 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCultural Alignment in Large Language Models Using Soft Prompt Tuning
Mar 20, 2025Large Language Model (LLM) alignment conventionally relies on supervised fine-tuning or reinforcement learning based alignment frameworks. These methods typically require labeled or preference datasets and involve updating model weights to align the LLM with the training objective or reward model. Meanwhile, in social sciences such as cross-cultural studies, factor analysis is widely used to uncover underlying dimensions or latent variables that explain observed patterns in survey data. The non-differentiable nature of these measurements deriving from survey data renders the former alignment methods infeasible for alignment with cultural dimensions. To overcome this, we propose a parameter efficient strategy that combines soft prompt tuning, which freezes the model parameters while modifying the input prompt embeddings, with Differential Evolution (DE), a black-box optimization method for cases where a differentiable objective is unattainable. This strategy ensures alignment consistency without the need for preference data or model parameter updates, significantly enhancing efficiency and mitigating overfitting. Our method demonstrates significant improvements in LLama-3-8B-Instruct's cultural dimensions across multiple regions, outperforming both the Naive LLM and the In-context Learning (ICL) baseline, and effectively bridges computational models with human cultural nuances.
Neural Network for Blind Unmixing: a novel MatrixConv Unmixing (MCU) Approach
Mar 11, 2025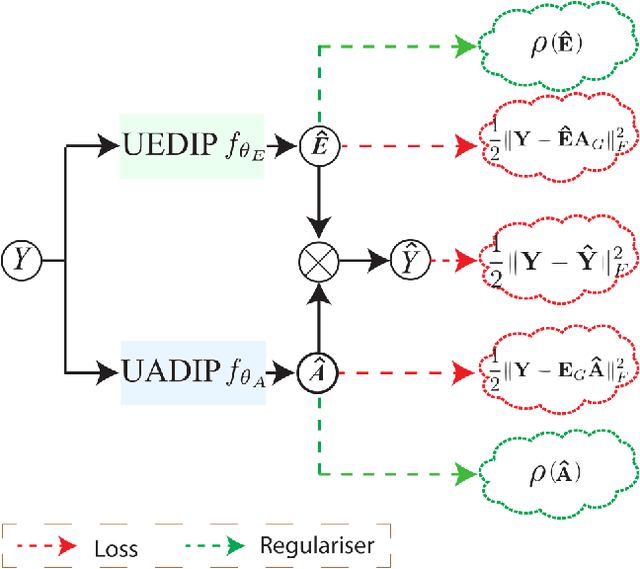
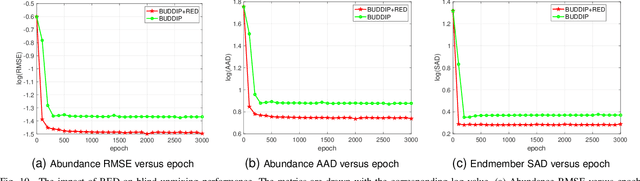
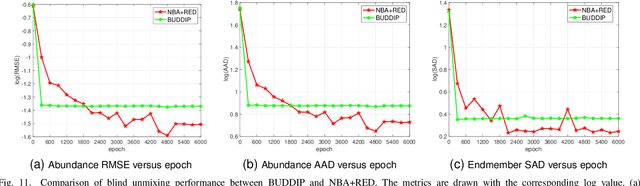
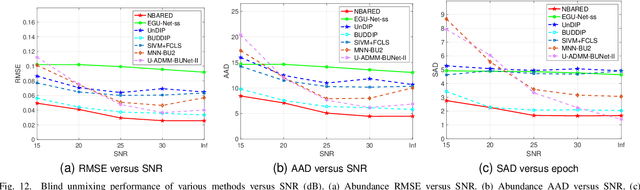
Hyperspectral image (HSI) unmixing is a challenging research problem that tries to identify the constituent components, known as endmembers, and their corresponding proportions, known as abundances, in the scene by analysing images captured by hyperspectral cameras. Recently, many deep learning based unmixing approaches have been proposed with the surge of machine learning techniques, especially convolutional neural networks (CNN). However, these methods face two notable challenges: 1. They frequently yield results lacking physical significance, such as signatures corresponding to unknown or non-existent materials. 2. CNNs, as general-purpose network structures, are not explicitly tailored for unmixing tasks. In response to these concerns, our work draws inspiration from double deep image prior (DIP) techniques and algorithm unrolling, presenting a novel network structure that effectively addresses both issues. Specifically, we first propose a MatrixConv Unmixing (MCU) approach for endmember and abundance estimation, respectively, which can be solved via certain iterative solvers. We then unroll these solvers to build two sub-networks, endmember estimation DIP (UEDIP) and abundance estimation DIP (UADIP), to generate the estimation of endmember and abundance, respectively. The overall network is constructed by assembling these two sub-networks. In order to generate meaningful unmixing results, we also propose a composite loss function. To further improve the unmixing quality, we also add explicitly a regularizer for endmember and abundance estimation, respectively. The proposed methods are tested for effectiveness on both synthetic and real datasets.
Deep Learning-Based Noninvasive Screening of Type 2 Diabetes with Chest X-ray Images and Electronic Health Records
Dec 14, 2024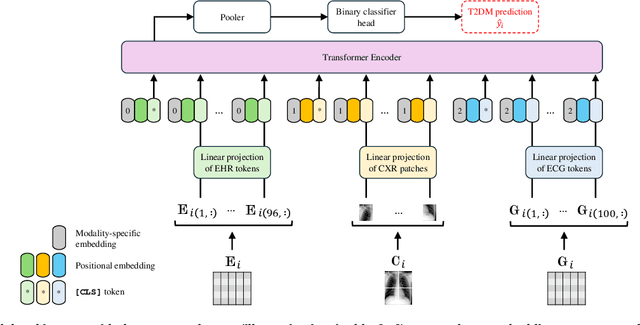



The imperative for early detection of type 2 diabetes mellitus (T2DM) is challenged by its asymptomatic onset and dependence on suboptimal clinical diagnostic tests, contributing to its widespread global prevalence. While research into noninvasive T2DM screening tools has advanced, conventional machine learning approaches remain limited to unimodal inputs due to extensive feature engineering requirements. In contrast, deep learning models can leverage multimodal data for a more holistic understanding of patients' health conditions. However, the potential of chest X-ray (CXR) imaging, one of the most commonly performed medical procedures, remains underexplored. This study evaluates the integration of CXR images with other noninvasive data sources, including electronic health records (EHRs) and electrocardiography signals, for T2DM detection. Utilising datasets meticulously compiled from the MIMIC-IV databases, we investigated two deep fusion paradigms: an early fusion-based multimodal transformer and a modular joint fusion ResNet-LSTM architecture. The end-to-end trained ResNet-LSTM model achieved an AUROC of 0.86, surpassing the CXR-only baseline by 2.3% with just 9863 training samples. These findings demonstrate the diagnostic value of CXRs within multimodal frameworks for identifying at-risk individuals early. Additionally, the dataset preprocessing pipeline has also been released to support further research in this domain.
Borrowing Treasures from Neighbors: In-Context Learning for Multimodal Learning with Missing Modalities and Data Scarcity
Mar 26, 2024Multimodal machine learning with missing modalities is an increasingly relevant challenge arising in various applications such as healthcare. This paper extends the current research into missing modalities to the low-data regime, i.e., a downstream task has both missing modalities and limited sample size issues. This problem setting is particularly challenging and also practical as it is often expensive to get full-modality data and sufficient annotated training samples. We propose to use retrieval-augmented in-context learning to address these two crucial issues by unleashing the potential of a transformer's in-context learning ability. Diverging from existing methods, which primarily belong to the parametric paradigm and often require sufficient training samples, our work exploits the value of the available full-modality data, offering a novel perspective on resolving the challenge. The proposed data-dependent framework exhibits a higher degree of sample efficiency and is empirically demonstrated to enhance the classification model's performance on both full- and missing-modality data in the low-data regime across various multimodal learning tasks. When only 1% of the training data are available, our proposed method demonstrates an average improvement of 6.1% over a recent strong baseline across various datasets and missing states. Notably, our method also reduces the performance gap between full-modality and missing-modality data compared with the baseline.
Federated Fairness without Access to Sensitive Groups
Feb 22, 2024Current approaches to group fairness in federated learning assume the existence of predefined and labeled sensitive groups during training. However, due to factors ranging from emerging regulations to dynamics and location-dependency of protected groups, this assumption may be unsuitable in many real-world scenarios. In this work, we propose a new approach to guarantee group fairness that does not rely on any predefined definition of sensitive groups or additional labels. Our objective allows the federation to learn a Pareto efficient global model ensuring worst-case group fairness and it enables, via a single hyper-parameter, trade-offs between fairness and utility, subject only to a group size constraint. This implies that any sufficiently large subset of the population is guaranteed to receive at least a minimum level of utility performance from the model. The proposed objective encompasses existing approaches as special cases, such as empirical risk minimization and subgroup robustness objectives from centralized machine learning. We provide an algorithm to solve this problem in federation that enjoys convergence and excess risk guarantees. Our empirical results indicate that the proposed approach can effectively improve the worst-performing group that may be present without unnecessarily hurting the average performance, exhibits superior or comparable performance to relevant baselines, and achieves a large set of solutions with different fairness-utility trade-offs.
SAE: Single Architecture Ensemble Neural Networks
Feb 09, 2024Ensembles of separate neural networks (NNs) have shown superior accuracy and confidence calibration over single NN across tasks. Recent methods compress ensembles within a single network via early exits or multi-input multi-output frameworks. However, the landscape of these methods is fragmented thus far, making it difficult to choose the right approach for a given task. Furthermore, the algorithmic performance of these methods is behind the ensemble of separate NNs and requires extensive architecture tuning. We propose a novel methodology unifying these approaches into a Single Architecture Ensemble (SAE). Our method learns the optimal number and depth of exits per ensemble input in a single NN. This enables the SAE framework to flexibly tailor its configuration for a given architecture or application. We evaluate SAEs on image classification and regression across various network architecture types and sizes. We demonstrate competitive accuracy or confidence calibration to baselines while reducing the compute operations or parameter count by up to $1.5{\sim}3.7\times$.
YAMLE: Yet Another Machine Learning Environment
Feb 09, 2024YAMLE: Yet Another Machine Learning Environment is an open-source framework that facilitates rapid prototyping and experimentation with machine learning (ML) models and methods. The key motivation is to reduce repetitive work when implementing new approaches and improve reproducibility in ML research. YAMLE includes a command-line interface and integrations with popular and well-maintained PyTorch-based libraries to streamline training, hyperparameter optimisation, and logging. The ambition for YAMLE is to grow into a shared ecosystem where researchers and practitioners can quickly build on and compare existing implementations. Find it at: https://github.com/martinferianc/yamle.
PROSAC: Provably Safe Certification for Machine Learning Models under Adversarial Attacks
Feb 04, 2024It is widely known that state-of-the-art machine learning models, including vision and language models, can be seriously compromised by adversarial perturbations. It is therefore increasingly relevant to develop capabilities to certify their performance in the presence of the most effective adversarial attacks. Our paper offers a new approach to certify the performance of machine learning models in the presence of adversarial attacks with population level risk guarantees. In particular, we introduce the notion of $(\alpha,\zeta)$ machine learning model safety. We propose a hypothesis testing procedure, based on the availability of a calibration set, to derive statistical guarantees providing that the probability of declaring that the adversarial (population) risk of a machine learning model is less than $\alpha$ (i.e. the model is safe), while the model is in fact unsafe (i.e. the model adversarial population risk is higher than $\alpha$), is less than $\zeta$. We also propose Bayesian optimization algorithms to determine efficiently whether a machine learning model is $(\alpha,\zeta)$-safe in the presence of an adversarial attack, along with statistical guarantees. We apply our framework to a range of machine learning models including various sizes of vision Transformer (ViT) and ResNet models impaired by a variety of adversarial attacks, such as AutoAttack, SquareAttack and natural evolution strategy attack, to illustrate the operation of our approach. Importantly, we show that ViT's are generally more robust to adversarial attacks than ResNets, and ViT-large is more robust than smaller models. Our approach goes beyond existing empirical adversarial risk-based certification guarantees. It formulates rigorous (and provable) performance guarantees that can be used to satisfy regulatory requirements mandating the use of state-of-the-art technical tools.
HgbNet: predicting hemoglobin level/anemia degree from EHR data
Jan 22, 2024Anemia is a prevalent medical condition that typically requires invasive blood tests for diagnosis and monitoring. Electronic health records (EHRs) have emerged as valuable data sources for numerous medical studies. EHR-based hemoglobin level/anemia degree prediction is non-invasive and rapid but still faces some challenges due to the fact that EHR data is typically an irregular multivariate time series containing a significant number of missing values and irregular time intervals. To address these issues, we introduce HgbNet, a machine learning-based prediction model that emulates clinicians' decision-making processes for hemoglobin level/anemia degree prediction. The model incorporates a NanDense layer with a missing indicator to handle missing values and employs attention mechanisms to account for both local irregularity and global irregularity. We evaluate the proposed method using two real-world datasets across two use cases. In our first use case, we predict hemoglobin level/anemia degree at moment T+1 by utilizing records from moments prior to T+1. In our second use case, we integrate all historical records with additional selected test results at moment T+1 to predict hemoglobin level/anemia degree at the same moment, T+1. HgbNet outperforms the best baseline results across all datasets and use cases. These findings demonstrate the feasibility of estimating hemoglobin levels and anemia degree from EHR data, positioning HgbNet as an effective non-invasive anemia diagnosis solution that could potentially enhance the quality of life for millions of affected individuals worldwide. To our knowledge, HgbNet is the first machine learning model leveraging EHR data for hemoglobin level/anemia degree prediction.
Impact of Noise on Calibration and Generalisation of Neural Networks
Jun 30, 2023



Noise injection and data augmentation strategies have been effective for enhancing the generalisation and robustness of neural networks (NNs). Certain types of noise such as label smoothing and MixUp have also been shown to improve calibration. Since noise can be added in various stages of the NN's training, it motivates the question of when and where the noise is the most effective. We study a variety of noise types to determine how much they improve calibration and generalisation, and under what conditions. More specifically we evaluate various noise-injection strategies in both in-distribution (ID) and out-of-distribution (OOD) scenarios. The findings highlight that activation noise was the most transferable and effective in improving generalisation, while input augmentation noise was prominent in improving calibration on OOD but not necessarily ID data.