 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardware-Aware Neural Dropout Search for Reliable Uncertainty Prediction on FPGA
Jun 23, 2024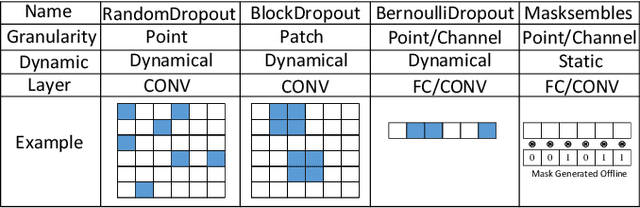
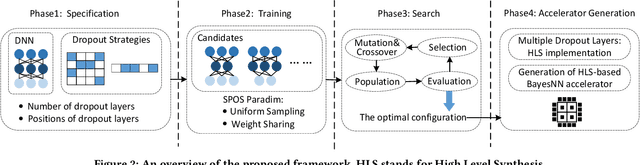

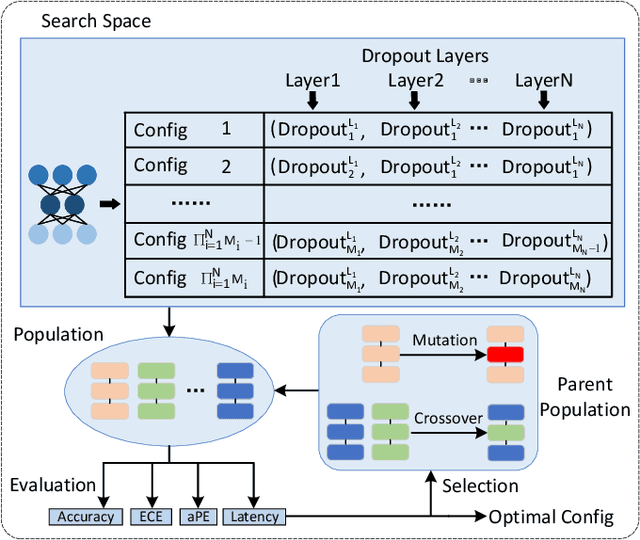
The increasing deployment of artificial intelligence (AI) for critical decision-making amplifies the necessity for trustworthy AI, where uncertainty estimation plays a pivotal role in ensuring trustworthiness. Dropout-based Bayesian Neural Networks (BayesNNs) are prominent in this field, offering reliable uncertainty estimates. Despite their effectiveness, existing dropout-based BayesNNs typically employ a uniform dropout design across different layers, leading to suboptimal performance. Moreover, as diverse applications require tailored dropout strategies for optimal performance, manually optimizing dropout configurations for various applications is both error-prone and labor-intensive. To address these challenges, this paper proposes a novel neural dropout search framework that automatically optimizes both the dropout-based BayesNNs and their hardware implementations on FPGA. We leverage one-shot supernet training with an evolutionary algorithm for efficient dropout optimization. A layer-wise dropout search space is introduced to enable the automatic design of dropout-based BayesNNs with heterogeneous dropout configurations. Extensive experiments demonstrate that our proposed framework can effectively find design configurations on the Pareto frontier. Compared to manually-designed dropout-based BayesNNs on GPU, our search approach produces FPGA designs that can achieve up to 33X higher energy efficiency. Compared to state-of-the-art FPGA designs of BayesNN, the solutions from our approach can achieve higher algorithmic performance and energy efficiency.
FedorAS: Federated Architecture Search under system heterogeneity
Jun 23, 2022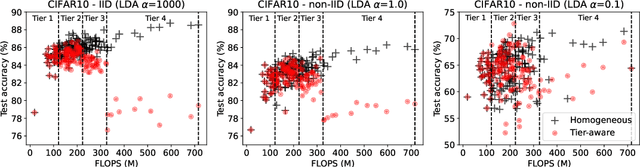
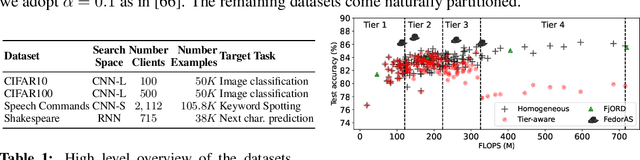
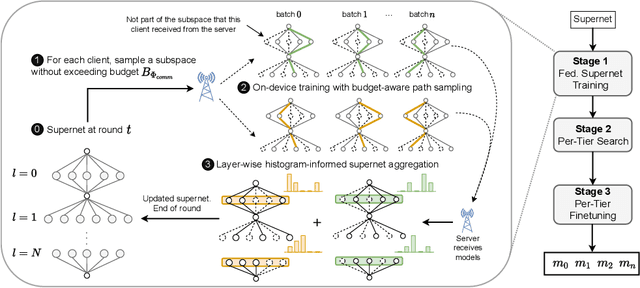
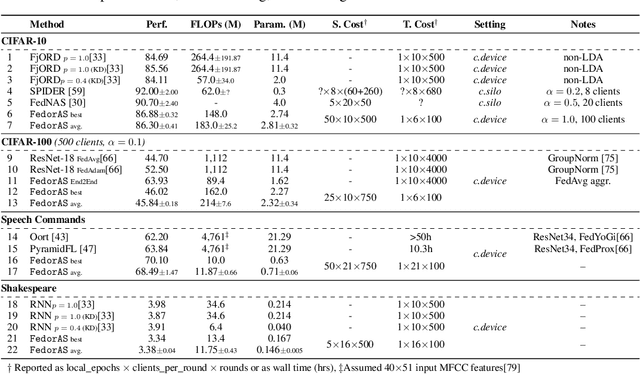
Federated learning (FL) has recently gained considerable attention due to its ability to use decentralised data while preserving privacy. However, it also poses additional challenges related to the heterogeneity of the participating devices, both in terms of their computational capabilities and contributed data. Meanwhile, Neural Architecture Search (NAS) has been successfully used with centralised datasets, producing state-of-the-art results in constrained (hardware-aware) and unconstrained settings. However, even the most recent work laying at the intersection of NAS and FL assumes homogeneous compute environment with datacenter-grade hardware and does not address the issues of working with constrained, heterogeneous devices. As a result, practical usage of NAS in a federated setting remains an open problem that we address in our work. We design our system, FedorAS, to discover and train promising architectures when dealing with devices of varying capabilities holding non-IID distributed data, and present empirical evidence of its effectiveness across different settings. Specifically, we evaluate FedorAS across datasets spanning three different modalities (vision, speech, text) and show its better performance compared to state-of-the-art federated solutions, while maintaining resource efficiency.
EdgeViTs: Competing Light-weight CNNs on Mobile Devices with Vision Transformers
May 06, 2022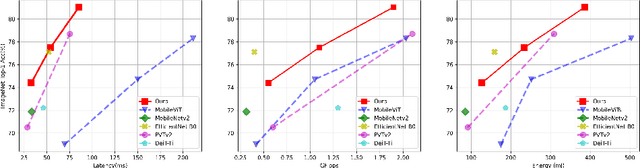
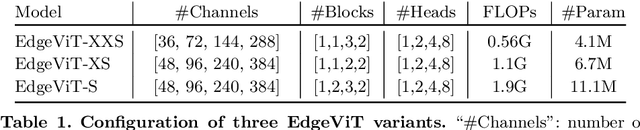
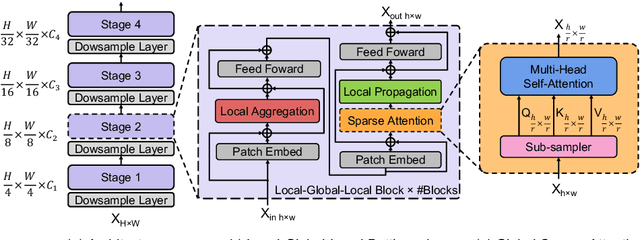
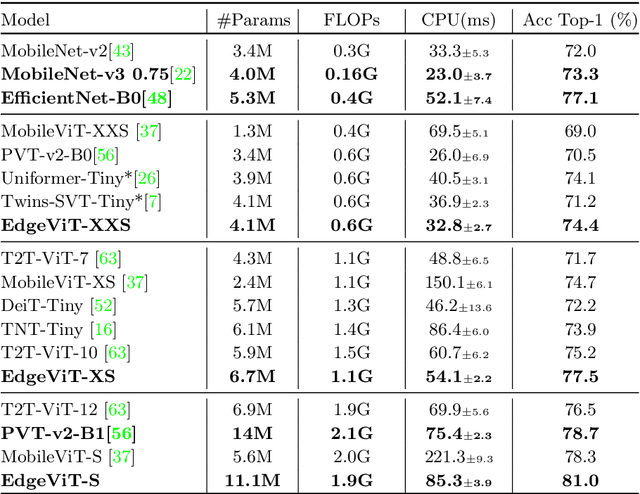
Self-attention based models such as vision transformers (ViTs) have emerged as a very competitive architecture alternative to convolutional neural networks (CNNs) in computer vision. Despite increasingly stronger variants with ever-higher recognition accuracies, due to the quadratic complexity of self-attention, existing ViTs are typically demanding in computation and model size. Although several successful design choices (e.g., the convolutions and hierarchical multi-stage structure) of prior CNNs have been reintroduced into recent ViTs, they are still not sufficient to meet the limited resource requirements of mobile devices. This motivates a very recent attempt to develop light ViTs based on the state-of-the-art MobileNet-v2, but still leaves a performance gap behind. In this work, pushing further along this under-studied direction we introduce EdgeViTs, a new family of light-weight ViTs that, for the first time, enable attention-based vision models to compete with the best light-weight CNNs in the tradeoff between accuracy and on-device efficiency. This is realized by introducing a highly cost-effective local-global-local (LGL) information exchange bottleneck based on optimal integration of self-attention and convolutions. For device-dedicated evaluation, rather than relying on inaccurate proxies like the number of FLOPs or parameters, we adopt a practical approach of focusing directly on on-device latency and, for the first time, energy efficiency. Specifically, we show that our models are Pareto-optimal when both accuracy-latency and accuracy-energy trade-offs are considered, achieving strict dominance over other ViTs in almost all cases and competing with the most efficient CNNs.
Smart at what cost? Characterising Mobile Deep Neural Networks in the wild
Sep 28, 2021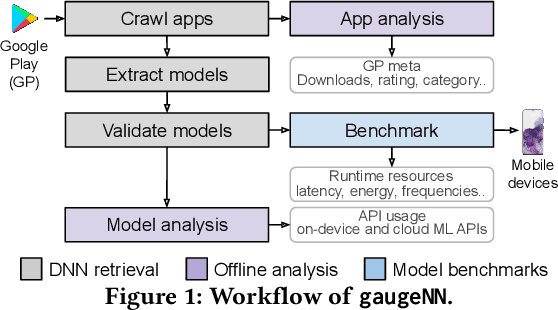
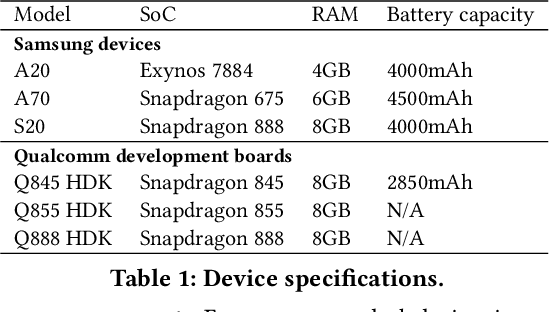
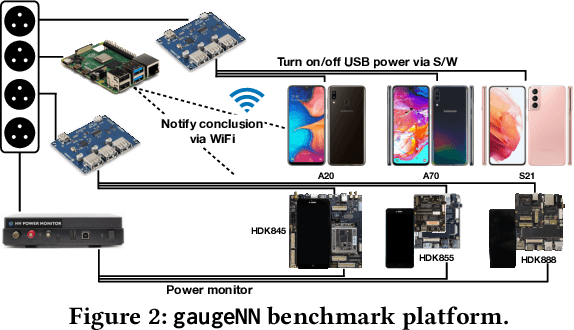
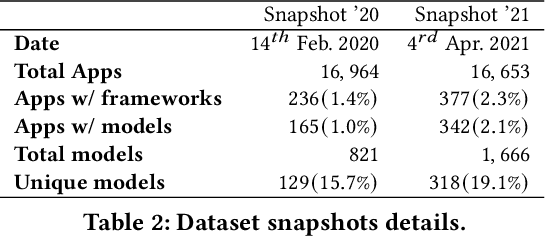
With smartphones' omnipresence in people's pockets, Machine Learning (ML) on mobile is gaining traction as devices become more powerful. With applications ranging from visual filters to voice assistants, intelligence on mobile comes in many forms and facets. However, Deep Neural Network (DNN) inference remains a compute intensive workload, with devices struggling to support intelligence at the cost of responsiveness.On the one hand, there is significant research on reducing model runtime requirements and supporting deployment on embedded devices. On the other hand, the strive to maximise the accuracy of a task is supported by deeper and wider neural networks, making mobile deployment of state-of-the-art DNNs a moving target. In this paper, we perform the first holistic study of DNN usage in the wild in an attempt to track deployed models and match how these run on widely deployed devices. To this end, we analyse over 16k of the most popular apps in the Google Play Store to characterise their DNN usage and performance across devices of different capabilities, both across tiers and generations. Simultaneously, we measure the models' energy footprint, as a core cost dimension of any mobile deployment. To streamline the process, we have developed gaugeNN, a tool that automates the deployment, measurement and analysis of DNNs on devices, with support for different frameworks and platforms. Results from our experience study paint the landscape of deep learning deployments on smartphones and indicate their popularity across app developers. Furthermore, our study shows the gap between bespoke techniques and real-world deployments and the need for optimised deployment of deep learning models in a highly dynamic and heterogeneous ecosystem.
Dynamic Channel Pruning: Feature Boosting and Suppression
Oct 12, 2018

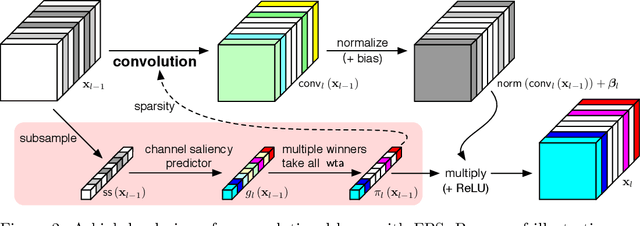
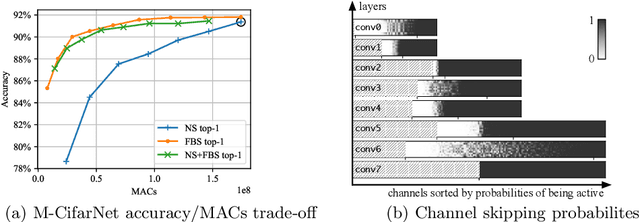
Making deep convolutional neural networks more accurate typically comes at the cost of increased computational and memory resources. In this paper, we exploit the fact that the importance of features computed by convolutional layers is highly input-dependent, and propose feature boosting and suppression (FBS), a new method to predictively amplify salient convolutional channels and skip unimportant ones at run-time. FBS introduces small auxiliary connections to existing convolutional layers. In contrast to channel pruning methods which permanently remove channels, it preserves the full network structures and accelerates convolution by dynamically skipping unimportant input and output channels. FBS-augmented networks are trained with conventional stochastic gradient descent, making it readily available for many state-of-the-art CNNs. We compare FBS to a range of existing channel pruning and dynamic execution schemes and demonstrate large improvements on ImageNet classification. Experiments show that FBS can accelerate VGG-16 by $5\times$ and improve the speed of ResNet-18 by $2\times$, both with less than $0.6\%$ top-5 accuracy loss.