 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Gaussian Splatting
Apr 05, 2024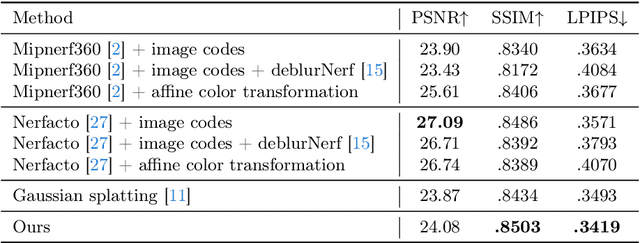

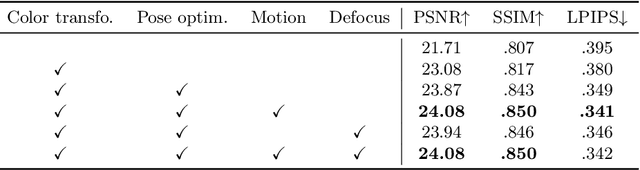

In this paper, we address common error sources for 3D Gaussian Splatting (3DGS) including blur, imperfect camera poses, and color inconsistencies, with the goal of improving its robustness for practical applications like reconstructions from handheld phone captures. Our main contribution involves modeling motion blur as a Gaussian distribution over camera poses, allowing us to address both camera pose refinement and motion blur correction in a unified way. Additionally, we propose mechanisms for defocus blur compensation and for addressing color in-consistencies caused by ambient light, shadows, or due to camera-related factors like varying white balancing settings. Our proposed solutions integrate in a seamless way with the 3DGS formulation while maintaining its benefits in terms of training efficiency and rendering speed. We experimentally validate our contributions on relevant benchmark datasets including Scannet++ and Deblur-NeRF, obtaining state-of-the-art results and thus consistent improvements over relevant baselines.
Improving neural implicit surfaces geometry with patch warping
Dec 17, 2021
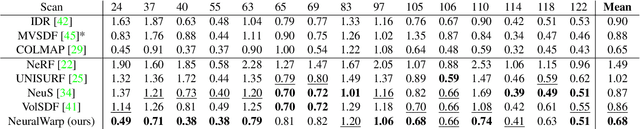


Neural implicit surfaces have become an important technique for multi-view 3D reconstruction but their accuracy remains limited. In this paper, we argue that this comes from the difficulty to learn and render high frequency textures with neural networks. We thus propose to add to the standard neural rendering optimization a direct photo-consistency term across the different views. Intuitively, we optimize the implicit geometry so that it warps views on each other in a consistent way. We demonstrate that two elements are key to the success of such an approach: (i) warping entire patches, using the predicted occupancy and normals of the 3D points along each ray, and measuring their similarity with a robust structural similarity (SSIM); (ii) handling visibility and occlusion in such a way that incorrect warps are not given too much importance while encouraging a reconstruction as complete as possible. We evaluate our approach, dubbed NeuralWarp, on the standard DTU and EPFL benchmarks and show it outperforms state of the art unsupervised implicit surfaces reconstructions by over 20% on both datasets.
Deep Multi-View Stereo gone wild
Apr 30, 2021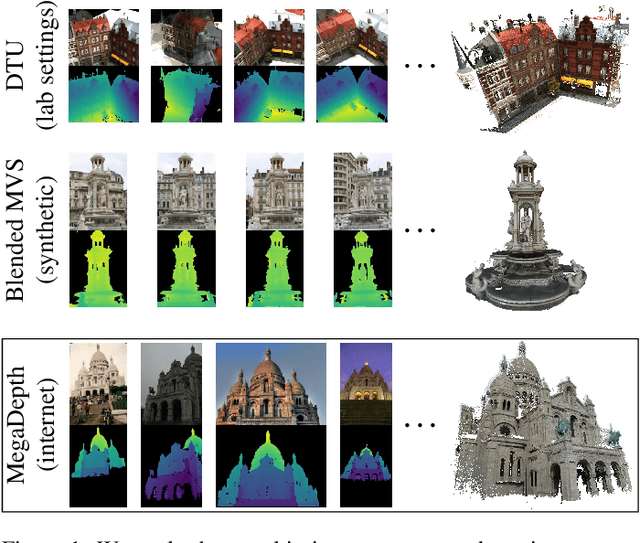
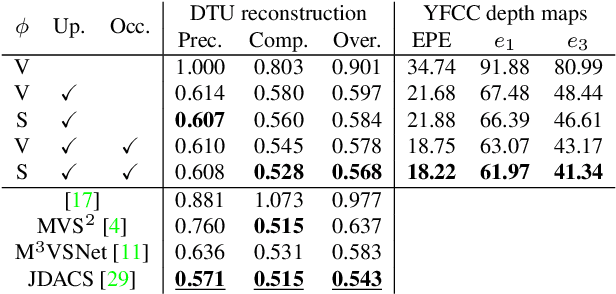
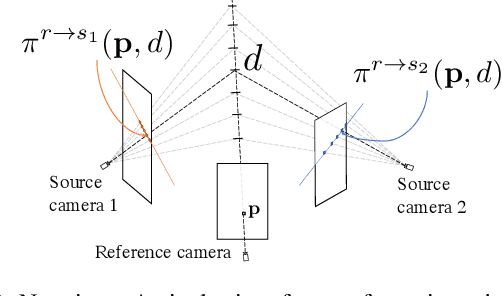
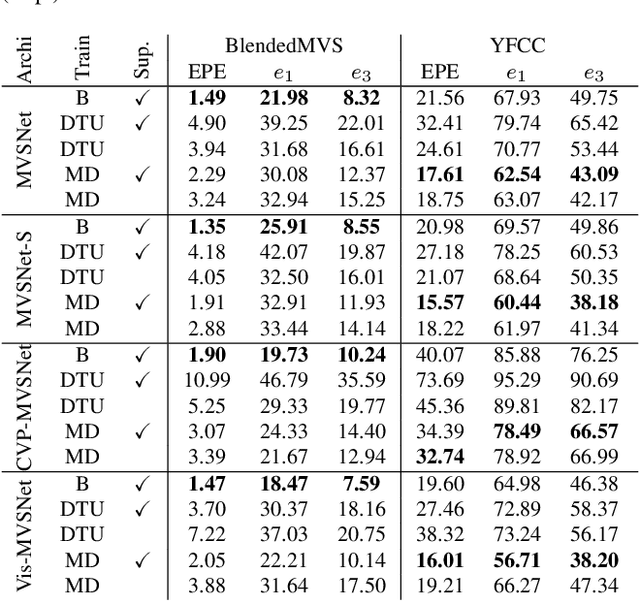
Deep multi-view stereo (deep MVS) methods have been developed and extensively compared on simple datasets, where they now outperform classical approaches. In this paper, we ask whether the conclusions reached in controlled scenarios are still valid when working with Internet photo collections. We propose a methodology for evaluation and explore the influence of three aspects of deep MVS methods: network architecture, training data, and supervision. We make several key observations, which we extensively validate quantitatively and qualitatively, both for depth prediction and complete 3D reconstructions. First, we outline the promises of unsupervised techniques by introducing a simple approach which provides more complete reconstructions than supervised options when using a simple network architecture. Second, we emphasize that not all multiscale architectures generalize to the unconstrained scenario, especially without supervision. Finally, we show the efficiency of noisy supervision from large-scale 3D reconstructions which can even lead to networks that outperform classical methods in scenarios where very few images are available.
Learning to Guide Local Feature Matches
Oct 21, 2020
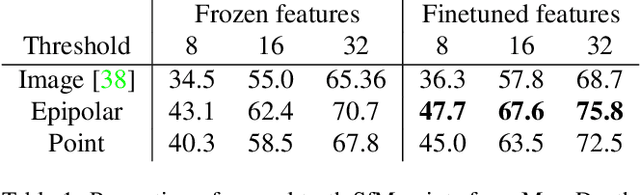
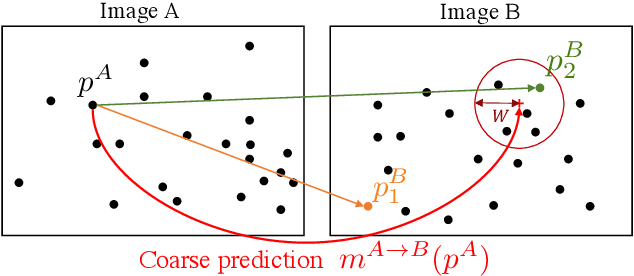
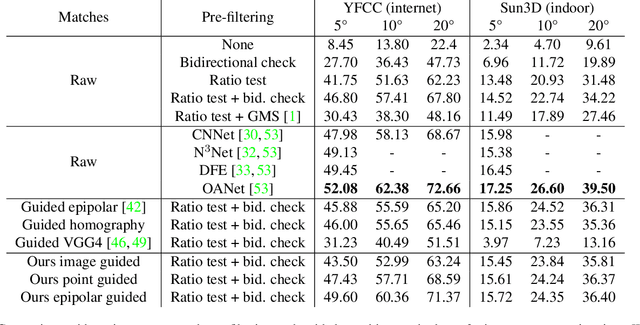
We tackle the problem of finding accurate and robust keypoint correspondences between images. We propose a learning-based approach to guide local feature matches via a learned approximate image matching. Our approach can boost the results of SIFT to a level similar to state-of-the-art deep descriptors, such as Superpoint, ContextDesc, or D2-Net and can improve performance for these descriptors. We introduce and study different levels of supervision to learn coarse correspondences. In particular, we show that weak supervision from epipolar geometry leads to performances higher than the stronger but more biased point level supervision and is a clear improvement over weak image level supervision. We demonstrate the benefits of our approach in a variety of conditions by evaluating our guided keypoint correspondences for localization of internet images on the YFCC100M dataset and indoor images on theSUN3D dataset, for robust localization on the Aachen day-night benchmark and for 3D reconstruction in challenging conditions using the LTLL historical image data.
RANSAC-Flow: generic two-stage image alignment
Apr 03, 2020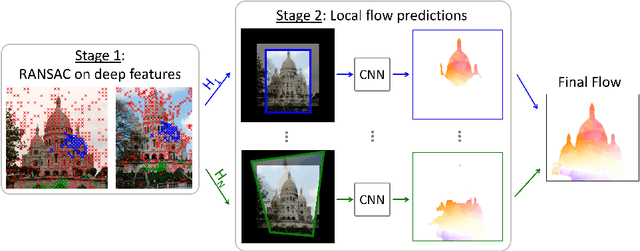
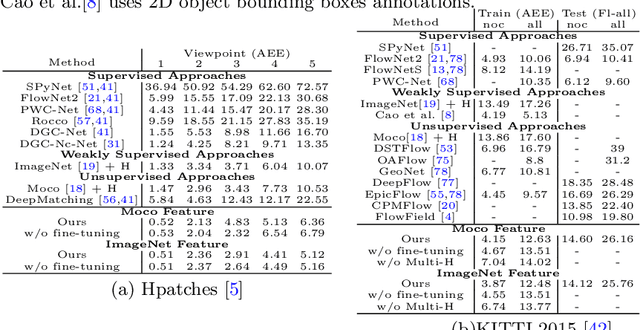

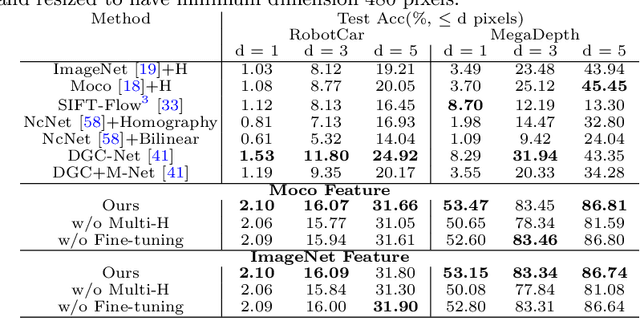
This paper considers the generic problem of dense alignment between two images, whether they be two frames of a video, two widely different views of a scene, two paintings depicting similar content, etc. Whereas each such task is typically addressed with a domain-specific solution, we show that a simple unsupervised approach performs surprisingly well across a range of tasks. Our main insight is that parametric and non-parametric alignment methods have complementary strengths. We propose a two-stage process: first, a feature-based parametric coarse alignment using one or more homographies, followed by non-parametric fine pixel-wise alignment. Coarse alignment is performed using RANSAC on off-the-shelf deep features. Fine alignment is learned in an unsupervised way by a deep network which optimizes a standard structural similarity metric (SSIM) between the two images, plus cycle-consistency. Despite its simplicity, our method shows competitive results on a range of tasks and datasets, including unsupervised optical flow on KITTI, dense correspondences on Hpatches, two-view geometry estimation on YFCC100M, localization on Aachen Day-Night, and, for the first time, fine alignment of artworks on the Brughel dataset. Our code and data are available at http://imagine.enpc.fr/~shenx/RANSAC-Flow/