 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Expert Sharing: Decoupling Memory from Parallelism in Mixture-of-Experts Diffusion LLMs
Jan 31, 2026Among parallel decoding paradigms, diffusion large language models (dLLMs) have emerged as a promising candidate that balances generation quality and throughput. However, their integration with Mixture-of-Experts (MoE) architectures is constrained by an expert explosion: as the number of tokens generated in parallel increases, the number of distinct experts activated grows nearly linearly. This results in substantial memory traffic that pushes inference into a memory-bound regime, negating the efficiency gains of both MoE and parallel decoding. To address this challenge, we propose Dynamic Expert Sharing (DES), a novel technique that shifts MoE optimization from token-centric pruning and conventional expert skipping methods to sequence-level coreset selection. To maximize expert reuse, DES identifies a compact, high-utility set of experts to satisfy the requirements of an entire parallel decoding block. We introduce two innovative selection strategies: (1) Intra-Sequence Sharing (DES-Seq), which adapts optimal allocation to the sequence level, and (2) Saliency-Aware Voting (DES-Vote), a novel mechanism that allows tokens to collectively elect a coreset based on aggregated router weights. Extensive experiments on MoE dLLMs demonstrate that DES reduces unique expert activations by over 55% and latency by up to 38%, while retaining 99% of vanilla accuracy, effectively decoupling memory overhead from the degree of parallelism.
Rethinking Optimal Verification Granularity for Compute-Efficient Test-Time Scaling
May 16, 2025Test-time scaling (TTS) has proven effective in enhancing the reasoning capabilities of large language models (LLMs). Verification plays a key role in TTS, simultaneously influencing (1) reasoning performance and (2) compute efficiency, due to the quality and computational cost of verification. In this work, we challenge the conventional paradigms of verification, and make the first attempt toward systematically investigating the impact of verification granularity-that is, how frequently the verifier is invoked during generation, beyond verifying only the final output or individual generation steps. To this end, we introduce Variable Granularity Search (VG-Search), a unified algorithm that generalizes beam search and Best-of-N sampling via a tunable granularity parameter g. Extensive experiments with VG-Search under varying compute budgets, generator-verifier configurations, and task attributes reveal that dynamically selecting g can improve the compute efficiency and scaling behavior. Building on these findings, we propose adaptive VG-Search strategies that achieve accuracy gains of up to 3.1\% over Beam Search and 3.6\% over Best-of-N, while reducing FLOPs by over 52\%. We will open-source the code to support future research.
FW-Merging: Scaling Model Merging with Frank-Wolfe Optimization
Mar 16, 2025Model merging has emerged as a promising approach for multi-task learning (MTL), offering a data-efficient alternative to conventional fine-tuning. However, with the rapid development of the open-source AI ecosystem and the increasing availability of fine-tuned foundation models, existing model merging methods face two key limitations: (i) They are primarily designed for in-house fine-tuned models, making them less adaptable to diverse model sources with partially unknown model and task information, (ii) They struggle to scale effectively when merging numerous model checkpoints. To address these challenges, we formulate model merging as a constrained optimization problem and introduce a novel approach: Frank-Wolfe Merging (FW-Merging). Inspired by Frank-Wolfe optimization, our approach iteratively selects the most relevant model in the pool to minimize a linear approximation of the objective function and then executes a local merging similar to the Frank-Wolfe update. The objective function is designed to capture the desired behavior of the target-merged model, while the fine-tuned candidate models define the constraint set. More importantly, FW-Merging serves as an orthogonal technique for existing merging methods, seamlessly integrating with them to further enhance accuracy performance. Our experiments show that FW-Merging scales across diverse model sources, remaining stable with 16 irrelevant models and improving by 15.3% with 16 relevant models on 20 CV tasks, while maintaining constant memory overhead, unlike the linear overhead of data-informed merging methods. Compared with the state-of-the-art approaches, FW-Merging surpasses the data-free merging method by 32.8% and outperforms the data-informed Adamerging by 8.39% when merging 20 ViT models.
Progressive Mixed-Precision Decoding for Efficient LLM Inference
Oct 17, 2024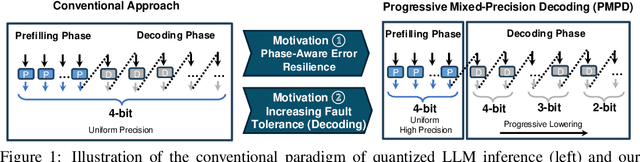
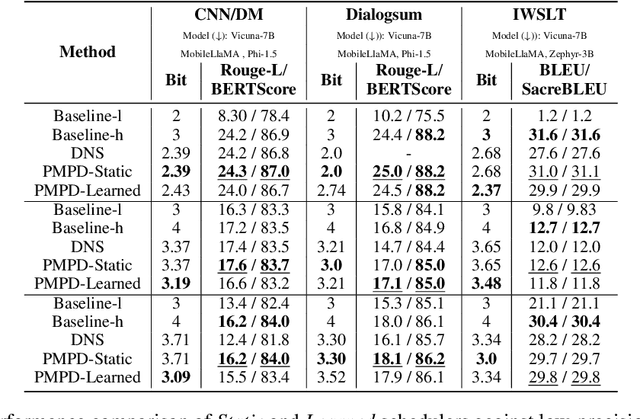
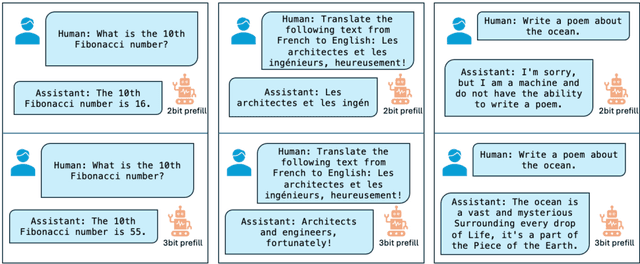
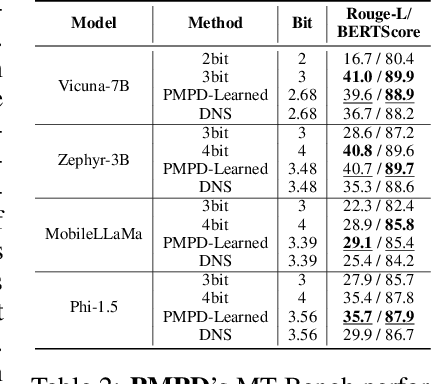
In spite of the great potential of large language models (LLMs) across various tasks, their deployment on resource-constrained devices remains challenging due to their excessive computational and memory demands. Quantization has emerged as an effective solution by storing weights in reduced precision. However, utilizing low precisions (i.e.~2/3-bit) to substantially alleviate the memory-boundedness of LLM decoding, still suffers from prohibitive performance drop. In this work, we argue that existing approaches fail to explore the diversity in computational patterns, redundancy, and sensitivity to approximations of the different phases of LLM inference, resorting to a uniform quantization policy throughout. Instead, we propose a novel phase-aware method that selectively allocates precision during different phases of LLM inference, achieving both strong context extraction during prefill and efficient memory bandwidth utilization during decoding. To further address the memory-boundedness of the decoding phase, we introduce Progressive Mixed-Precision Decoding (PMPD), a technique that enables the gradual lowering of precision deeper in the generated sequence, together with a spectrum of precision-switching schedulers that dynamically drive the precision-lowering decisions in either task-adaptive or prompt-adaptive manner. Extensive evaluation across diverse language tasks shows that when targeting Nvidia GPUs, PMPD achieves 1.4$-$12.2$\times$ speedup in matrix-vector multiplications over fp16 models, while when targeting an LLM-optimized NPU, our approach delivers a throughput gain of 3.8$-$8.0$\times$ over fp16 models and up to 1.54$\times$ over uniform quantization approaches while preserving the output quality.
Enhancing Dropout-based Bayesian Neural Networks with Multi-Exit on FPGA
Jun 24, 2024Reliable uncertainty estimation plays a crucial role in various safety-critical applications such as medical diagnosis and autonomous driving. In recent years, Bayesian neural networks (BayesNNs) have gained substantial research and industrial interests due to their capability to make accurate predictions with reliable uncertainty estimation. However, the algorithmic complexity and the resulting hardware performance of BayesNNs hinder their adoption in real-life applications. To bridge this gap, this paper proposes an algorithm and hardware co-design framework that can generate field-programmable gate array (FPGA)-based accelerators for efficient BayesNNs. At the algorithm level, we propose novel multi-exit dropout-based BayesNNs with reduced computational and memory overheads while achieving high accuracy and quality of uncertainty estimation. At the hardware level, this paper introduces a transformation framework that can generate FPGA-based accelerators for the proposed efficient multi-exit BayesNNs. Several optimization techniques such as the mix of spatial and temporal mappings are introduced to reduce resource consumption and improve the overall hardware performance. Comprehensive experiments demonstrate that our approach can achieve higher energy efficiency compared to CPU, GPU, and other state-of-the-art hardware implementations. To support the future development of this research, we have open-sourced our code at: https://github.com/os-hxfan/MCME_FPGA_Acc.git
Hardware-Aware Neural Dropout Search for Reliable Uncertainty Prediction on FPGA
Jun 23, 2024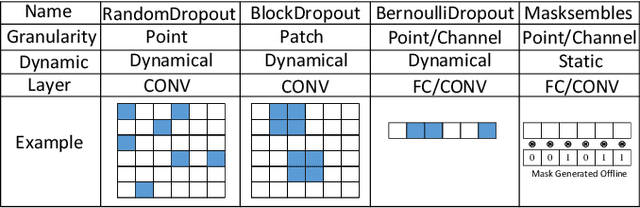
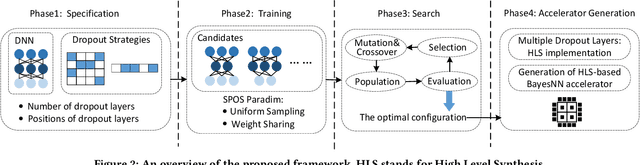

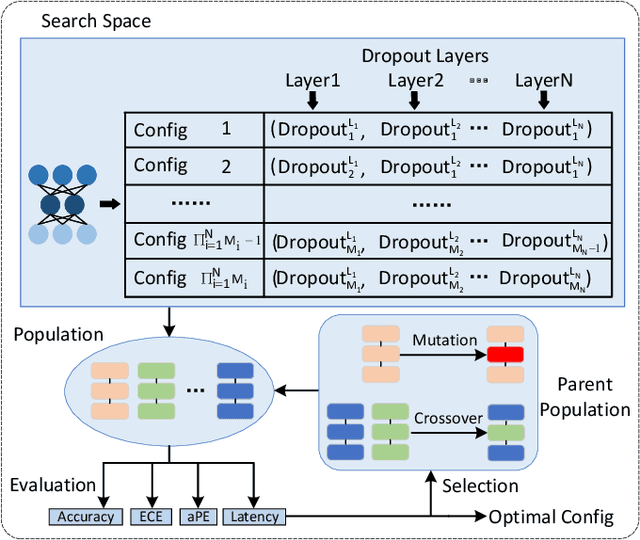
The increasing deployment of artificial intelligence (AI) for critical decision-making amplifies the necessity for trustworthy AI, where uncertainty estimation plays a pivotal role in ensuring trustworthiness. Dropout-based Bayesian Neural Networks (BayesNNs) are prominent in this field, offering reliable uncertainty estimates. Despite their effectiveness, existing dropout-based BayesNNs typically employ a uniform dropout design across different layers, leading to suboptimal performance. Moreover, as diverse applications require tailored dropout strategies for optimal performance, manually optimizing dropout configurations for various applications is both error-prone and labor-intensive. To address these challenges, this paper proposes a novel neural dropout search framework that automatically optimizes both the dropout-based BayesNNs and their hardware implementations on FPGA. We leverage one-shot supernet training with an evolutionary algorithm for efficient dropout optimization. A layer-wise dropout search space is introduced to enable the automatic design of dropout-based BayesNNs with heterogeneous dropout configurations. Extensive experiments demonstrate that our proposed framework can effectively find design configurations on the Pareto frontier. Compared to manually-designed dropout-based BayesNNs on GPU, our search approach produces FPGA designs that can achieve up to 33X higher energy efficiency. Compared to state-of-the-art FPGA designs of BayesNN, the solutions from our approach can achieve higher algorithmic performance and energy efficiency.