 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCultural Alignment in Large Language Models Using Soft Prompt Tuning
Mar 20, 2025Large Language Model (LLM) alignment conventionally relies on supervised fine-tuning or reinforcement learning based alignment frameworks. These methods typically require labeled or preference datasets and involve updating model weights to align the LLM with the training objective or reward model. Meanwhile, in social sciences such as cross-cultural studies, factor analysis is widely used to uncover underlying dimensions or latent variables that explain observed patterns in survey data. The non-differentiable nature of these measurements deriving from survey data renders the former alignment methods infeasible for alignment with cultural dimensions. To overcome this, we propose a parameter efficient strategy that combines soft prompt tuning, which freezes the model parameters while modifying the input prompt embeddings, with Differential Evolution (DE), a black-box optimization method for cases where a differentiable objective is unattainable. This strategy ensures alignment consistency without the need for preference data or model parameter updates, significantly enhancing efficiency and mitigating overfitting. Our method demonstrates significant improvements in LLama-3-8B-Instruct's cultural dimensions across multiple regions, outperforming both the Naive LLM and the In-context Learning (ICL) baseline, and effectively bridges computational models with human cultural nuances.
Enhancing Dropout-based Bayesian Neural Networks with Multi-Exit on FPGA
Jun 24, 2024Reliable uncertainty estimation plays a crucial role in various safety-critical applications such as medical diagnosis and autonomous driving. In recent years, Bayesian neural networks (BayesNNs) have gained substantial research and industrial interests due to their capability to make accurate predictions with reliable uncertainty estimation. However, the algorithmic complexity and the resulting hardware performance of BayesNNs hinder their adoption in real-life applications. To bridge this gap, this paper proposes an algorithm and hardware co-design framework that can generate field-programmable gate array (FPGA)-based accelerators for efficient BayesNNs. At the algorithm level, we propose novel multi-exit dropout-based BayesNNs with reduced computational and memory overheads while achieving high accuracy and quality of uncertainty estimation. At the hardware level, this paper introduces a transformation framework that can generate FPGA-based accelerators for the proposed efficient multi-exit BayesNNs. Several optimization techniques such as the mix of spatial and temporal mappings are introduced to reduce resource consumption and improve the overall hardware performance. Comprehensive experiments demonstrate that our approach can achieve higher energy efficiency compared to CPU, GPU, and other state-of-the-art hardware implementations. To support the future development of this research, we have open-sourced our code at: https://github.com/os-hxfan/MCME_FPGA_Acc.git
Large language models surpass human experts in predicting neuroscience results
Mar 14, 2024Scientific discoveries often hinge on synthesizing decades of research, a task that potentially outstrips human information processing capacities. Large language models (LLMs) offer a solution. LLMs trained on the vast scientific literature could potentially integrate noisy yet interrelated findings to forecast novel results better than human experts. To evaluate this possibility, we created BrainBench, a forward-looking benchmark for predicting neuroscience results. We find that LLMs surpass experts in predicting experimental outcomes. BrainGPT, an LLM we tuned on the neuroscience literature, performed better yet. Like human experts, when LLMs were confident in their predictions, they were more likely to be correct, which presages a future where humans and LLMs team together to make discoveries. Our approach is not neuroscience-specific and is transferable to other knowledge-intensive endeavors.
YAMLE: Yet Another Machine Learning Environment
Feb 09, 2024YAMLE: Yet Another Machine Learning Environment is an open-source framework that facilitates rapid prototyping and experimentation with machine learning (ML) models and methods. The key motivation is to reduce repetitive work when implementing new approaches and improve reproducibility in ML research. YAMLE includes a command-line interface and integrations with popular and well-maintained PyTorch-based libraries to streamline training, hyperparameter optimisation, and logging. The ambition for YAMLE is to grow into a shared ecosystem where researchers and practitioners can quickly build on and compare existing implementations. Find it at: https://github.com/martinferianc/yamle.
SAE: Single Architecture Ensemble Neural Networks
Feb 09, 2024Ensembles of separate neural networks (NNs) have shown superior accuracy and confidence calibration over single NN across tasks. Recent methods compress ensembles within a single network via early exits or multi-input multi-output frameworks. However, the landscape of these methods is fragmented thus far, making it difficult to choose the right approach for a given task. Furthermore, the algorithmic performance of these methods is behind the ensemble of separate NNs and requires extensive architecture tuning. We propose a novel methodology unifying these approaches into a Single Architecture Ensemble (SAE). Our method learns the optimal number and depth of exits per ensemble input in a single NN. This enables the SAE framework to flexibly tailor its configuration for a given architecture or application. We evaluate SAEs on image classification and regression across various network architecture types and sizes. We demonstrate competitive accuracy or confidence calibration to baselines while reducing the compute operations or parameter count by up to $1.5{\sim}3.7\times$.
Impact of Noise on Calibration and Generalisation of Neural Networks
Jun 30, 2023



Noise injection and data augmentation strategies have been effective for enhancing the generalisation and robustness of neural networks (NNs). Certain types of noise such as label smoothing and MixUp have also been shown to improve calibration. Since noise can be added in various stages of the NN's training, it motivates the question of when and where the noise is the most effective. We study a variety of noise types to determine how much they improve calibration and generalisation, and under what conditions. More specifically we evaluate various noise-injection strategies in both in-distribution (ID) and out-of-distribution (OOD) scenarios. The findings highlight that activation noise was the most transferable and effective in improving generalisation, while input augmentation noise was prominent in improving calibration on OOD but not necessarily ID data.
Renate: A Library for Real-World Continual Learning
Apr 24, 2023


Continual learning enables the incremental training of machine learning models on non-stationary data streams.While academic interest in the topic is high, there is little indication of the use of state-of-the-art continual learning algorithms in practical machine learning deployment. This paper presents Renate, a continual learning library designed to build real-world updating pipelines for PyTorch models. We discuss requirements for the use of continual learning algorithms in practice, from which we derive design principles for Renate. We give a high-level description of the library components and interfaces. Finally, we showcase the strengths of the library by presenting experimental results. Renate may be found at https://github.com/awslabs/renate.
Simple Regularisation for Uncertainty-Aware Knowledge Distillation
May 19, 2022
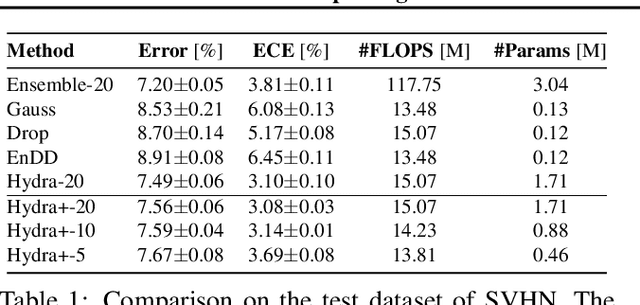


Considering uncertainty estimation of modern neural networks (NNs) is one of the most important steps towards deploying machine learning systems to meaningful real-world applications such as in medicine, finance or autonomous systems. At the moment, ensembles of different NNs constitute the state-of-the-art in both accuracy and uncertainty estimation in different tasks. However, ensembles of NNs are unpractical under real-world constraints, since their computation and memory consumption scale linearly with the size of the ensemble, which increase their latency and deployment cost. In this work, we examine a simple regularisation approach for distribution-free knowledge distillation of ensemble of machine learning models into a single NN. The aim of the regularisation is to preserve the diversity, accuracy and uncertainty estimation characteristics of the original ensemble without any intricacies, such as fine-tuning. We demonstrate the generality of the approach on combinations of toy data, SVHN/CIFAR-10, simple to complex NN architectures and different tasks.
On Causal Inference for Data-free Structured Pruning
Dec 19, 2021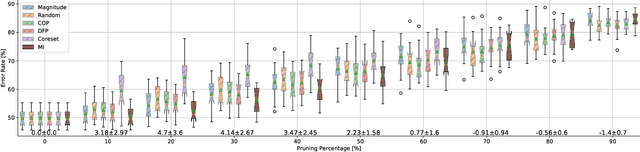
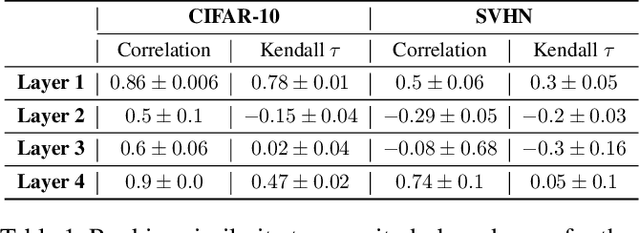
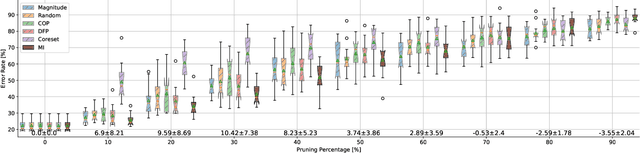

Neural networks (NNs) are making a large impact both on research and industry. Nevertheless, as NNs' accuracy increases, it is followed by an expansion in their size, required number of compute operations and energy consumption. Increase in resource consumption results in NNs' reduced adoption rate and real-world deployment impracticality. Therefore, NNs need to be compressed to make them available to a wider audience and at the same time decrease their runtime costs. In this work, we approach this challenge from a causal inference perspective, and we propose a scoring mechanism to facilitate structured pruning of NNs. The approach is based on measuring mutual information under a maximum entropy perturbation, sequentially propagated through the NN. We demonstrate the method's performance on two datasets and various NNs' sizes, and we show that our approach achieves competitive performance under challenging conditions.
Algorithm and Hardware Co-design for Reconfigurable CNN Accelerator
Nov 24, 2021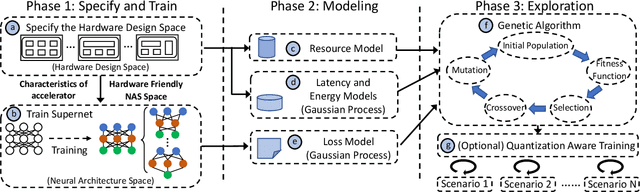
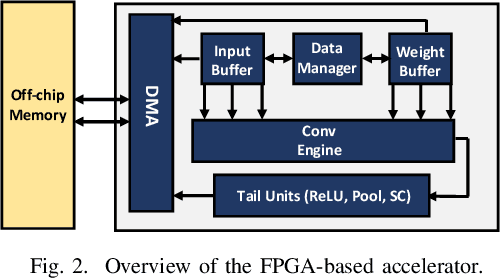
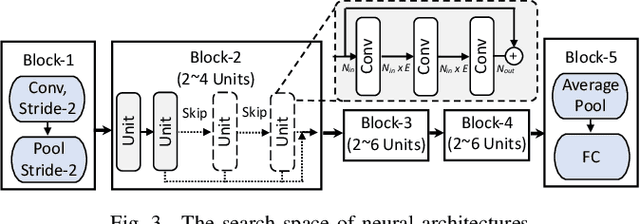
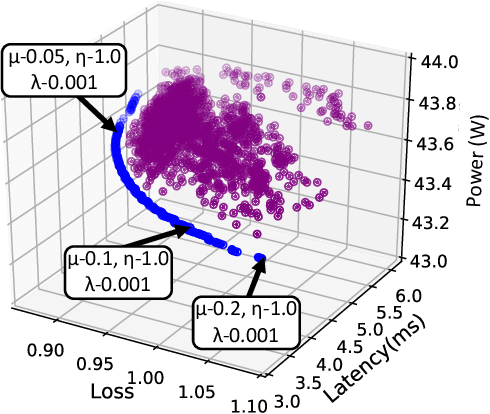
Recent advances in algorithm-hardware co-design for deep neural networks (DNNs) have demonstrated their potential in automatically designing neural architectures and hardware designs. Nevertheless, it is still a challenging optimization problem due to the expensive training cost and the time-consuming hardware implementation, which makes the exploration on the vast design space of neural architecture and hardware design intractable. In this paper, we demonstrate that our proposed approach is capable of locating designs on the Pareto frontier. This capability is enabled by a novel three-phase co-design framework, with the following new features: (a) decoupling DNN training from the design space exploration of hardware architecture and neural architecture, (b) providing a hardware-friendly neural architecture space by considering hardware characteristics in constructing the search cells, (c) adopting Gaussian process to predict accuracy, latency and power consumption to avoid time-consuming synthesis and place-and-route processes. In comparison with the manually-designed ResNet101, InceptionV2 and MobileNetV2, we can achieve up to 5% higher accuracy with up to 3x speed up on the ImageNet dataset. Compared with other state-of-the-art co-design frameworks, our found network and hardware configuration can achieve 2% ~ 6% higher accuracy, 2x ~ 26x smaller latency and 8.5x higher energy efficiency.