 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmBench: Quantifying Performance Variations of Deep Neural Networks across Modern Commodity Devices
Paper and Code

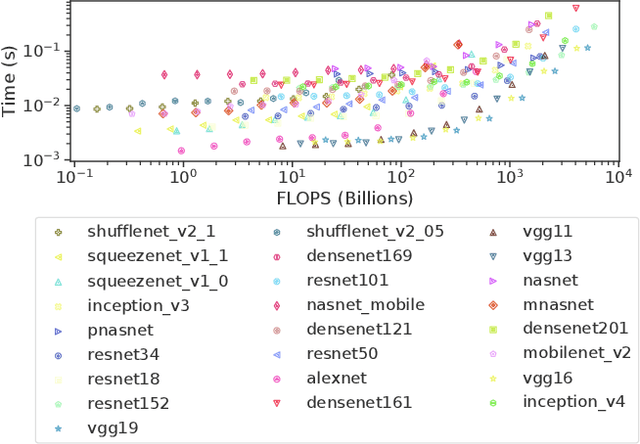
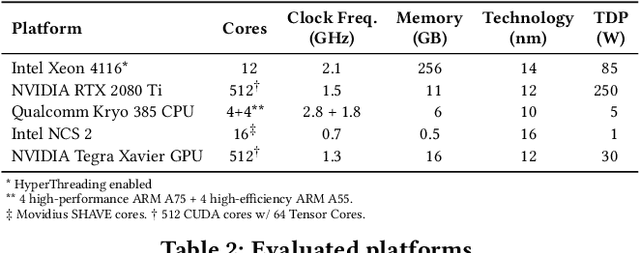
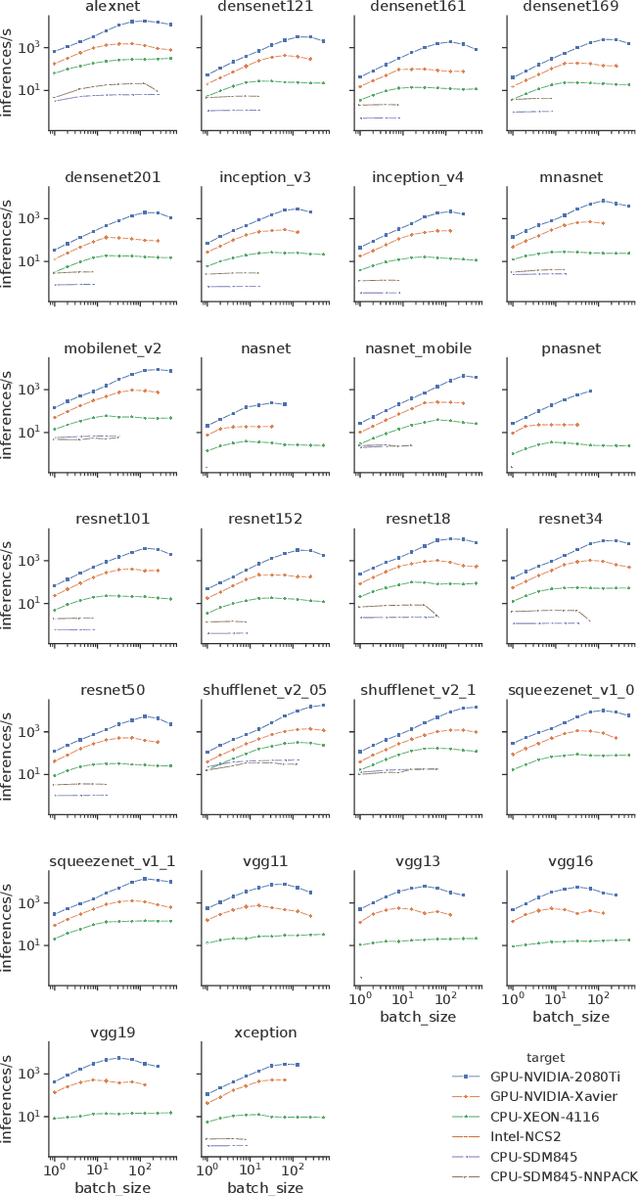
In recent years, advances in deep learning have resulted in unprecedented leaps in diverse tasks spanning from speech and object recognition to context awareness and health monitoring. As a result, an increasing number of AI-enabled applications are being developed targeting ubiquitous and mobile devices. While deep neural networks (DNNs) are getting bigger and more complex, they also impose a heavy computational and energy burden on the host devices, which has led to the integration of various specialized processors in commodity devices. Given the broad range of competing DNN architectures and the heterogeneity of the target hardware, there is an emerging need to understand the compatibility between DNN-platform pairs and the expected performance benefits on each platform. This work attempts to demystify this landscape by systematically evaluating a collection of state-of-the-art DNNs on a wide variety of commodity devices. In this respect, we identify potential bottlenecks in each architecture and provide important guidelines that can assist the community in the co-design of more efficient DNNs and accelerators.