 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDummy-Aware Weighted Attack (DAWA): Breaking the Safe Sink in Dummy Class Defenses
Mar 31, 2026Adversarial robustness evaluation faces a critical challenge as new defense paradigms emerge that can exploit limitations in existing assessment methods. This paper reveals that Dummy Classes-based defenses, which introduce an additional "dummy" class as a safety sink for adversarial examples, achieve significantly overestimated robustness under conventional evaluation strategies like AutoAttack. The fundamental limitation stems from these attacks' singular focus on misleading the true class label, which aligns perfectly with the defense mechanism--successful attacks are simply captured by the dummy class. To address this gap, we propose Dummy-Aware Weighted Attack (DAWA), a novel evaluation method that simultaneously targets both the true label and dummy label with adaptive weighting during adversarial example synthesis. Extensive experiments demonstrate that DAWA effectively breaks this defense paradigm, reducing the measured robustness of a leading Dummy Classes-based defense from 58.61% to 29.52% on CIFAR-10 under l_infty perturbation (epsilon=8/255). Our work provides a more reliable benchmark for evaluating this emerging class of defenses and highlights the need for continuous evolution of robustness assessment methodologies.
RCR-AF: Enhancing Model Generalization via Rademacher Complexity Reduction Activation Function
Jul 30, 2025Despite their widespread success, deep neural networks remain critically vulnerable to adversarial attacks, posing significant risks in safety-sensitive applications. This paper investigates activation functions as a crucial yet underexplored component for enhancing model robustness. We propose a Rademacher Complexity Reduction Activation Function (RCR-AF), a novel activation function designed to improve both generalization and adversarial resilience. RCR-AF uniquely combines the advantages of GELU (including smoothness, gradient stability, and negative information retention) with ReLU's desirable monotonicity, while simultaneously controlling both model sparsity and capacity through built-in clipping mechanisms governed by two hyperparameters, $\alpha$ and $\gamma$. Our theoretical analysis, grounded in Rademacher complexity, demonstrates that these parameters directly modulate the model's Rademacher complexity, offering a principled approach to enhance robustness. Comprehensive empirical evaluations show that RCR-AF consistently outperforms widely-used alternatives (ReLU, GELU, and Swish) in both clean accuracy under standard training and in adversarial robustness within adversarial training paradigms.
SparseDM: Toward Sparse Efficient Diffusion Models
Apr 16, 2024Diffusion models have been extensively used in data generation tasks and are recognized as one of the best generative models. However, their time-consuming deployment, long inference time, and requirements on large memory limit their application on mobile devices. In this paper, we propose a method based on the improved Straight-Through Estimator to improve the deployment efficiency of diffusion models. Specifically, we add sparse masks to the Convolution and Linear layers in a pre-trained diffusion model, then use design progressive sparsity for model training in the fine-tuning stage, and switch the inference mask on and off, which supports a flexible choice of sparsity during inference according to the FID and MACs requirements. Experiments on four datasets conducted on a state-of-the-art Transformer-based diffusion model demonstrate that our method reduces MACs by $50\%$ while increasing FID by only 1.5 on average. Under other MACs conditions, the FID is also lower than 1$\sim$137 compared to other methods.
Toward Efficient Automated Feature Engineering
Dec 26, 2022



Automated Feature Engineering (AFE) refers to automatically generate and select optimal feature sets for downstream tasks, which has achieved great success in real-world applications. Current AFE methods mainly focus on improving the effectiveness of the produced features, but ignoring the low-efficiency issue for large-scale deployment. Therefore, in this work, we propose a generic framework to improve the efficiency of AFE. Specifically, we construct the AFE pipeline based on reinforcement learning setting, where each feature is assigned an agent to perform feature transformation \com{and} selection, and the evaluation score of the produced features in downstream tasks serve as the reward to update the policy. We improve the efficiency of AFE in two perspectives. On the one hand, we develop a Feature Pre-Evaluation (FPE) Model to reduce the sample size and feature size that are two main factors on undermining the efficiency of feature evaluation. On the other hand, we devise a two-stage policy training strategy by running FPE on the pre-evaluation task as the initialization of the policy to avoid training policy from scratch. We conduct comprehensive experiments on 36 datasets in terms of both classification and regression tasks. The results show $2.9\%$ higher performance in average and 2x higher computational efficiency comparing to state-of-the-art AFE methods.
Learning Moving-Object Tracking with FMCW LiDAR
Mar 02, 2022

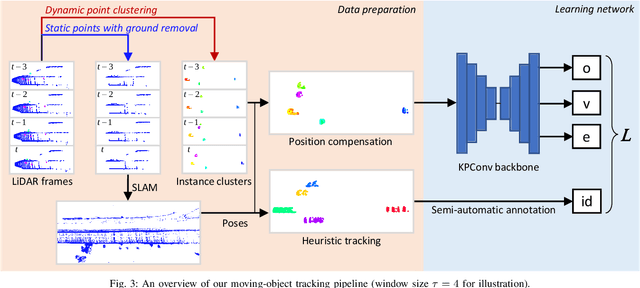
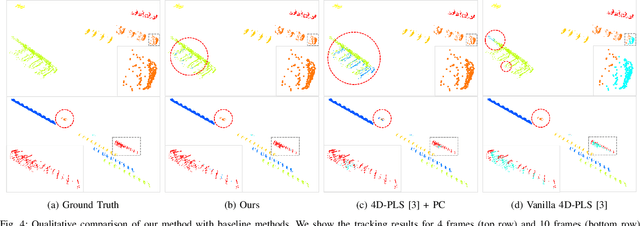
In this paper, we propose a learning-based moving-object tracking method utilizing our newly developed LiDAR sensor, Frequency Modulated Continuous Wave (FMCW) LiDAR. Compared with most existing commercial LiDAR sensors, our FMCW LiDAR can provide additional Doppler velocity information to each 3D point of the point clouds. Benefiting from this, we can generate instance labels as ground truth in a semi-automatic manner. Given the labels, we propose a contrastive learning framework, which pulls together the features from the same instance in embedding space and pushes apart the features from different instances, to improve the tracking quality. Extensive experiments are conducted on our recorded driving data, and the results show that our method outperforms the baseline methods by a large margin.
SenseMag: Enabling Low-Cost Traffic Monitoring using Non-invasive Magnetic Sensing
Oct 24, 2021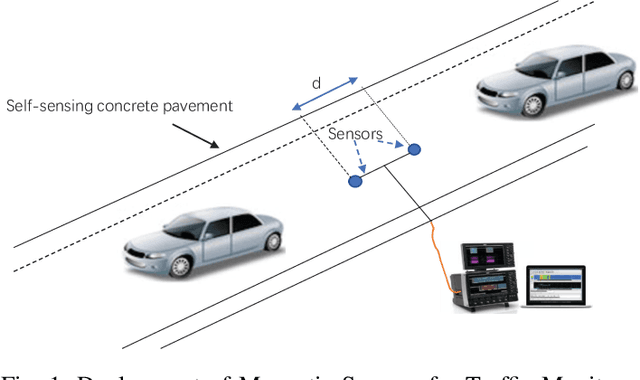

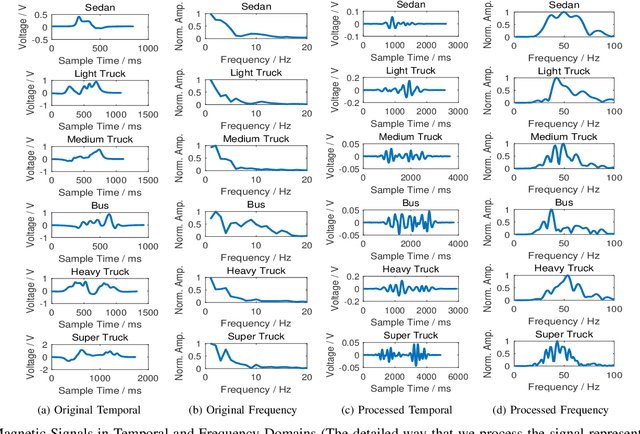
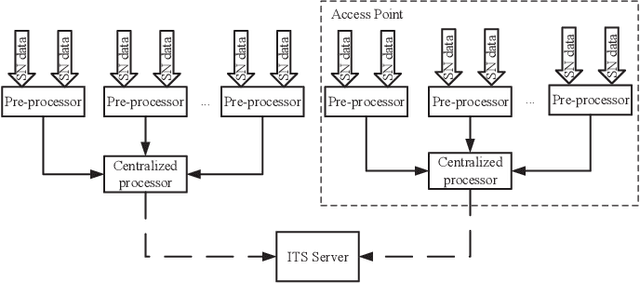
The operation and management of intelligent transportation systems (ITS), such as traffic monitoring, relies on real-time data aggregation of vehicular traffic information, including vehicular types (e.g., cars, trucks, and buses), in the critical roads and highways. While traditional approaches based on vehicular-embedded GPS sensors or camera networks would either invade drivers' privacy or require high deployment cost, this paper introduces a low-cost method, namely SenseMag, to recognize the vehicular type using a pair of non-invasive magnetic sensors deployed on the straight road section. SenseMag filters out noises and segments received magnetic signals by the exact time points that the vehicle arrives or departs from every sensor node. Further, SenseMag adopts a hierarchical recognition model to first estimate the speed/velocity, then identify the length of vehicle using the predicted speed, sampling cycles, and the distance between the sensor nodes. With the vehicle length identified and the temporal/spectral features extracted from the magnetic signals, SenseMag classify the types of vehicles accordingly. Some semi-automated learning techniques have been adopted for the design of filters, features, and the choice of hyper-parameters. Extensive experiment based on real-word field deployment (on the highways in Shenzhen, China) shows that SenseMag significantly outperforms the existing methods in both classification accuracy and the granularity of vehicle types (i.e., 7 types by SenseMag versus 4 types by the existing work in comparisons). To be specific, our field experiment results validate that SenseMag is with at least $90\%$ vehicle type classification accuracy and less than 5\% vehicle length classification error.