 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedorAS: Federated Architecture Search under system heterogeneity
Paper and Code
Jun 23, 2022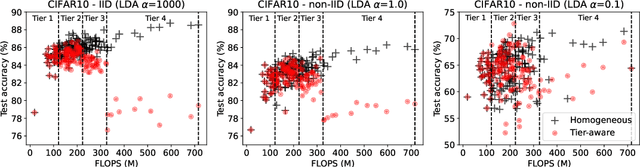
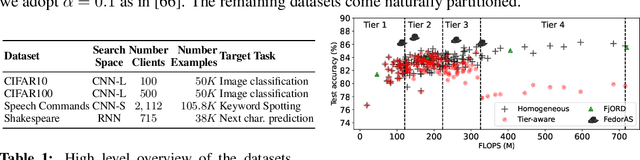
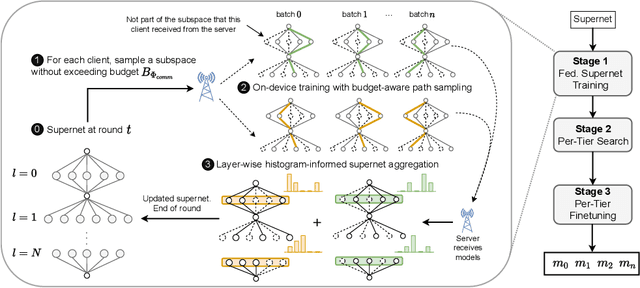
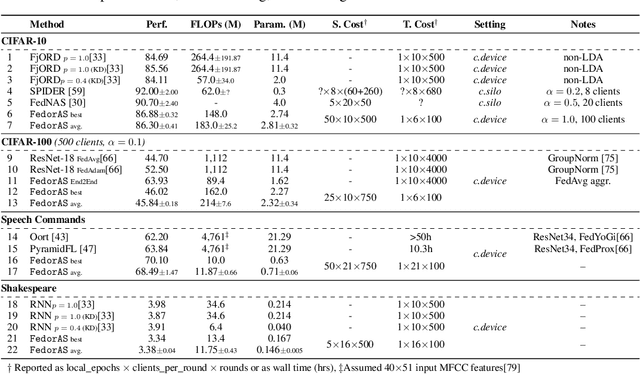
Federated learning (FL) has recently gained considerable attention due to its ability to use decentralised data while preserving privacy. However, it also poses additional challenges related to the heterogeneity of the participating devices, both in terms of their computational capabilities and contributed data. Meanwhile, Neural Architecture Search (NAS) has been successfully used with centralised datasets, producing state-of-the-art results in constrained (hardware-aware) and unconstrained settings. However, even the most recent work laying at the intersection of NAS and FL assumes homogeneous compute environment with datacenter-grade hardware and does not address the issues of working with constrained, heterogeneous devices. As a result, practical usage of NAS in a federated setting remains an open problem that we address in our work. We design our system, FedorAS, to discover and train promising architectures when dealing with devices of varying capabilities holding non-IID distributed data, and present empirical evidence of its effectiveness across different settings. Specifically, we evaluate FedorAS across datasets spanning three different modalities (vision, speech, text) and show its better performance compared to state-of-the-art federated solutions, while maintaining resource efficiency.