 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAWQ-SR: A Hybrid-Precision NPU Engine for Efficient On-Device Super-Resolution
Dec 15, 2022



In recent years, image and video delivery systems have begun integrating deep learning super-resolution (SR) approaches, leveraging their unprecedented visual enhancement capabilities while reducing reliance on networking conditions. Nevertheless, deploying these solutions on mobile devices still remains an active challenge as SR models are excessively demanding with respect to workload and memory footprint. Despite recent progress on on-device SR frameworks, existing systems either penalize visual quality, lead to excessive energy consumption or make inefficient use of the available resources. This work presents NAWQ-SR, a novel framework for the efficient on-device execution of SR models. Through a novel hybrid-precision quantization technique and a runtime neural image codec, NAWQ-SR exploits the multi-precision capabilities of modern mobile NPUs in order to minimize latency, while meeting user-specified quality constraints. Moreover, NAWQ-SR selectively adapts the arithmetic precision at run time to equip the SR DNN's layers with wider representational power, improving visual quality beyond what was previously possible on NPUs. Altogether, NAWQ-SR achieves an average speedup of 7.9x, 3x and 1.91x over the state-of-the-art on-device SR systems that use heterogeneous processors (MobiSR), CPU (SplitSR) and NPU (XLSR), respectively. Furthermore, NAWQ-SR delivers an average of 3.2x speedup and 0.39 dB higher PSNR over status-quo INT8 NPU designs, but most importantly mitigates the negative effects of quantization on visual quality, setting a new state-of-the-art in the attainable quality of NPU-based SR.
Smart at what cost? Characterising Mobile Deep Neural Networks in the wild
Sep 28, 2021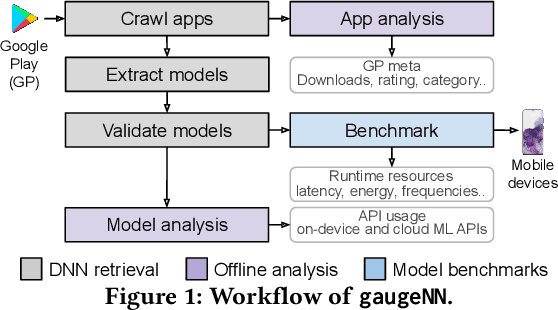
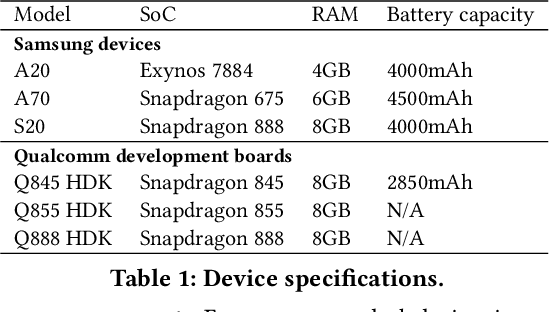
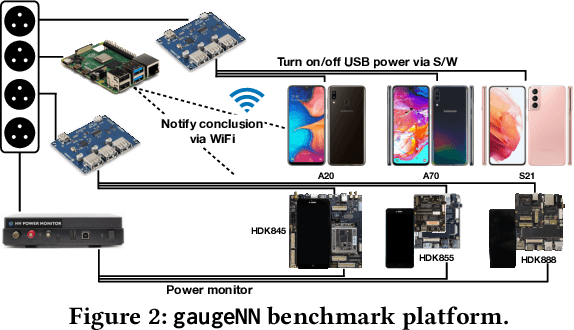
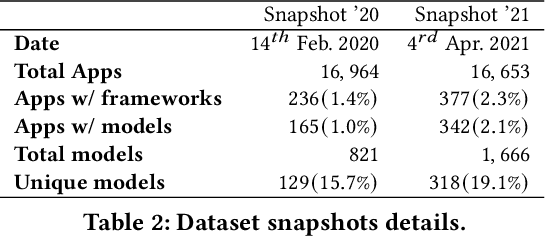
With smartphones' omnipresence in people's pockets, Machine Learning (ML) on mobile is gaining traction as devices become more powerful. With applications ranging from visual filters to voice assistants, intelligence on mobile comes in many forms and facets. However, Deep Neural Network (DNN) inference remains a compute intensive workload, with devices struggling to support intelligence at the cost of responsiveness.On the one hand, there is significant research on reducing model runtime requirements and supporting deployment on embedded devices. On the other hand, the strive to maximise the accuracy of a task is supported by deeper and wider neural networks, making mobile deployment of state-of-the-art DNNs a moving target. In this paper, we perform the first holistic study of DNN usage in the wild in an attempt to track deployed models and match how these run on widely deployed devices. To this end, we analyse over 16k of the most popular apps in the Google Play Store to characterise their DNN usage and performance across devices of different capabilities, both across tiers and generations. Simultaneously, we measure the models' energy footprint, as a core cost dimension of any mobile deployment. To streamline the process, we have developed gaugeNN, a tool that automates the deployment, measurement and analysis of DNNs on devices, with support for different frameworks and platforms. Results from our experience study paint the landscape of deep learning deployments on smartphones and indicate their popularity across app developers. Furthermore, our study shows the gap between bespoke techniques and real-world deployments and the need for optimised deployment of deep learning models in a highly dynamic and heterogeneous ecosystem.
DynO: Dynamic Onloading of Deep Neural Networks from Cloud to Device
Apr 20, 2021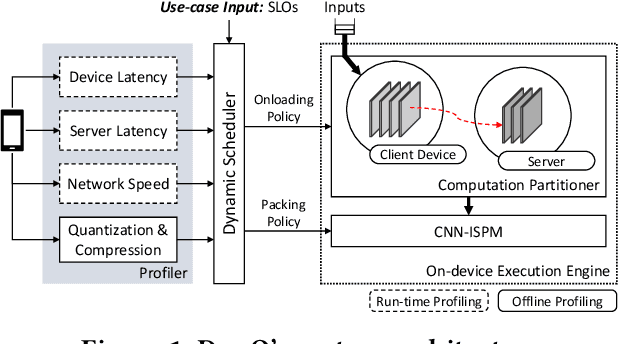

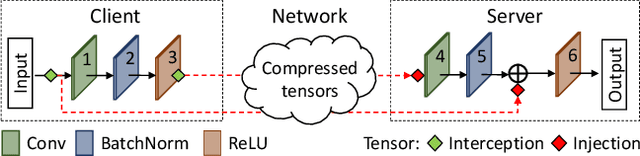
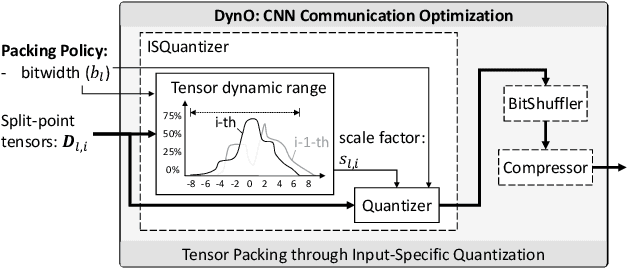
Recently, there has been an explosive growth of mobile and embedded applications using convolutional neural networks(CNNs). To alleviate their excessive computational demands, developers have traditionally resorted to cloud offloading, inducing high infrastructure costs and a strong dependence on networking conditions. On the other end, the emergence of powerful SoCs is gradually enabling on-device execution. Nonetheless, low- and mid-tier platforms still struggle to run state-of-the-art CNNs sufficiently. In this paper, we present DynO, a distributed inference framework that combines the best of both worlds to address several challenges, such as device heterogeneity, varying bandwidth and multi-objective requirements. Key components that enable this are its novel CNN-specific data packing method, which exploits the variability of precision needs in different parts of the CNN when onloading computation, and its novel scheduler that jointly tunes the partition point and transferred data precision at run time to adapt inference to its execution environment. Quantitative evaluation shows that DynO outperforms the current state-of-the-art, improving throughput by over an order of magnitude over device-only execution and up to 7.9x over competing CNN offloading systems, with up to 60x less data transferred.
FjORD: Fair and Accurate Federated Learning under heterogeneous targets with Ordered Dropout
Mar 01, 2021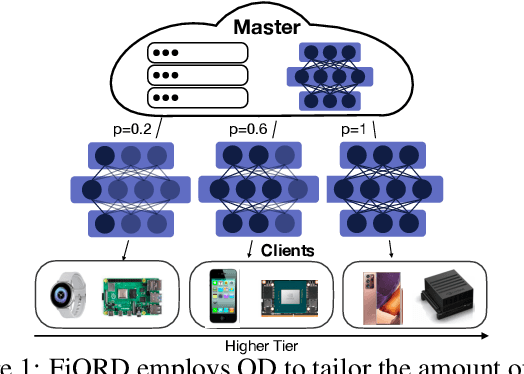
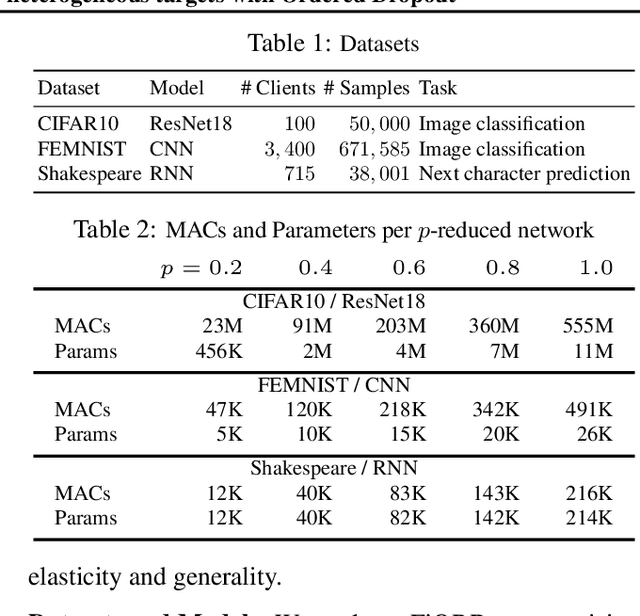
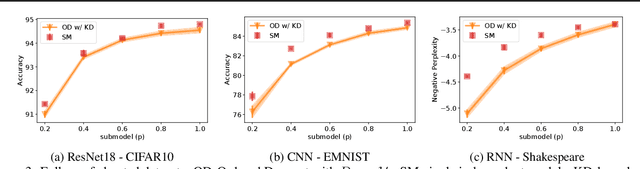
Federated Learning (FL) has been gaining significant traction across different ML tasks, ranging from vision to keyboard predictions. In large-scale deployments, client heterogeneity is a fact, and constitutes a primary problem for fairness, training performance and accuracy. Although significant efforts have been made into tackling statistical data heterogeneity, the diversity in the processing capabilities and network bandwidth of clients, termed as system heterogeneity, has remained largely unexplored. Current solutions either disregard a large portion of available devices or set a uniform limit on the model's capacity, restricted by the least capable participants. In this work, we introduce Ordered Dropout, a mechanism that achieves an ordered, nested representation of knowledge in Neural Networks and enables the extraction of lower footprint submodels without the need of retraining. We further show that for linear maps our Ordered Dropout is equivalent to SVD. We employ this technique, along with a self-distillation methodology, in the realm of FL in a framework called FjORD. FjORD alleviates the problem of client system heterogeneity by tailoring the model width to the client's capabilities. Extensive evaluation on both CNNs and RNNs across diverse modalities shows that FjORD consistently leads to significant performance gains over state-of-the-art baselines, while maintaining its nested structure.
SPINN: Synergistic Progressive Inference of Neural Networks over Device and Cloud
Aug 24, 2020



Despite the soaring use of convolutional neural networks (CNNs) in mobile applications, uniformly sustaining high-performance inference on mobile has been elusive due to the excessive computational demands of modern CNNs and the increasing diversity of deployed devices. A popular alternative comprises offloading CNN processing to powerful cloud-based servers. Nevertheless, by relying on the cloud to produce outputs, emerging mission-critical and high-mobility applications, such as drone obstacle avoidance or interactive applications, can suffer from the dynamic connectivity conditions and the uncertain availability of the cloud. In this paper, we propose SPINN, a distributed inference system that employs synergistic device-cloud computation together with a progressive inference method to deliver fast and robust CNN inference across diverse settings. The proposed system introduces a novel scheduler that co-optimises the early-exit policy and the CNN splitting at run time, in order to adapt to dynamic conditions and meet user-defined service-level requirements. Quantitative evaluation illustrates that SPINN outperforms its state-of-the-art collaborative inference counterparts by up to 2x in achieved throughput under varying network conditions, reduces the server cost by up to 6.8x and improves accuracy by 20.7% under latency constraints, while providing robust operation under uncertain connectivity conditions and significant energy savings compared to cloud-centric execution.
EmBench: Quantifying Performance Variations of Deep Neural Networks across Modern Commodity Devices
May 17, 2019
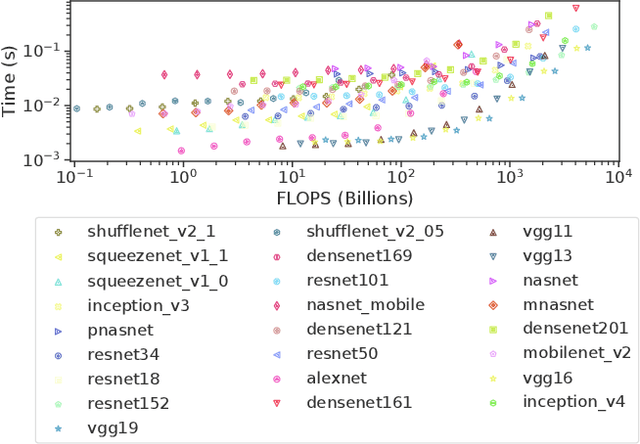
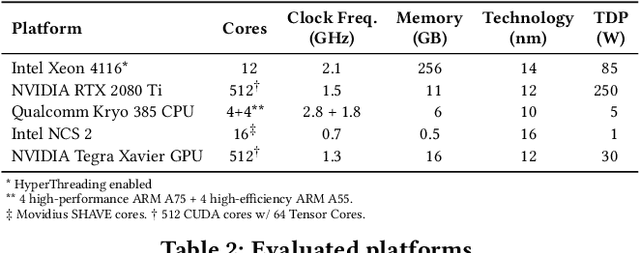
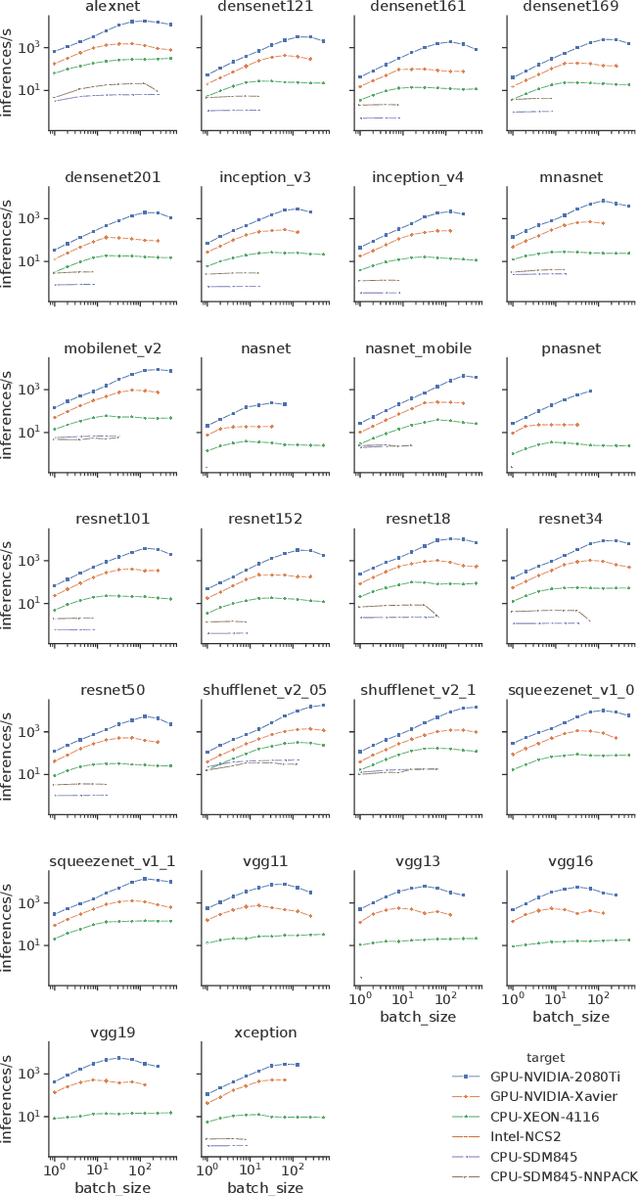
In recent years, advances in deep learning have resulted in unprecedented leaps in diverse tasks spanning from speech and object recognition to context awareness and health monitoring. As a result, an increasing number of AI-enabled applications are being developed targeting ubiquitous and mobile devices. While deep neural networks (DNNs) are getting bigger and more complex, they also impose a heavy computational and energy burden on the host devices, which has led to the integration of various specialized processors in commodity devices. Given the broad range of competing DNN architectures and the heterogeneity of the target hardware, there is an emerging need to understand the compatibility between DNN-platform pairs and the expected performance benefits on each platform. This work attempts to demystify this landscape by systematically evaluating a collection of state-of-the-art DNNs on a wide variety of commodity devices. In this respect, we identify potential bottlenecks in each architecture and provide important guidelines that can assist the community in the co-design of more efficient DNNs and accelerators.