 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Multi-View Stereo gone wild
Paper and Code
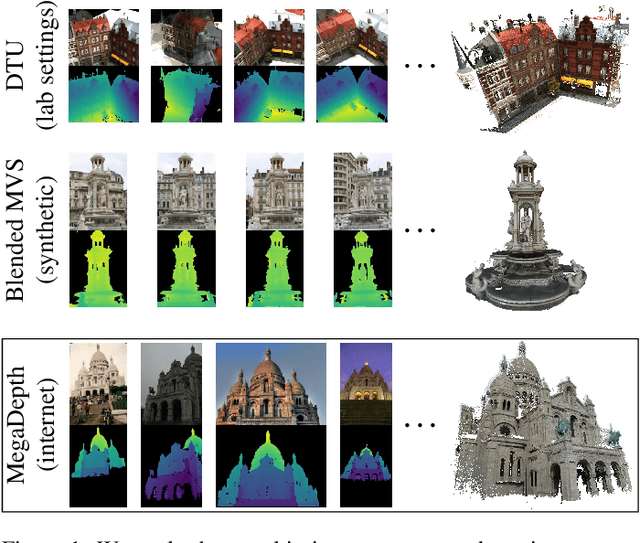
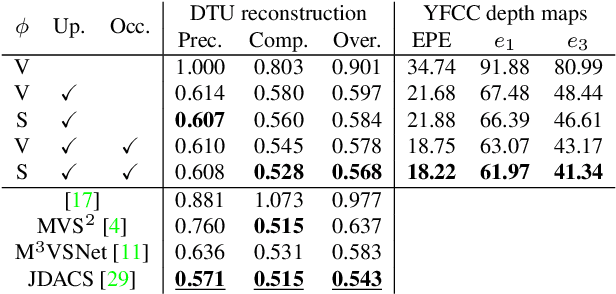
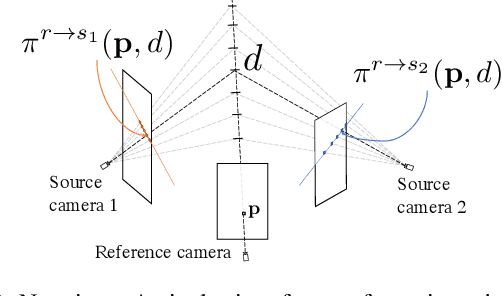
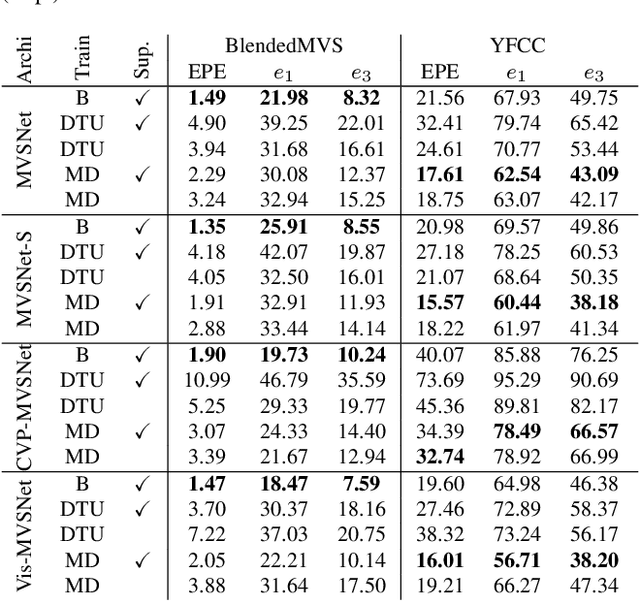
Deep multi-view stereo (deep MVS) methods have been developed and extensively compared on simple datasets, where they now outperform classical approaches. In this paper, we ask whether the conclusions reached in controlled scenarios are still valid when working with Internet photo collections. We propose a methodology for evaluation and explore the influence of three aspects of deep MVS methods: network architecture, training data, and supervision. We make several key observations, which we extensively validate quantitatively and qualitatively, both for depth prediction and complete 3D reconstructions. First, we outline the promises of unsupervised techniques by introducing a simple approach which provides more complete reconstructions than supervised options when using a simple network architecture. Second, we emphasize that not all multiscale architectures generalize to the unconstrained scenario, especially without supervision. Finally, we show the efficiency of noisy supervision from large-scale 3D reconstructions which can even lead to networks that outperform classical methods in scenarios where very few images are available.