 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithm and Hardware Co-design for Reconfigurable CNN Accelerator
Nov 24, 2021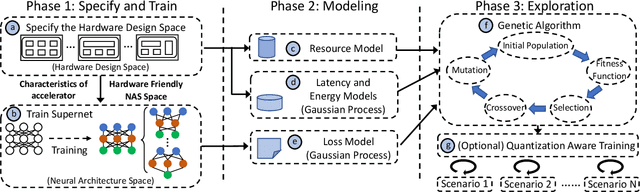
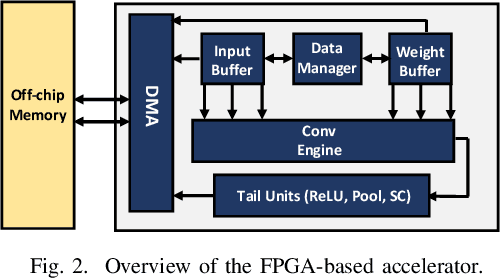
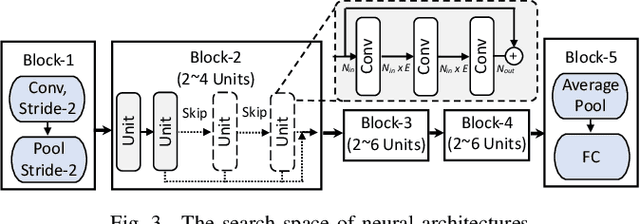
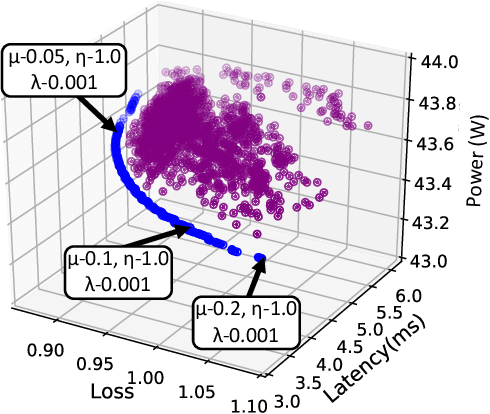
Recent advances in algorithm-hardware co-design for deep neural networks (DNNs) have demonstrated their potential in automatically designing neural architectures and hardware designs. Nevertheless, it is still a challenging optimization problem due to the expensive training cost and the time-consuming hardware implementation, which makes the exploration on the vast design space of neural architecture and hardware design intractable. In this paper, we demonstrate that our proposed approach is capable of locating designs on the Pareto frontier. This capability is enabled by a novel three-phase co-design framework, with the following new features: (a) decoupling DNN training from the design space exploration of hardware architecture and neural architecture, (b) providing a hardware-friendly neural architecture space by considering hardware characteristics in constructing the search cells, (c) adopting Gaussian process to predict accuracy, latency and power consumption to avoid time-consuming synthesis and place-and-route processes. In comparison with the manually-designed ResNet101, InceptionV2 and MobileNetV2, we can achieve up to 5% higher accuracy with up to 3x speed up on the ImageNet dataset. Compared with other state-of-the-art co-design frameworks, our found network and hardware configuration can achieve 2% ~ 6% higher accuracy, 2x ~ 26x smaller latency and 8.5x higher energy efficiency.
High-Performance FPGA-based Accelerator for Bayesian Neural Networks
May 12, 2021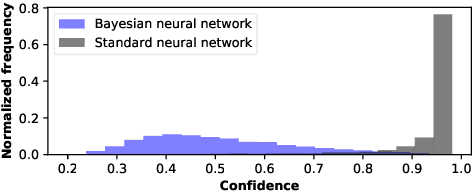
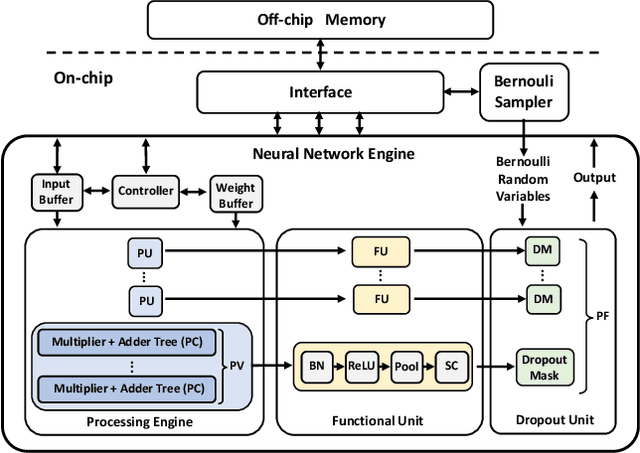
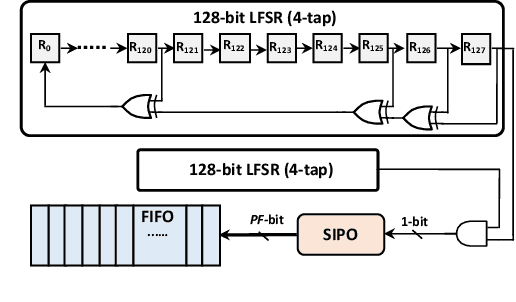
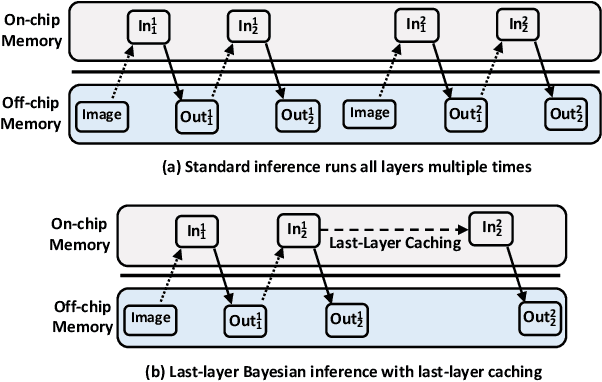
Neural networks (NNs) have demonstrated their potential in a wide range of applications such as image recognition, decision making or recommendation systems. However, standard NNs are unable to capture their model uncertainty which is crucial for many safety-critical applications including healthcare and autonomous vehicles. In comparison, Bayesian neural networks (BNNs) are able to express uncertainty in their prediction via a mathematical grounding. Nevertheless, BNNs have not been as widely used in industrial practice, mainly because of their expensive computational cost and limited hardware performance. This work proposes a novel FPGA-based hardware architecture to accelerate BNNs inferred through Monte Carlo Dropout. Compared with other state-of-the-art BNN accelerators, the proposed accelerator can achieve up to 4 times higher energy efficiency and 9 times better compute efficiency. Considering partial Bayesian inference, an automatic framework is proposed, which explores the trade-off between hardware and algorithmic performance. Extensive experiments are conducted to demonstrate that our proposed framework can effectively find the optimal points in the design space.
Deep Neural Network Approximation for Custom Hardware: Where We've Been, Where We're Going
Jan 21, 2019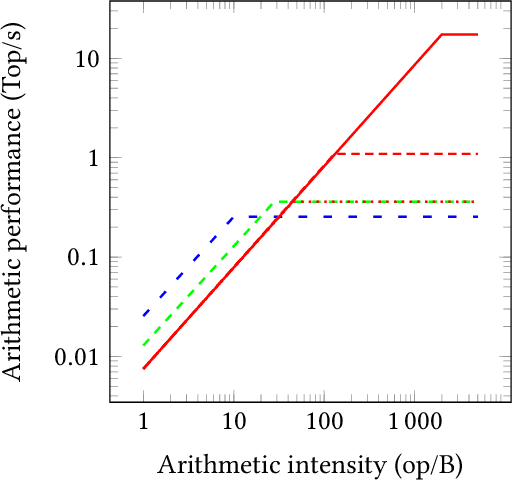
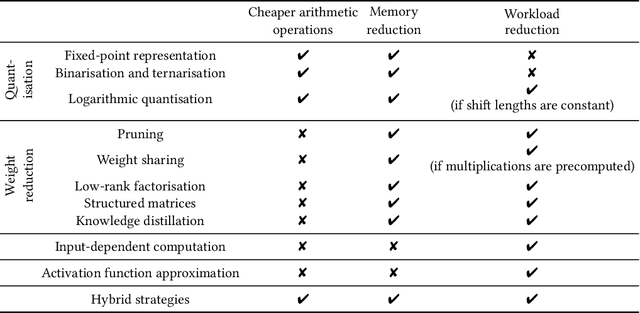
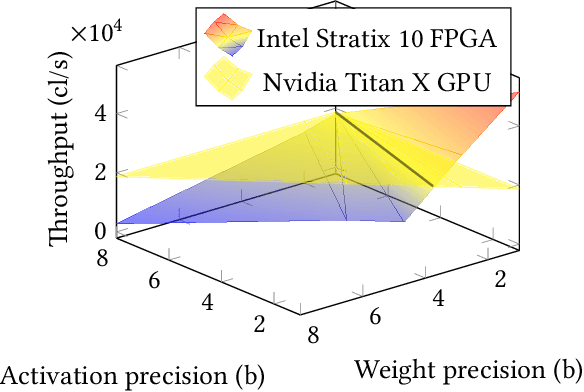
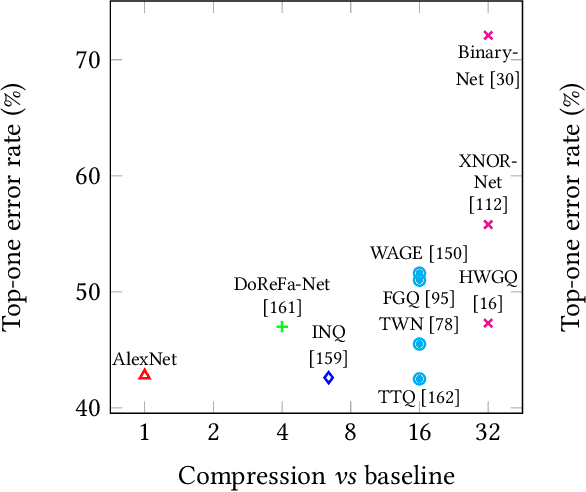
Deep neural networks have proven to be particularly effective in visual and audio recognition tasks. Existing models tend to be computationally expensive and memory intensive, however, and so methods for hardware-oriented approximation have become a hot topic. Research has shown that custom hardware-based neural network accelerators can surpass their general-purpose processor equivalents in terms of both throughput and energy efficiency. Application-tailored accelerators, when co-designed with approximation-based network training methods, transform large, dense and computationally expensive networks into small, sparse and hardware-efficient alternatives, increasing the feasibility of network deployment. In this article, we provide a comprehensive evaluation of approximation methods for high-performance network inference along with in-depth discussion of their effectiveness for custom hardware implementation. We also include proposals for future research based on a thorough analysis of current trends. This article represents the first survey providing detailed comparisons of custom hardware accelerators featuring approximation for both convolutional and recurrent neural networks, through which we hope to inspire exciting new developments in the field.
Towards Efficient Convolutional Neural Network for Domain-Specific Applications on FPGA
Sep 04, 2018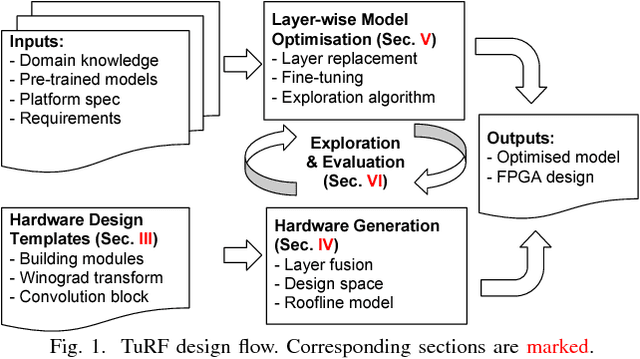
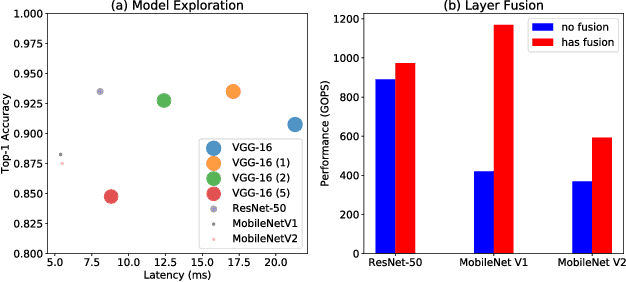
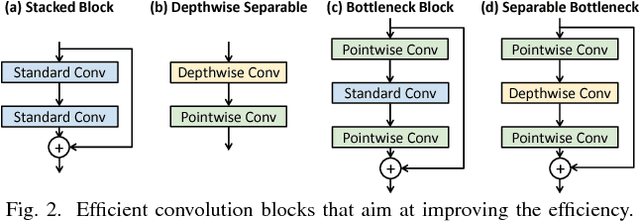
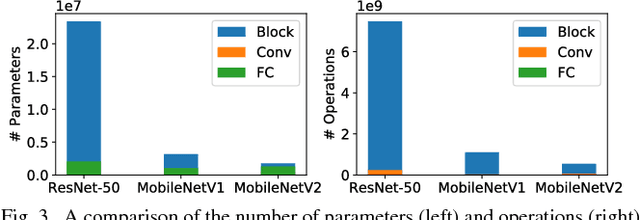
FPGA becomes a popular technology for implementing Convolutional Neural Network (CNN) in recent years. Most CNN applications on FPGA are domain-specific, e.g., detecting objects from specific categories, in which commonly-used CNN models pre-trained on general datasets may not be efficient enough. This paper presents TuRF, an end-to-end CNN acceleration framework to efficiently deploy domain-specific applications on FPGA by transfer learning that adapts pre-trained models to specific domains, replacing standard convolution layers with efficient convolution blocks, and applying layer fusion to enhance hardware design performance. We evaluate TuRF by deploying a pre-trained VGG-16 model for a domain-specific image recognition task onto a Stratix V FPGA. Results show that designs generated by TuRF achieve better performance than prior methods for the original VGG-16 and ResNet-50 models, while for the optimised VGG-16 model TuRF designs are more accurate and easier to process.