 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Mixed-Precision Decoding for Efficient LLM Inference
Paper and Code
Oct 17, 2024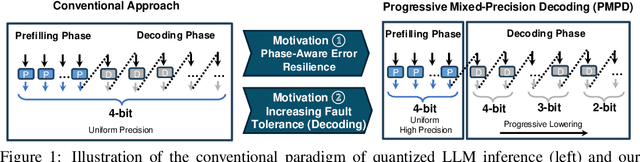
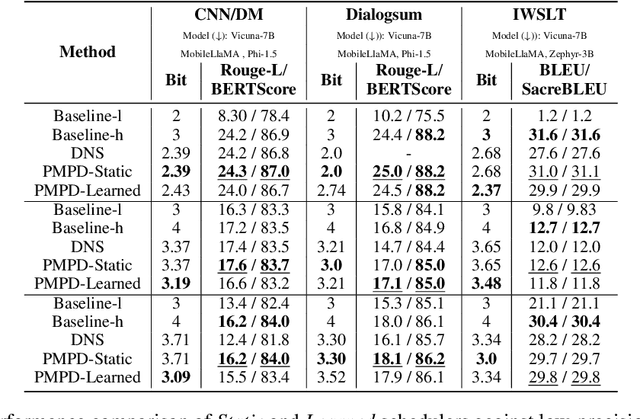
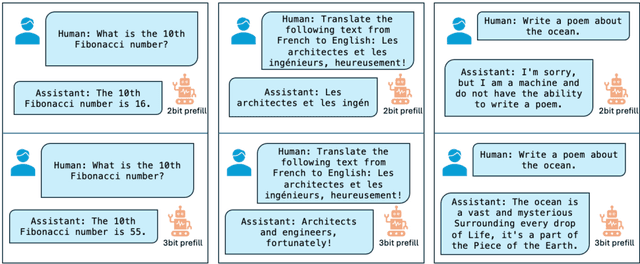
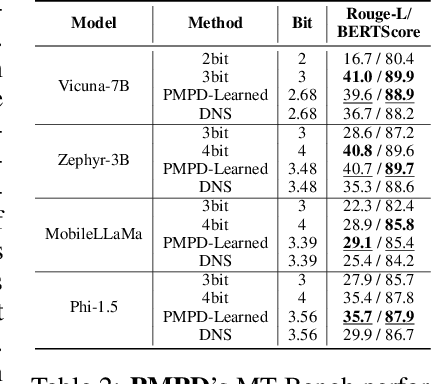
In spite of the great potential of large language models (LLMs) across various tasks, their deployment on resource-constrained devices remains challenging due to their excessive computational and memory demands. Quantization has emerged as an effective solution by storing weights in reduced precision. However, utilizing low precisions (i.e.~2/3-bit) to substantially alleviate the memory-boundedness of LLM decoding, still suffers from prohibitive performance drop. In this work, we argue that existing approaches fail to explore the diversity in computational patterns, redundancy, and sensitivity to approximations of the different phases of LLM inference, resorting to a uniform quantization policy throughout. Instead, we propose a novel phase-aware method that selectively allocates precision during different phases of LLM inference, achieving both strong context extraction during prefill and efficient memory bandwidth utilization during decoding. To further address the memory-boundedness of the decoding phase, we introduce Progressive Mixed-Precision Decoding (PMPD), a technique that enables the gradual lowering of precision deeper in the generated sequence, together with a spectrum of precision-switching schedulers that dynamically drive the precision-lowering decisions in either task-adaptive or prompt-adaptive manner. Extensive evaluation across diverse language tasks shows that when targeting Nvidia GPUs, PMPD achieves 1.4$-$12.2$\times$ speedup in matrix-vector multiplications over fp16 models, while when targeting an LLM-optimized NPU, our approach delivers a throughput gain of 3.8$-$8.0$\times$ over fp16 models and up to 1.54$\times$ over uniform quantization approaches while preserving the output quality.