to the success of such an approach: (i) warping entire patches, using the predicted occupancy and normals of the 3D points along each ray, and measuring their similarity with a robust structural similarity (SSIM); (ii) handling visibility and occlusion in such a way that incorrect warps are not given too much importance while encouraging a reconstruction as complete as possible. We evaluate our approach, dubbed NeuralWarp, on the standard DTU and EPFL benchmarks and show it outperforms state of the art unsupervised implicit surfaces reconstructions by over 20% on both datasets.
Deep Multi-View Stereo gone wild
Apr 30, 2021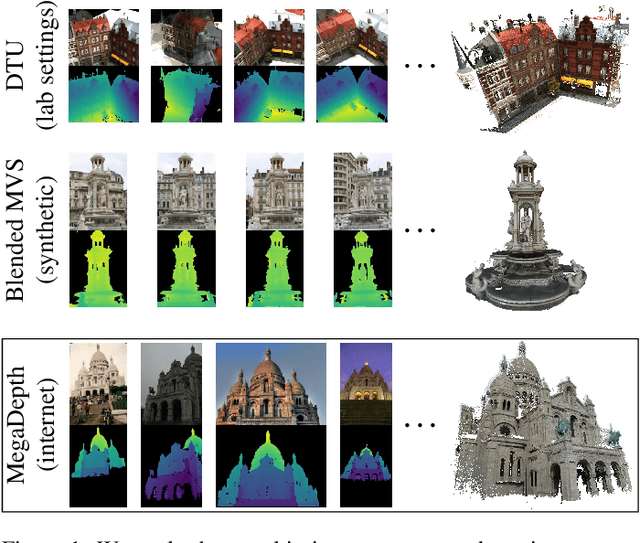
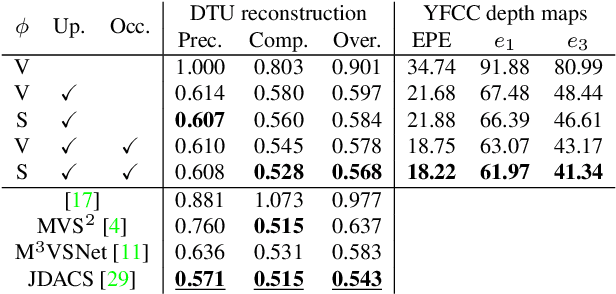
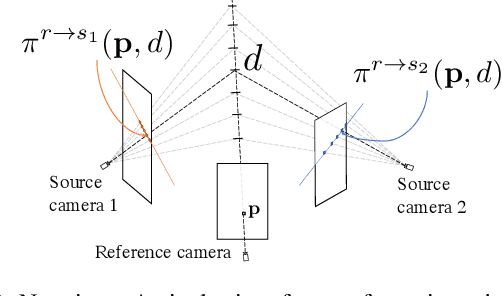
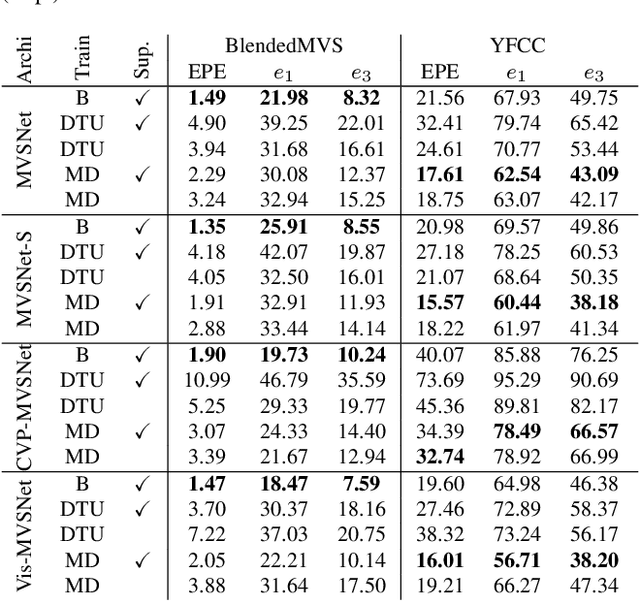
Deep multi-view stereo (deep MVS) methods have been developed and extensively compared on simple datasets, where they now outperform classical approaches. In this paper, we ask whether the conclusions reached in controlled scenarios are still valid when working with Internet photo collections. We propose a methodology for evaluation and explore the influence of three aspects of deep MVS methods: network architecture, training data, and supervision. We make several key observations, which we extensively validate quantitatively and qualitatively, both for depth prediction and complete 3D reconstructions. First, we outline the promises of unsupervised techniques by introducing a simple approach which provides more complete reconstructions than supervised options when using a simple network architecture. Second, we emphasize that not all multiscale architectures generalize to the unconstrained scenario, especially without supervision. Finally, we show the efficiency of noisy supervision from large-scale 3D reconstructions which can even lead to networks that outperform classical methods in scenarios where very few images are available.
Learning to Guide Local Feature Matches
Oct 21, 2020
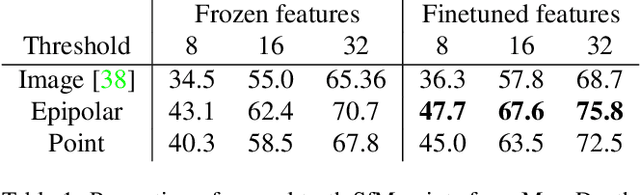
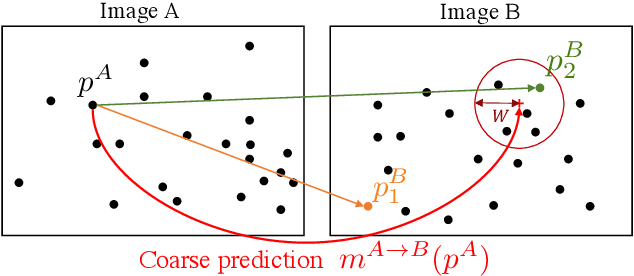
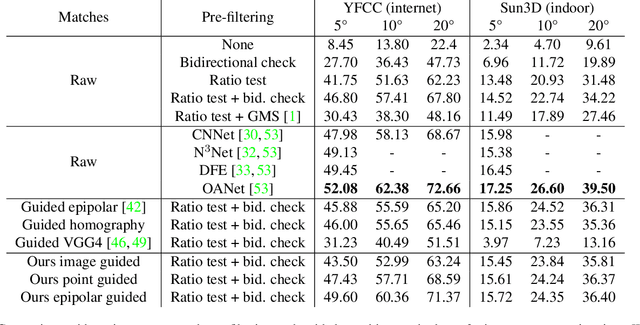
We tackle the problem of finding accurate and robust keypoint correspondences between images. We propose a learning-based approach to guide local feature matches via a learned approximate image matching. Our approach can boost the results of SIFT to a level similar to state-of-the-art deep descriptors, such as Superpoint, ContextDesc, or D2-Net and can improve performance for these descriptors. We introduce and study different levels of supervision to learn coarse correspondences. In particular, we show that weak supervision from epipolar geometry leads to performances higher than the stronger but more biased point level supervision and is a clear improvement over weak image level supervision. We demonstrate the benefits of our approach in a variety of conditions by evaluating our guided keypoint correspondences for localization of internet images on the YFCC100M dataset and indoor images on theSUN3D dataset, for robust localization on the Aachen day-night benchmark and for 3D reconstruction in challenging conditions using the LTLL historical image data.
Robust SfM with Little Image Overlap
Mar 28, 2017
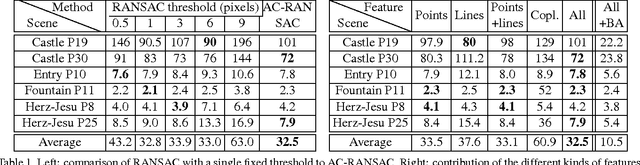
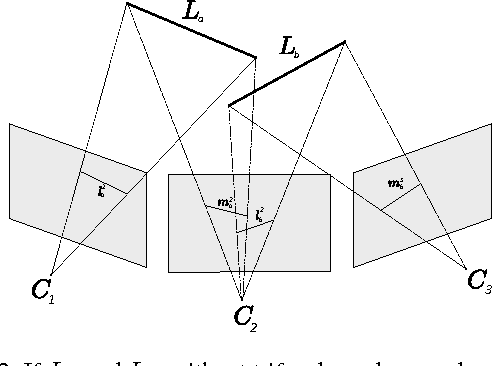
Usual Structure-from-Motion (SfM) techniques require at least trifocal overlaps to calibrate cameras and reconstruct a scene. We consider here scenarios of reduced image sets with little overlap, possibly as low as two images at most seeing the same part of the scene. We propose a new method, based on line coplanarity hypotheses, for estimating the relative scale of two independent bifocal calibrations sharing a camera, without the need of any trifocal information or Manhattan-world assumption. We use it to compute SfM in a chain of up-to-scale relative motions. For accuracy, we however also make use of trifocal information for line and/or point features, when present, relaxing usual trifocal constraints. For robustness to wrong assumptions and mismatches, we embed all constraints in a parameterless RANSAC-like approach. Experiments show that we can calibrate datasets that previously could not, and that this wider applicability does not come at the cost of inaccuracy.
High-precision camera distortion measurements with a "calibration harp"
Dec 22, 2012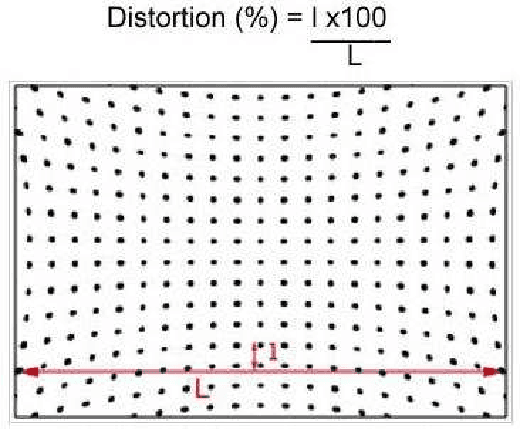



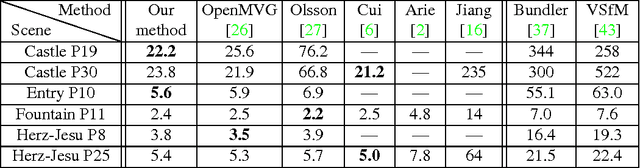
This paper addresses the high precision measurement of the distortion of a digital camera from photographs. Traditionally, this distortion is measured from photographs of a flat pattern which contains aligned elements. Nevertheless, it is nearly impossible to fabricate a very flat pattern and to validate its flatness. This fact limits the attainable measurable precisions. In contrast, it is much easier to obtain physically very precise straight lines by tightly stretching good quality strings on a frame. Taking literally "plumb-line methods", we built a "calibration harp" instead of the classic flat patterns to obtain a high precision measurement tool, demonstrably reaching 2/100 pixel precisions. The harp is complemented with the algorithms computing automatically from harp photographs two different and complementary lens distortion measurements. The precision of the method is evaluated on images corrected by state-of-the-art distortion correction algorithms, and by popular software. Three applications are shown: first an objective and reliable measurement of the result of any distortion correction. Second, the harp permits to control state-of-the art global camera calibration algorithms: It permits to select the right distortion model, thus avoiding internal compensation errors inherent to these methods. Third, the method replaces manual procedures in other distortion correction methods, makes them fully automatic, and increases their reliability and precision.