 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2P: Improving Visual Foundation Models with Mask-to-Point Weakly-Supervised Learning for Dense Point Tracking
Mar 18, 2026Tracking Any Point (TAP) has emerged as a fundamental tool for video understanding. Current approaches adapt Vision Foundation Models (VFMs) like DINOv2 via offline finetuning or test-time optimization. However, these VFMs rely on static image pre-training, which is inherently sub-optimal for capturing dense temporal correspondence in videos. To address this, we propose Mask-to-Point (M2P) learning, which leverages rich video object segmentation (VOS) mask annotations to improve VFMs for dense point tracking. Our M2P introduces three new mask-based constraints for weakly-supervised representation learning. First, we propose a local structure consistency loss, which leverages Procrustes analysis to model the cohesive motion of points lying within a local structure, achieving more reliable point-to-point matching learning. Second, we propose a mask label consistency (MLC) loss, which enforces that sampled foreground points strictly match foreground regions across frames. The proposed MLC loss can be regarded as a regularization, which stabilizes training and prevents convergence to trivial solutions. Finally, mask boundary constrain is applied to explicitly supervise boundary points. We show that our weaklysupervised M2P models significantly outperform baseline VFMs with efficient training by using only 3.6K VOS training videos. Notably, M2P achieves 12.8% and 14.6% performance gains over DINOv2-B/14 and DINOv3-B/16 on the TAP-Vid-DAVIS benchmark, respectively. Moreover, the proposed M2P models are used as pre-trained backbones for both test-time optimized and offline fine-tuned TAP tasks, demonstrating its potential to serve as general pre-trained models for point tracking. Code will be made publicly available upon acceptance.
Hiding in Plain Text: Detecting Concealed Jailbreaks via Activation Disentanglement
Feb 23, 2026Large language models (LLMs) remain vulnerable to jailbreak prompts that are fluent and semantically coherent, and therefore difficult to detect with standard heuristics. A particularly challenging failure mode occurs when an attacker tries to hide the malicious goal of their request by manipulating its framing to induce compliance. Because these attacks maintain malicious intent through a flexible presentation, defenses that rely on structural artifacts or goal-specific signatures can fail. Motivated by this, we introduce a self-supervised framework for disentangling semantic factor pairs in LLM activations at inference. We instantiate the framework for goal and framing and construct GoalFrameBench, a corpus of prompts with controlled goal and framing variations, which we use to train Representation Disentanglement on Activations (ReDAct) module to extract disentangled representations in a frozen LLM. We then propose FrameShield, an anomaly detector operating on the framing representations, which improves model-agnostic detection across multiple LLM families with minimal computational overhead. Theoretical guarantees for ReDAct and extensive empirical validations show that its disentanglement effectively powers FrameShield. Finally, we use disentanglement as an interpretability probe, revealing distinct profiles for goal and framing signals and positioning semantic disentanglement as a building block for both LLM safety and mechanistic interpretability.
Toward Accurate and Accessible Markerless Neuronavigation
Feb 04, 2026Neuronavigation is widely used in biomedical research and interventions to guide the precise placement of instruments around the head to support procedures such as transcranial magnetic stimulation. Traditional systems, however, rely on subject-mounted markers that require manual registration, may shift during procedures, and can cause discomfort. We introduce and evaluate markerless approaches that replace expensive hardware and physical markers with low-cost visible and infrared light cameras incorporating stereo and depth sensing combined with algorithmic modeling of the facial geometry. Validation with $50$ human subjects yielded a median tracking discrepancy of only $2.32$ mm and $2.01°$ for the best markerless algorithms compared to a conventional marker-based system, which indicates sufficient accuracy for transcranial magnetic stimulation and a substantial improvement over prior markerless results. The results suggest that integration of the data from the various camera sensors can improve the overall accuracy further. The proposed markerless neuronavigation methods can reduce setup cost and complexity, improve patient comfort, and expand access to neuronavigation in clinical and research settings.
Order-Aware Test-Time Adaptation: Leveraging Temporal Dynamics for Robust Streaming Inference
Jan 28, 2026Test-Time Adaptation (TTA) enables pre-trained models to adjust to distribution shift by learning from unlabeled test-time streams. However, existing methods typically treat these streams as independent samples, overlooking the supervisory signal inherent in temporal dynamics. To address this, we introduce Order-Aware Test-Time Adaptation (OATTA). We formulate test-time adaptation as a gradient-free recursive Bayesian estimation task, using a learned dynamic transition matrix as a temporal prior to refine the base model's predictions. To ensure safety in weakly structured streams, we introduce a likelihood-ratio gate (LLR) that reverts to the base predictor when temporal evidence is absent. OATTA is a lightweight, model-agnostic module that incurs negligible computational overhead. Extensive experiments across image classification, wearable and physiological signal analysis, and language sentiment analysis demonstrate its universality; OATTA consistently boosts established baselines, improving accuracy by up to 6.35%. Our findings establish that modeling temporal dynamics provides a critical, orthogonal signal beyond standard order-agnostic TTA approaches.
Chain-of-Image Generation: Toward Monitorable and Controllable Image Generation
Dec 09, 2025While state-of-the-art image generation models achieve remarkable visual quality, their internal generative processes remain a "black box." This opacity limits human observation and intervention, and poses a barrier to ensuring model reliability, safety, and control. Furthermore, their non-human-like workflows make them difficult for human observers to interpret. To address this, we introduce the Chain-of-Image Generation (CoIG) framework, which reframes image generation as a sequential, semantic process analogous to how humans create art. Similar to the advantages in monitorability and performance that Chain-of-Thought (CoT) brought to large language models (LLMs), CoIG can produce equivalent benefits in text-to-image generation. CoIG utilizes an LLM to decompose a complex prompt into a sequence of simple, step-by-step instructions. The image generation model then executes this plan by progressively generating and editing the image. Each step focuses on a single semantic entity, enabling direct monitoring. We formally assess this property using two novel metrics: CoIG Readability, which evaluates the clarity of each intermediate step via its corresponding output; and Causal Relevance, which quantifies the impact of each procedural step on the final generated image. We further show that our framework mitigates entity collapse by decomposing the complex generation task into simple subproblems, analogous to the procedural reasoning employed by CoT. Our experimental results indicate that CoIG substantially enhances quantitative monitorability while achieving competitive compositional robustness compared to established baseline models. The framework is model-agnostic and can be integrated with any image generation model.
Hybrid Modeling of Photoplethysmography for Non-invasive Monitoring of Cardiovascular Parameters
Nov 18, 2025Continuous cardiovascular monitoring can play a key role in precision health. However, some fundamental cardiac biomarkers of interest, including stroke volume and cardiac output, require invasive measurements, e.g., arterial pressure waveforms (APW). As a non-invasive alternative, photoplethysmography (PPG) measurements are routinely collected in hospital settings. Unfortunately, the prediction of key cardiac biomarkers from PPG instead of APW remains an open challenge, further complicated by the scarcity of annotated PPG measurements. As a solution, we propose a hybrid approach that uses hemodynamic simulations and unlabeled clinical data to estimate cardiovascular biomarkers directly from PPG signals. Our hybrid model combines a conditional variational autoencoder trained on paired PPG-APW data with a conditional density estimator of cardiac biomarkers trained on labeled simulated APW segments. As a key result, our experiments demonstrate that the proposed approach can detect fluctuations of cardiac output and stroke volume and outperform a supervised baseline in monitoring temporal changes in these biomarkers.
SPOT: Sparsification with Attention Dynamics via Token Relevance in Vision Transformers
Nov 13, 2025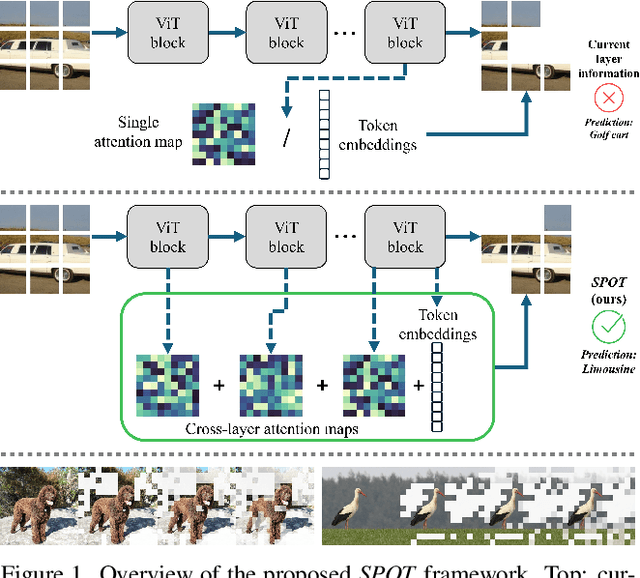
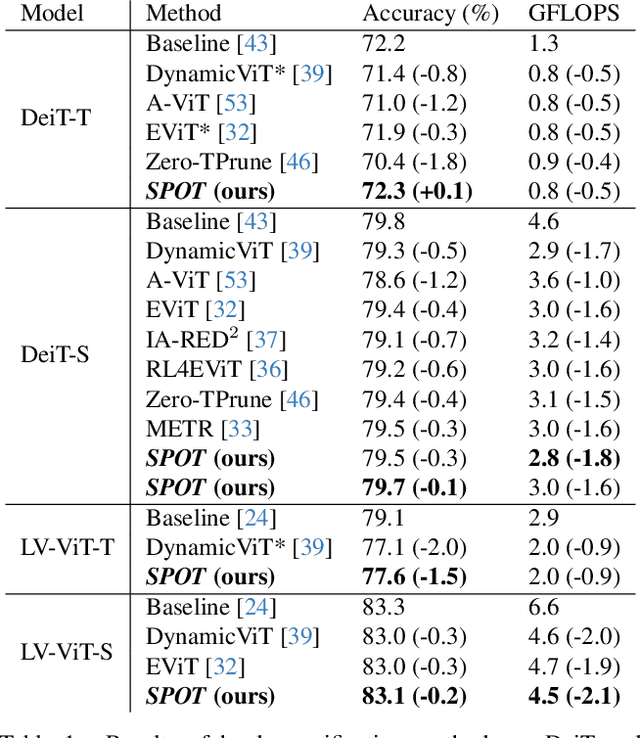
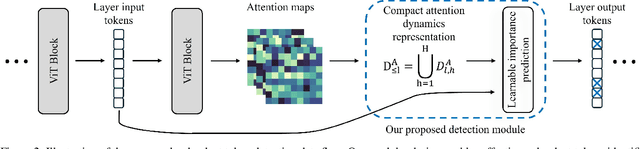

While Vision Transformers (ViT) have demonstrated remarkable performance across diverse tasks, their computational demands are substantial, scaling quadratically with the number of processed tokens. Compact attention representations, reflecting token interaction distributions, can guide early detection and reduction of less salient tokens prior to attention computation. Motivated by this, we present SParsification with attentiOn dynamics via Token relevance (SPOT), a framework for early detection of redundant tokens within ViTs that leverages token embeddings, interactions, and attention dynamics across layers to infer token importance, resulting in a more context-aware and interpretable relevance detection process. SPOT informs token sparsification and facilitates the elimination of such tokens, improving computational efficiency without sacrificing performance. SPOT employs computationally lightweight predictors that can be plugged into various ViT architectures and learn to derive effective input-specific token prioritization across layers. Its versatile design supports a range of performance levels adaptable to varying resource constraints. Empirical evaluations demonstrate significant efficiency gains of up to 40% compared to standard ViTs, while maintaining or even improving accuracy. Code and models are available at https://github.com/odedsc/SPOT .
Inferring Optical Tissue Properties from Photoplethysmography using Hybrid Amortized Inference
Oct 02, 2025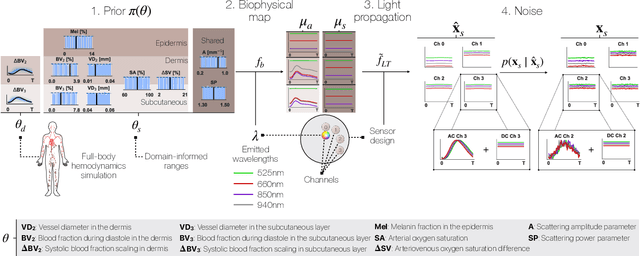
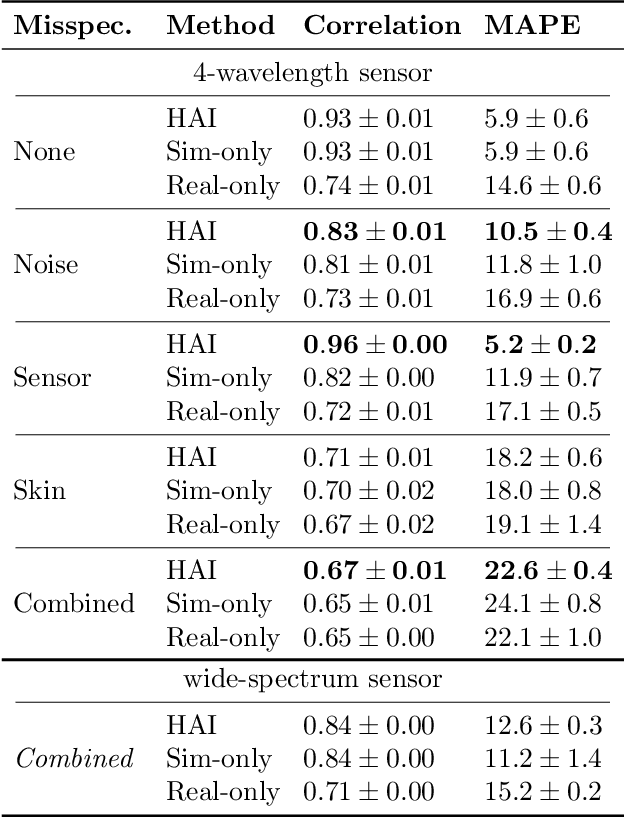
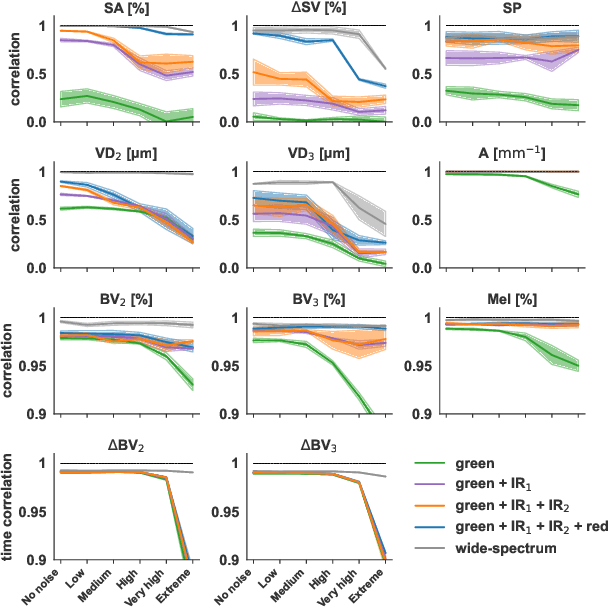

Smart wearables enable continuous tracking of established biomarkers such as heart rate, heart rate variability, and blood oxygen saturation via photoplethysmography (PPG). Beyond these metrics, PPG waveforms contain richer physiological information, as recent deep learning (DL) studies demonstrate. However, DL models often rely on features with unclear physiological meaning, creating a tension between predictive power, clinical interpretability, and sensor design. We address this gap by introducing PPGen, a biophysical model that relates PPG signals to interpretable physiological and optical parameters. Building on PPGen, we propose hybrid amortized inference (HAI), enabling fast, robust, and scalable estimation of relevant physiological parameters from PPG signals while correcting for model misspecification. In extensive in-silico experiments, we show that HAI can accurately infer physiological parameters under diverse noise and sensor conditions. Our results illustrate a path toward PPG models that retain the fidelity needed for DL-based features while supporting clinical interpretation and informed hardware design.
Leveraging Cardiovascular Simulations for In-Vivo Prediction of Cardiac Biomarkers
Dec 23, 2024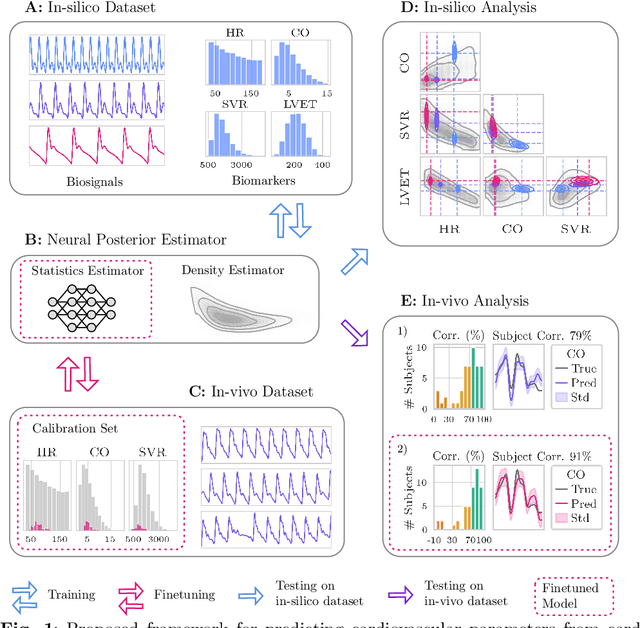
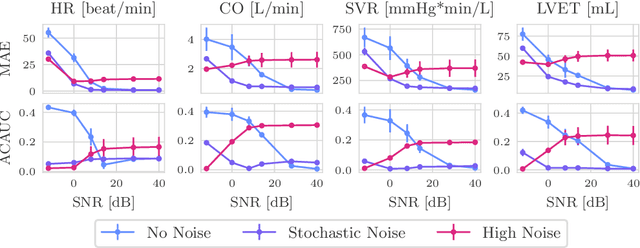
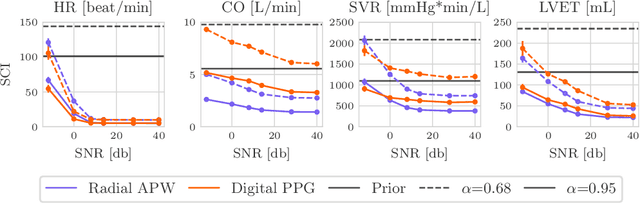
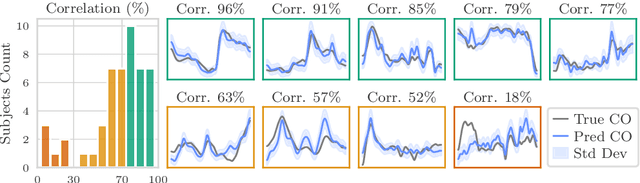
Whole-body hemodynamics simulators, which model blood flow and pressure waveforms as functions of physiological parameters, are now essential tools for studying cardiovascular systems. However, solving the corresponding inverse problem of mapping observations (e.g., arterial pressure waveforms at specific locations in the arterial network) back to plausible physiological parameters remains challenging. Leveraging recent advances in simulation-based inference, we cast this problem as statistical inference by training an amortized neural posterior estimator on a newly built large dataset of cardiac simulations that we publicly release. To better align simulated data with real-world measurements, we incorporate stochastic elements modeling exogenous effects. The proposed framework can further integrate in-vivo data sources to refine its predictive capabilities on real-world data. In silico, we demonstrate that the proposed framework enables finely quantifying uncertainty associated with individual measurements, allowing trustworthy prediction of four biomarkers of clinical interest--namely Heart Rate, Cardiac Output, Systemic Vascular Resistance, and Left Ventricular Ejection Time--from arterial pressure waveforms and photoplethysmograms. Furthermore, we validate the framework in vivo, where our method accurately captures temporal trends in CO and SVR monitoring on the VitalDB dataset. Finally, the predictive error made by the model monotonically increases with the predicted uncertainty, thereby directly supporting the automatic rejection of unusable measurements.
Autoregressive Models in Vision: A Survey
Nov 08, 2024
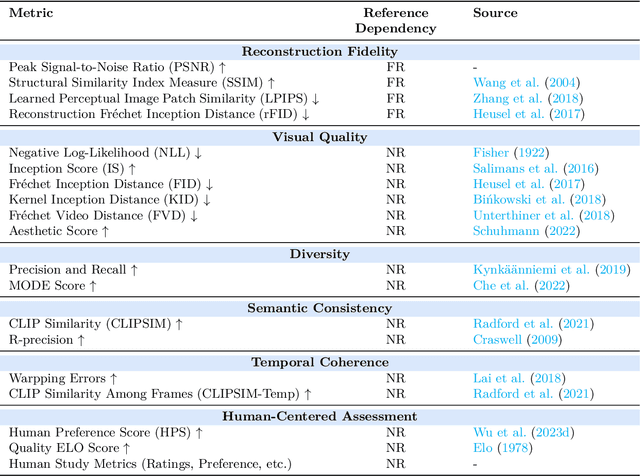

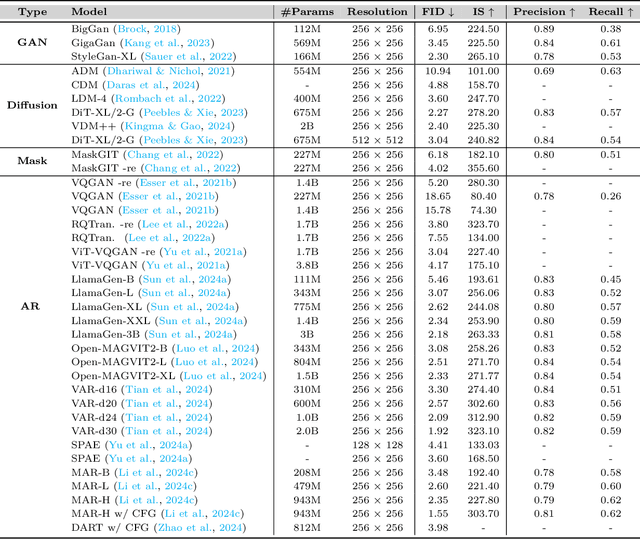
Autoregressive modeling has been a huge success in the field of natural language processing (NLP). Recently, autoregressive models have emerged as a significant area of focus in computer vision, where they excel in producing high-quality visual content. Autoregressive models in NLP typically operate on subword tokens. However, the representation strategy in computer vision can vary in different levels, \textit{i.e.}, pixel-level, token-level, or scale-level, reflecting the diverse and hierarchical nature of visual data compared to the sequential structure of language. This survey comprehensively examines the literature on autoregressive models applied to vision. To improve readability for researchers from diverse research backgrounds, we start with preliminary sequence representation and modeling in vision. Next, we divide the fundamental frameworks of visual autoregressive models into three general sub-categories, including pixel-based, token-based, and scale-based models based on the strategy of representation. We then explore the interconnections between autoregressive models and other generative models. Furthermore, we present a multi-faceted categorization of autoregressive models in computer vision, including image generation, video generation, 3D generation, and multi-modal generation. We also elaborate on their applications in diverse domains, including emerging domains such as embodied AI and 3D medical AI, with about 250 related references. Finally, we highlight the current challenges to autoregressive models in vision with suggestions about potential research directions. We have also set up a Github repository to organize the papers included in this survey at: \url{https://github.com/ChaofanTao/Autoregressive-Models-in-Vision-Survey}.