 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDummy-Aware Weighted Attack (DAWA): Breaking the Safe Sink in Dummy Class Defenses
Mar 31, 2026Adversarial robustness evaluation faces a critical challenge as new defense paradigms emerge that can exploit limitations in existing assessment methods. This paper reveals that Dummy Classes-based defenses, which introduce an additional "dummy" class as a safety sink for adversarial examples, achieve significantly overestimated robustness under conventional evaluation strategies like AutoAttack. The fundamental limitation stems from these attacks' singular focus on misleading the true class label, which aligns perfectly with the defense mechanism--successful attacks are simply captured by the dummy class. To address this gap, we propose Dummy-Aware Weighted Attack (DAWA), a novel evaluation method that simultaneously targets both the true label and dummy label with adaptive weighting during adversarial example synthesis. Extensive experiments demonstrate that DAWA effectively breaks this defense paradigm, reducing the measured robustness of a leading Dummy Classes-based defense from 58.61% to 29.52% on CIFAR-10 under l_infty perturbation (epsilon=8/255). Our work provides a more reliable benchmark for evaluating this emerging class of defenses and highlights the need for continuous evolution of robustness assessment methodologies.
Why the Maximum Second Derivative of Activations Matters for Adversarial Robustness
Mar 25, 2026This work investigates the critical role of activation function curvature -- quantified by the maximum second derivative $\max|σ''|$ -- in adversarial robustness. Using the Recursive Curvature-Tunable Activation Family (RCT-AF), which enables precise control over curvature through parameters $α$ and $β$, we systematically analyze this relationship. Our study reveals a fundamental trade-off: insufficient curvature limits model expressivity, while excessive curvature amplifies the normalized Hessian diagonal norm of the loss, leading to sharper minima that hinder robust generalization. This results in a non-monotonic relationship where optimal adversarial robustness consistently occurs when $\max|σ''|$ falls within 4 to 10, a finding that holds across diverse network architectures, datasets, and adversarial training methods. We provide theoretical insights into how activation curvature affects the diagonal elements of the hessian matrix of the loss, and experimentally demonstrate that the normalized Hessian diagonal norm exhibits a U-shaped dependence on $\max|σ''|$, with its minimum within the optimal robustness range, thereby validating the proposed mechanism.
RCR-AF: Enhancing Model Generalization via Rademacher Complexity Reduction Activation Function
Jul 30, 2025Despite their widespread success, deep neural networks remain critically vulnerable to adversarial attacks, posing significant risks in safety-sensitive applications. This paper investigates activation functions as a crucial yet underexplored component for enhancing model robustness. We propose a Rademacher Complexity Reduction Activation Function (RCR-AF), a novel activation function designed to improve both generalization and adversarial resilience. RCR-AF uniquely combines the advantages of GELU (including smoothness, gradient stability, and negative information retention) with ReLU's desirable monotonicity, while simultaneously controlling both model sparsity and capacity through built-in clipping mechanisms governed by two hyperparameters, $\alpha$ and $\gamma$. Our theoretical analysis, grounded in Rademacher complexity, demonstrates that these parameters directly modulate the model's Rademacher complexity, offering a principled approach to enhance robustness. Comprehensive empirical evaluations show that RCR-AF consistently outperforms widely-used alternatives (ReLU, GELU, and Swish) in both clean accuracy under standard training and in adversarial robustness within adversarial training paradigms.
Theoretical Analysis of Relative Errors in Gradient Computations for Adversarial Attacks with CE Loss
Jul 30, 2025Gradient-based adversarial attacks using the Cross-Entropy (CE) loss often suffer from overestimation due to relative errors in gradient computation induced by floating-point arithmetic. This paper provides a rigorous theoretical analysis of these errors, conducting the first comprehensive study of floating-point computation errors in gradient-based attacks across four distinct scenarios: (i) unsuccessful untargeted attacks, (ii) successful untargeted attacks, (iii) unsuccessful targeted attacks, and (iv) successful targeted attacks. We establish theoretical foundations characterizing the behavior of relative numerical errors under different attack conditions, revealing previously unknown patterns in gradient computation instability, and identify floating-point underflow and rounding as key contributors. Building on this insight, we propose the Theoretical MIFPE (T-MIFPE) loss function, which incorporates an optimal scaling factor $T = t^*$ to minimize the impact of floating-point errors, thereby enhancing the accuracy of gradient computation in adversarial attacks. Extensive experiments on the MNIST, CIFAR-10, and CIFAR-100 datasets demonstrate that T-MIFPE outperforms existing loss functions, including CE, C\&W, DLR, and MIFPE, in terms of attack potency and robustness evaluation accuracy.
MORA: Improving Ensemble Robustness Evaluation with Model-Reweighing Attack
Nov 15, 2022Adversarial attacks can deceive neural networks by adding tiny perturbations to their input data. Ensemble defenses, which are trained to minimize attack transferability among sub-models, offer a promising research direction to improve robustness against such attacks while maintaining a high accuracy on natural inputs. We discover, however, that recent state-of-the-art (SOTA) adversarial attack strategies cannot reliably evaluate ensemble defenses, sizeably overestimating their robustness. This paper identifies the two factors that contribute to this behavior. First, these defenses form ensembles that are notably difficult for existing gradient-based method to attack, due to gradient obfuscation. Second, ensemble defenses diversify sub-model gradients, presenting a challenge to defeat all sub-models simultaneously, simply summing their contributions may counteract the overall attack objective; yet, we observe that ensemble may still be fooled despite most sub-models being correct. We therefore introduce MORA, a model-reweighing attack to steer adversarial example synthesis by reweighing the importance of sub-model gradients. MORA finds that recent ensemble defenses all exhibit varying degrees of overestimated robustness. Comparing it against recent SOTA white-box attacks, it can converge orders of magnitude faster while achieving higher attack success rates across all ensemble models examined with three different ensemble modes (i.e., ensembling by either softmax, voting or logits). In particular, most ensemble defenses exhibit near or exactly 0% robustness against MORA with $\ell^\infty$ perturbation within 0.02 on CIFAR-10, and 0.01 on CIFAR-100. We make MORA open source with reproducible results and pre-trained models; and provide a leaderboard of ensemble defenses under various attack strategies.
Adversarial Attacks on ML Defense Models Competition
Oct 15, 2021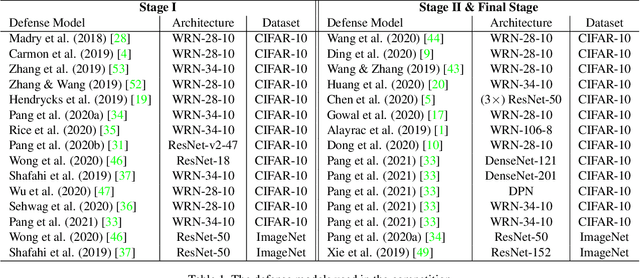
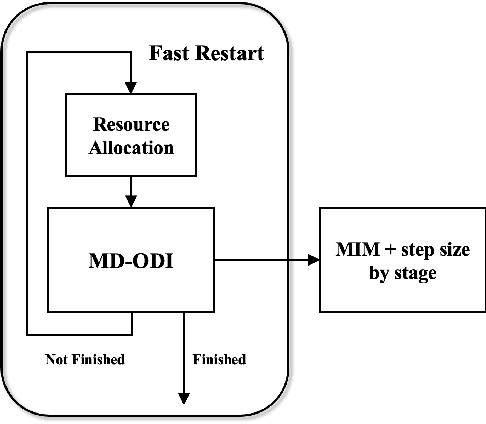
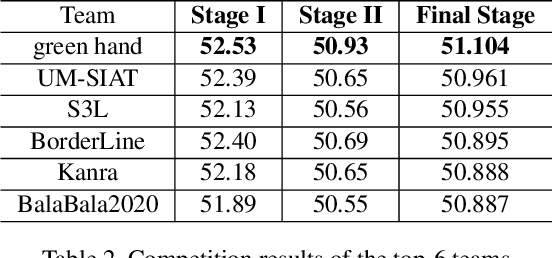
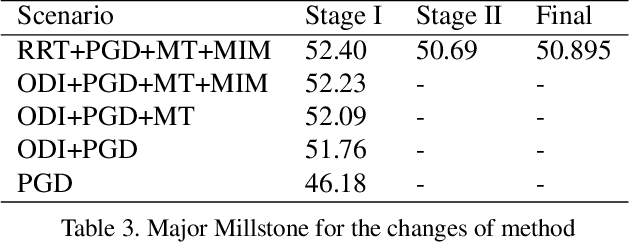
Due to the vulnerability of deep neural networks (DNNs) to adversarial examples, a large number of defense techniques have been proposed to alleviate this problem in recent years. However, the progress of building more robust models is usually hampered by the incomplete or incorrect robustness evaluation. To accelerate the research on reliable evaluation of adversarial robustness of the current defense models in image classification, the TSAIL group at Tsinghua University and the Alibaba Security group organized this competition along with a CVPR 2021 workshop on adversarial machine learning (https://aisecure-workshop.github.io/amlcvpr2021/). The purpose of this competition is to motivate novel attack algorithms to evaluate adversarial robustness more effectively and reliably. The participants were encouraged to develop stronger white-box attack algorithms to find the worst-case robustness of different defenses. This competition was conducted on an adversarial robustness evaluation platform -- ARES (https://github.com/thu-ml/ares), and is held on the TianChi platform (https://tianchi.aliyun.com/competition/entrance/531847/introduction) as one of the series of AI Security Challengers Program. After the competition, we summarized the results and established a new adversarial robustness benchmark at https://ml.cs.tsinghua.edu.cn/ares-bench/, which allows users to upload adversarial attack algorithms and defense models for evaluation.
LAFEAT: Piercing Through Adversarial Defenses with Latent Features
Apr 20, 2021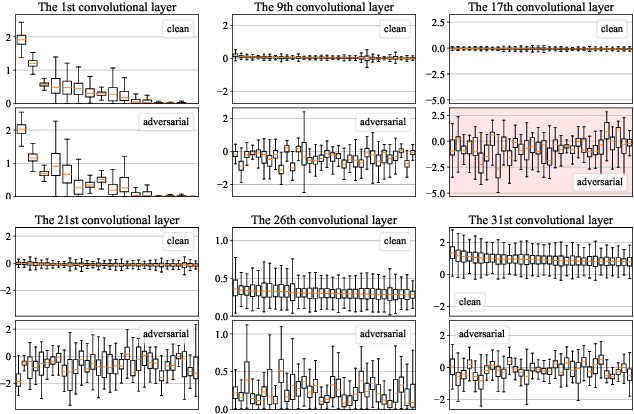
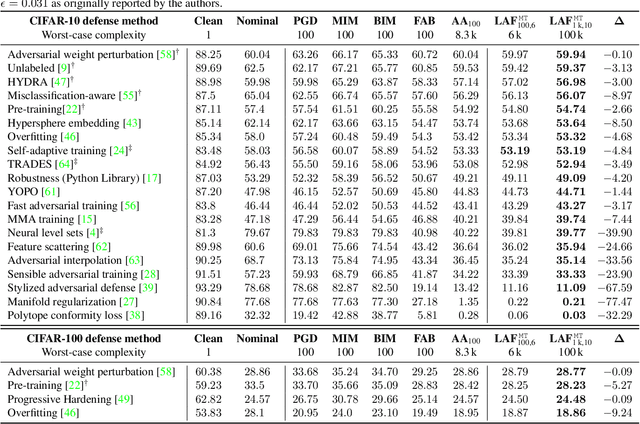
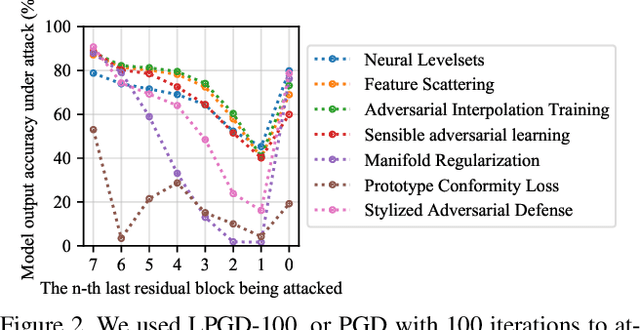

Deep convolutional neural networks are susceptible to adversarial attacks. They can be easily deceived to give an incorrect output by adding a tiny perturbation to the input. This presents a great challenge in making CNNs robust against such attacks. An influx of new defense techniques have been proposed to this end. In this paper, we show that latent features in certain "robust" models are surprisingly susceptible to adversarial attacks. On top of this, we introduce a unified $\ell_\infty$-norm white-box attack algorithm which harnesses latent features in its gradient descent steps, namely LAFEAT. We show that not only is it computationally much more efficient for successful attacks, but it is also a stronger adversary than the current state-of-the-art across a wide range of defense mechanisms. This suggests that model robustness could be contingent on the effective use of the defender's hidden components, and it should no longer be viewed from a holistic perspective.