 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Dropout-based Bayesian Neural Networks with Multi-Exit on FPGA
Jun 24, 2024Reliable uncertainty estimation plays a crucial role in various safety-critical applications such as medical diagnosis and autonomous driving. In recent years, Bayesian neural networks (BayesNNs) have gained substantial research and industrial interests due to their capability to make accurate predictions with reliable uncertainty estimation. However, the algorithmic complexity and the resulting hardware performance of BayesNNs hinder their adoption in real-life applications. To bridge this gap, this paper proposes an algorithm and hardware co-design framework that can generate field-programmable gate array (FPGA)-based accelerators for efficient BayesNNs. At the algorithm level, we propose novel multi-exit dropout-based BayesNNs with reduced computational and memory overheads while achieving high accuracy and quality of uncertainty estimation. At the hardware level, this paper introduces a transformation framework that can generate FPGA-based accelerators for the proposed efficient multi-exit BayesNNs. Several optimization techniques such as the mix of spatial and temporal mappings are introduced to reduce resource consumption and improve the overall hardware performance. Comprehensive experiments demonstrate that our approach can achieve higher energy efficiency compared to CPU, GPU, and other state-of-the-art hardware implementations. To support the future development of this research, we have open-sourced our code at: https://github.com/os-hxfan/MCME_FPGA_Acc.git
Algorithm and Hardware Co-design for Reconfigurable CNN Accelerator
Nov 24, 2021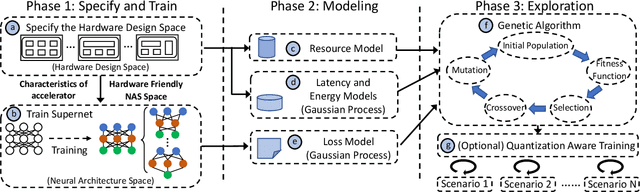
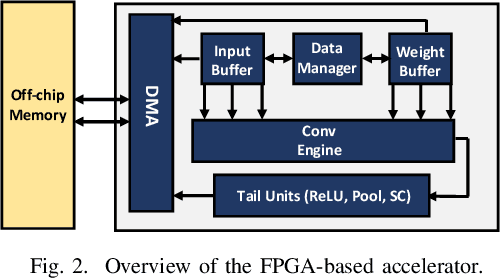
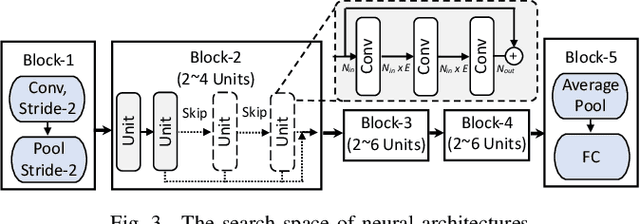
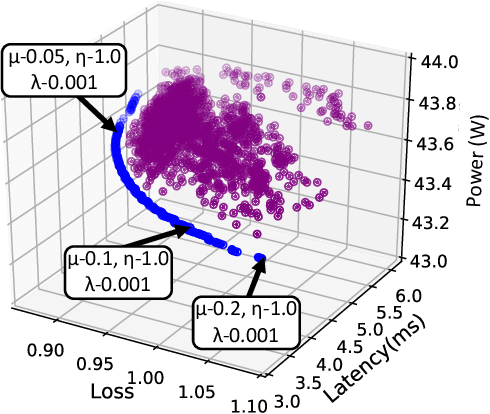
Recent advances in algorithm-hardware co-design for deep neural networks (DNNs) have demonstrated their potential in automatically designing neural architectures and hardware designs. Nevertheless, it is still a challenging optimization problem due to the expensive training cost and the time-consuming hardware implementation, which makes the exploration on the vast design space of neural architecture and hardware design intractable. In this paper, we demonstrate that our proposed approach is capable of locating designs on the Pareto frontier. This capability is enabled by a novel three-phase co-design framework, with the following new features: (a) decoupling DNN training from the design space exploration of hardware architecture and neural architecture, (b) providing a hardware-friendly neural architecture space by considering hardware characteristics in constructing the search cells, (c) adopting Gaussian process to predict accuracy, latency and power consumption to avoid time-consuming synthesis and place-and-route processes. In comparison with the manually-designed ResNet101, InceptionV2 and MobileNetV2, we can achieve up to 5% higher accuracy with up to 3x speed up on the ImageNet dataset. Compared with other state-of-the-art co-design frameworks, our found network and hardware configuration can achieve 2% ~ 6% higher accuracy, 2x ~ 26x smaller latency and 8.5x higher energy efficiency.
Optimizing CNN-based Hyperspectral ImageClassification on FPGAs
Jun 27, 2019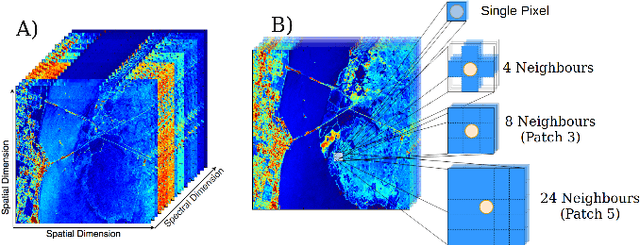
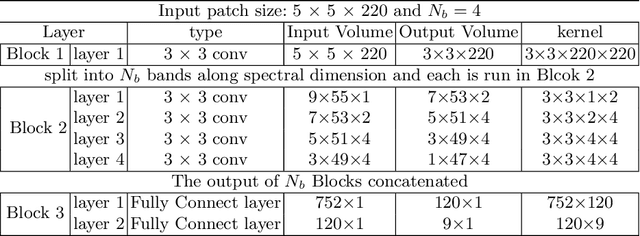
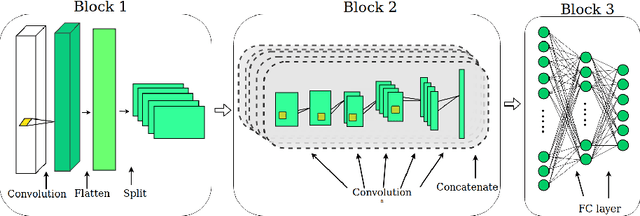
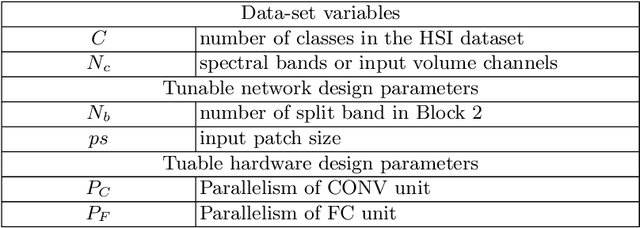
Hyperspectral image (HSI) classification has been widely adopted in applications involving remote sensing imagery analysis which require high classification accuracy and real-time processing speed. Methods based on Convolutional neural networks (CNNs) have been proven to achieve state-of-the-art accuracy in classifying HSIs. However, CNN models are often too computationally intensive to achieve real-time response due to the high dimensional nature of HSI, compared to traditional methods such as Support Vector Machines (SVMs). Besides, previous CNN models used in HSI are not specially designed for efficient implementation on embedded devices such as FPGAs. This paper proposes a novel CNN-based algorithm for HSI classification which takes into account hardware efficiency. A customized architecture which enables the proposed algorithm to be mapped effectively onto FPGA resources is then proposed to support real-time on-board classification with low power consumption. Implementation results show that our proposed accelerator on a Xilinx Zynq 706 FPGA board achieves more than 70x faster than an Intel 8-core Xeon CPU and 3x faster than an NVIDIA GeForce 1080 GPU. Compared to previous SVM-based FPGA accelerators, we achieve comparable processing speed but provide a much higher classification accuracy.