 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture of Weight-shared Heterogeneous Group Attention Experts for Dynamic Token-wise KV Optimization
Jun 16, 2025
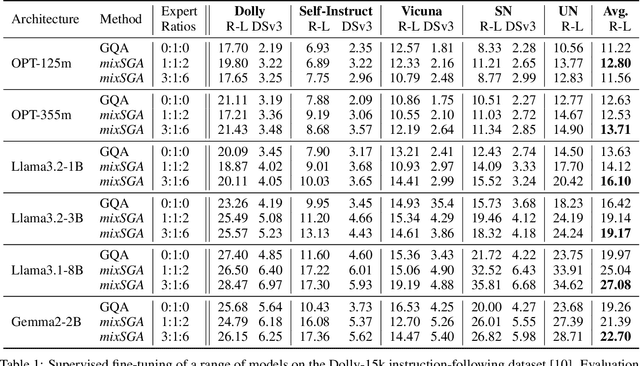
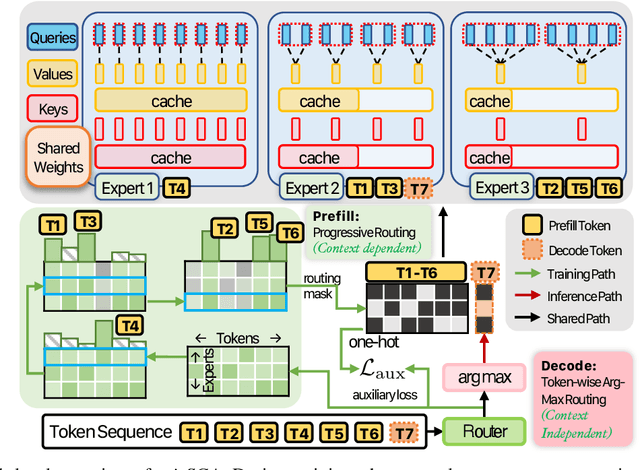

Transformer models face scalability challenges in causal language modeling (CLM) due to inefficient memory allocation for growing key-value (KV) caches, which strains compute and storage resources. Existing methods like Grouped Query Attention (GQA) and token-level KV optimization improve efficiency but rely on rigid resource allocation, often discarding "low-priority" tokens or statically grouping them, failing to address the dynamic spectrum of token importance. We propose mixSGA, a novel mixture-of-expert (MoE) approach that dynamically optimizes token-wise computation and memory allocation. Unlike prior approaches, mixSGA retains all tokens while adaptively routing them to specialized experts with varying KV group sizes, balancing granularity and efficiency. Our key novelties include: (1) a token-wise expert-choice routing mechanism guided by learned importance scores, enabling proportional resource allocation without token discard; (2) weight-sharing across grouped attention projections to minimize parameter overhead; and (3) an auxiliary loss to ensure one-hot routing decisions for training-inference consistency in CLMs. Extensive evaluations across Llama3, TinyLlama, OPT, and Gemma2 model families show mixSGA's superiority over static baselines. On instruction-following and continued pretraining tasks, mixSGA achieves higher ROUGE-L and lower perplexity under the same KV budgets.
FLIP: Towards Comprehensive and Reliable Evaluation of Federated Prompt Learning
Mar 28, 2025The increasing emphasis on privacy and data security has driven the adoption of federated learning, a decentralized approach to train machine learning models without sharing raw data. Prompt learning, which fine-tunes prompt embeddings of pretrained models, offers significant advantages in federated settings by reducing computational costs and communication overheads while leveraging the strong performance and generalization capabilities of vision-language models such as CLIP. This paper addresses the intersection of federated learning and prompt learning, particularly for vision-language models. In this work, we introduce a comprehensive framework, named FLIP, to evaluate federated prompt learning algorithms. FLIP assesses the performance of 8 state-of-the-art federated prompt learning methods across 4 federated learning protocols and 12 open datasets, considering 6 distinct evaluation scenarios. Our findings demonstrate that prompt learning maintains strong generalization performance in both in-distribution and out-of-distribution settings with minimal resource consumption. This work highlights the effectiveness of federated prompt learning in environments characterized by data scarcity, unseen classes, and cross-domain distributional shifts. We open-source the code for all implemented algorithms in FLIP to facilitate further research in this domain.
Refining Salience-Aware Sparse Fine-Tuning Strategies for Language Models
Dec 18, 2024



Parameter-Efficient Fine-Tuning (PEFT) has gained prominence through low-rank adaptation methods like LoRA. In this paper, we focus on sparsity-based PEFT (SPEFT), which introduces trainable sparse adaptations to the weight matrices in the model, offering greater flexibility in selecting fine-tuned parameters compared to low-rank methods. We conduct the first systematic evaluation of salience metrics for SPEFT, inspired by zero-cost NAS proxies, and identify simple gradient-based metrics is reliable, and results are on par with the best alternatives, offering both computational efficiency and robust performance. Additionally, we compare static and dynamic masking strategies, finding that static masking, which predetermines non-zero entries before training, delivers efficiency without sacrificing performance, while dynamic masking offers no substantial benefits. Across NLP tasks, a simple gradient-based, static SPEFT consistently outperforms other fine-tuning methods for LLMs, providing a simple yet effective baseline for SPEFT. Our work challenges the notion that complexity is necessary for effective PEFT. Our work is open source and available to the community at [https://github.com/0-ml/speft].
Optimised Grouped-Query Attention Mechanism for Transformers
Jun 21, 2024



Grouped-query attention (GQA) has been widely adopted in LLMs to mitigate the complexity of multi-head attention (MHA). To transform an MHA to a GQA, neighbour queries in MHA are evenly split into groups where each group shares the value and key layers. In this work, we propose AsymGQA, an activation-informed approach to asymmetrically grouping an MHA to a GQA for better model performance. Our AsymGQA outperforms the GQA within the same model size budget. For example, AsymGQA LLaMA-2-7B has an accuracy increase of 7.5% on MMLU compared to neighbour grouping. Our approach addresses the GQA's trade-off problem between model performance and hardware efficiency.
Unlocking the Global Synergies in Low-Rank Adapters
Jun 21, 2024Low-rank Adaption (LoRA) has been the de-facto parameter-efficient fine-tuning technique for large language models. We present HeteroLoRA, a light-weight search algorithm that leverages zero-cost proxies to allocate the limited LoRA trainable parameters across the model for better fine-tuned performance. In addition to the allocation for the standard LoRA-adapted models, we also demonstrate the efficacy of HeteroLoRA by performing the allocation in a more challenging search space that includes LoRA modules and LoRA-adapted shortcut connections. Experiments show that HeteroLoRA enables improvements in model performance given the same parameter budge. For example, on MRPC, we see an improvement of 1.6% in accuracy with similar training parameter budget. We will open-source our algorithm once the paper is accepted.
Fed-Credit: Robust Federated Learning with Credibility Management
May 20, 2024



Aiming at privacy preservation, Federated Learning (FL) is an emerging machine learning approach enabling model training on decentralized devices or data sources. The learning mechanism of FL relies on aggregating parameter updates from individual clients. However, this process may pose a potential security risk due to the presence of malicious devices. Existing solutions are either costly due to the use of compute-intensive technology, or restrictive for reasons of strong assumptions such as the prior knowledge of the number of attackers and how they attack. Few methods consider both privacy constraints and uncertain attack scenarios. In this paper, we propose a robust FL approach based on the credibility management scheme, called Fed-Credit. Unlike previous studies, our approach does not require prior knowledge of the nodes and the data distribution. It maintains and employs a credibility set, which weighs the historical clients' contributions based on the similarity between the local models and global model, to adjust the global model update. The subtlety of Fed-Credit is that the time decay and attitudinal value factor are incorporated into the dynamic adjustment of the reputation weights and it boasts a computational complexity of O(n) (n is the number of the clients). We conducted extensive experiments on the MNIST and CIFAR-10 datasets under 5 types of attacks. The results exhibit superior accuracy and resilience against adversarial attacks, all while maintaining comparatively low computational complexity. Among these, on the Non-IID CIFAR-10 dataset, our algorithm exhibited performance enhancements of 19.5% and 14.5%, respectively, in comparison to the state-of-the-art algorithm when dealing with two types of data poisoning attacks.
APBench: A Unified Benchmark for Availability Poisoning Attacks and Defenses
Aug 07, 2023



The efficacy of availability poisoning, a method of poisoning data by injecting imperceptible perturbations to prevent its use in model training, has been a hot subject of investigation. Previous research suggested that it was difficult to effectively counteract such poisoning attacks. However, the introduction of various defense methods has challenged this notion. Due to the rapid progress in this field, the performance of different novel methods cannot be accurately validated due to variations in experimental setups. To further evaluate the attack and defense capabilities of these poisoning methods, we have developed a benchmark -- APBench for assessing the efficacy of adversarial poisoning. APBench consists of 9 state-of-the-art availability poisoning attacks, 8 defense algorithms, and 4 conventional data augmentation techniques. We also have set up experiments with varying different poisoning ratios, and evaluated the attacks on multiple datasets and their transferability across model architectures. We further conducted a comprehensive evaluation of 2 additional attacks specifically targeting unsupervised models. Our results reveal the glaring inadequacy of existing attacks in safeguarding individual privacy. APBench is open source and available to the deep learning community: https://github.com/lafeat/apbench.
Learning the Unlearnable: Adversarial Augmentations Suppress Unlearnable Example Attacks
Mar 27, 2023



Unlearnable example attacks are data poisoning techniques that can be used to safeguard public data against unauthorized use for training deep learning models. These methods add stealthy perturbations to the original image, thereby making it difficult for deep learning models to learn from these training data effectively. Current research suggests that adversarial training can, to a certain degree, mitigate the impact of unlearnable example attacks, while common data augmentation methods are not effective against such poisons. Adversarial training, however, demands considerable computational resources and can result in non-trivial accuracy loss. In this paper, we introduce the UEraser method, which outperforms current defenses against different types of state-of-the-art unlearnable example attacks through a combination of effective data augmentation policies and loss-maximizing adversarial augmentations. In stark contrast to the current SOTA adversarial training methods, UEraser uses adversarial augmentations, which extends beyond the confines of $ \ell_p $ perturbation budget assumed by current unlearning attacks and defenses. It also helps to improve the model's generalization ability, thus protecting against accuracy loss. UEraser wipes out the unlearning effect with error-maximizing data augmentations, thus restoring trained model accuracies. Interestingly, UEraser-Lite, a fast variant without adversarial augmentations, is also highly effective in preserving clean accuracies. On challenging unlearnable CIFAR-10, CIFAR-100, SVHN, and ImageNet-subset datasets produced with various attacks, it achieves results that are comparable to those obtained during clean training. We also demonstrate its efficacy against possible adaptive attacks. Our code is open source and available to the deep learning community: https://github.com/lafeat/ueraser.
Flareon: Stealthy any2any Backdoor Injection via Poisoned Augmentation
Dec 20, 2022Open software supply chain attacks, once successful, can exact heavy costs in mission-critical applications. As open-source ecosystems for deep learning flourish and become increasingly universal, they present attackers previously unexplored avenues to code-inject malicious backdoors in deep neural network models. This paper proposes Flareon, a small, stealthy, seemingly harmless code modification that specifically targets the data augmentation pipeline with motion-based triggers. Flareon neither alters ground-truth labels, nor modifies the training loss objective, nor does it assume prior knowledge of the victim model architecture, training data, and training hyperparameters. Yet, it has a surprisingly large ramification on training -- models trained under Flareon learn powerful target-conditional (or "any2any") backdoors. The resulting models can exhibit high attack success rates for any target choices and better clean accuracies than backdoor attacks that not only seize greater control, but also assume more restrictive attack capabilities. We also demonstrate the effectiveness of Flareon against recent defenses. Flareon is fully open-source and available online to the deep learning community: https://github.com/lafeat/flareon.
MORA: Improving Ensemble Robustness Evaluation with Model-Reweighing Attack
Nov 15, 2022Adversarial attacks can deceive neural networks by adding tiny perturbations to their input data. Ensemble defenses, which are trained to minimize attack transferability among sub-models, offer a promising research direction to improve robustness against such attacks while maintaining a high accuracy on natural inputs. We discover, however, that recent state-of-the-art (SOTA) adversarial attack strategies cannot reliably evaluate ensemble defenses, sizeably overestimating their robustness. This paper identifies the two factors that contribute to this behavior. First, these defenses form ensembles that are notably difficult for existing gradient-based method to attack, due to gradient obfuscation. Second, ensemble defenses diversify sub-model gradients, presenting a challenge to defeat all sub-models simultaneously, simply summing their contributions may counteract the overall attack objective; yet, we observe that ensemble may still be fooled despite most sub-models being correct. We therefore introduce MORA, a model-reweighing attack to steer adversarial example synthesis by reweighing the importance of sub-model gradients. MORA finds that recent ensemble defenses all exhibit varying degrees of overestimated robustness. Comparing it against recent SOTA white-box attacks, it can converge orders of magnitude faster while achieving higher attack success rates across all ensemble models examined with three different ensemble modes (i.e., ensembling by either softmax, voting or logits). In particular, most ensemble defenses exhibit near or exactly 0% robustness against MORA with $\ell^\infty$ perturbation within 0.02 on CIFAR-10, and 0.01 on CIFAR-100. We make MORA open source with reproducible results and pre-trained models; and provide a leaderboard of ensemble defenses under various attack strategies.