 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogic Shrinkage: Learned FPGA Netlist Sparsity for Efficient Neural Network Inference
Jan 02, 2022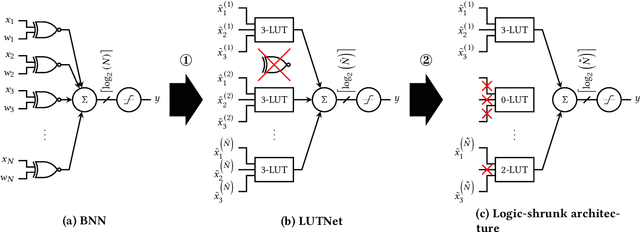
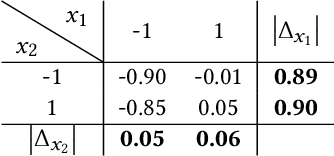
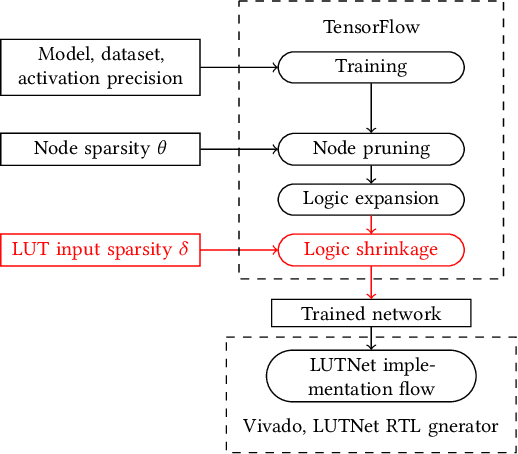

FPGA-specific DNN architectures using the native LUTs as independently trainable inference operators have been shown to achieve favorable area-accuracy and energy-accuracy tradeoffs. The first work in this area, LUTNet, exhibited state-of-the-art performance for standard DNN benchmarks. In this paper, we propose the learned optimization of such LUT-based topologies, resulting in higher-efficiency designs than via the direct use of off-the-shelf, hand-designed networks. Existing implementations of this class of architecture require the manual specification of the number of inputs per LUT, K. Choosing appropriate K a priori is challenging, and doing so at even high granularity, e.g. per layer, is a time-consuming and error-prone process that leaves FPGAs' spatial flexibility underexploited. Furthermore, prior works see LUT inputs connected randomly, which does not guarantee a good choice of network topology. To address these issues, we propose logic shrinkage, a fine-grained netlist pruning methodology enabling K to be automatically learned for every LUT in a neural network targeted for FPGA inference. By removing LUT inputs determined to be of low importance, our method increases the efficiency of the resultant accelerators. Our GPU-friendly solution to LUT input removal is capable of processing large topologies during their training with negligible slowdown. With logic shrinkage, we better the area and energy efficiency of the best-performing LUTNet implementation of the CNV network classifying CIFAR-10 by 1.54x and 1.31x, respectively, while matching its accuracy. This implementation also reaches 2.71x the area efficiency of an equally accurate, heavily pruned BNN. On ImageNet with the Bi-Real Net architecture, employment of logic shrinkage results in a post-synthesis area reduction of 2.67x vs LUTNet, allowing for implementation that was previously impossible on today's largest FPGAs.
Accelerating Recurrent Neural Networks for Gravitational Wave Experiments
Jun 26, 2021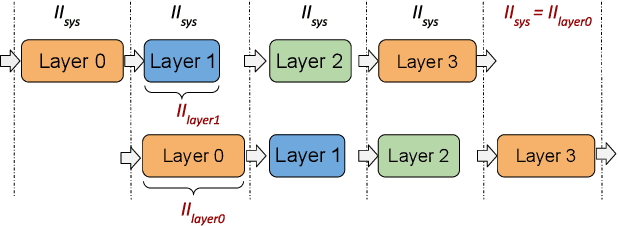
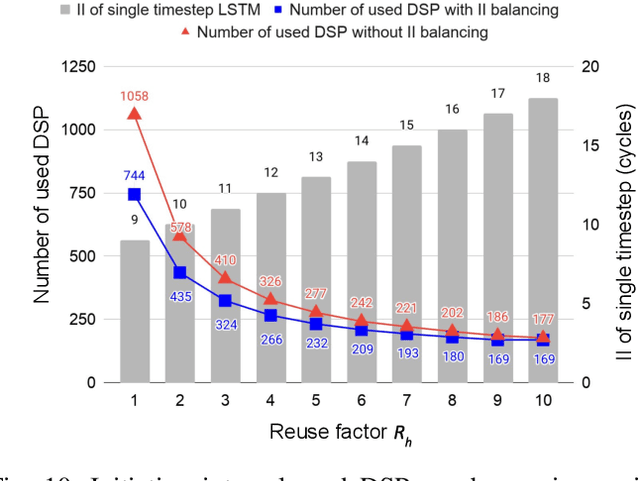
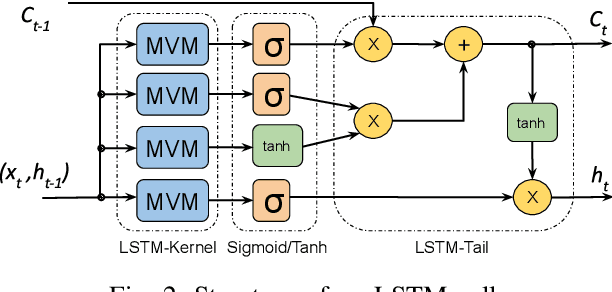
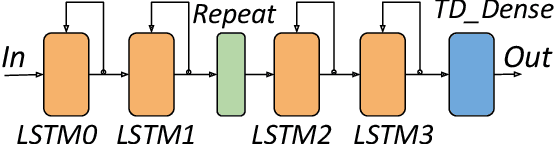
This paper presents novel reconfigurable architectures for reducing the latency of recurrent neural networks (RNNs) that are used for detecting gravitational waves. Gravitational interferometers such as the LIGO detectors capture cosmic events such as black hole mergers which happen at unknown times and of varying durations, producing time-series data. We have developed a new architecture capable of accelerating RNN inference for analyzing time-series data from LIGO detectors. This architecture is based on optimizing the initiation intervals (II) in a multi-layer LSTM (Long Short-Term Memory) network, by identifying appropriate reuse factors for each layer. A customizable template for this architecture has been designed, which enables the generation of low-latency FPGA designs with efficient resource utilization using high-level synthesis tools. The proposed approach has been evaluated based on two LSTM models, targeting a ZYNQ 7045 FPGA and a U250 FPGA. Experimental results show that with balanced II, the number of DSPs can be reduced up to 42% while achieving the same IIs. When compared to other FPGA-based LSTM designs, our design can achieve about 4.92 to 12.4 times lower latency.
Enabling Binary Neural Network Training on the Edge
Feb 10, 2021
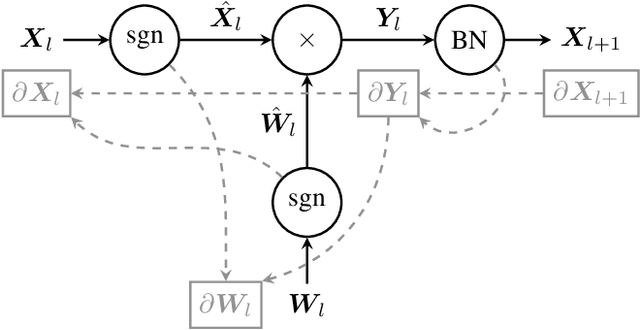
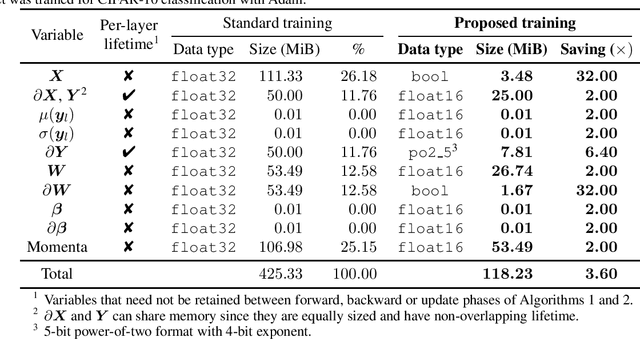
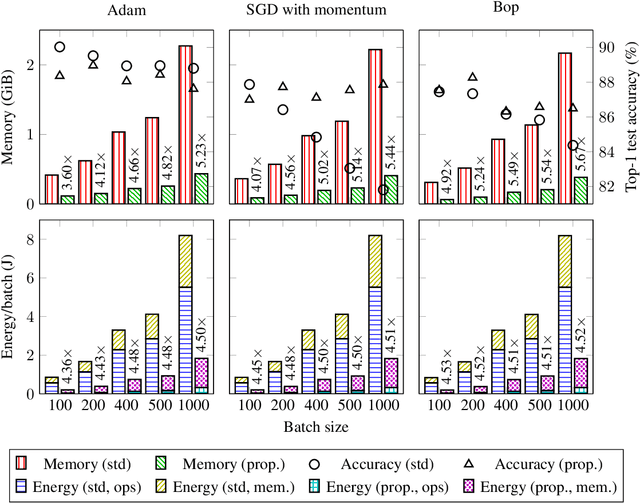
The ever-growing computational demands of increasingly complex machine learning models frequently necessitate the use of powerful cloud-based infrastructure for their training. Binary neural networks are known to be promising candidates for on-device inference due to their extreme compute and memory savings over higher-precision alternatives. In this paper, we demonstrate that they are also strongly robust to gradient quantization, thereby making the training of modern models on the edge a practical reality. We introduce a low-cost binary neural network training strategy exhibiting sizable memory footprint reductions and energy savings vs Courbariaux & Bengio's standard approach. Against the latter, we see coincident memory requirement and energy consumption drops of 2--6$\times$, while reaching similar test accuracy in comparable time, across a range of small-scale models trained to classify popular datasets. We also showcase ImageNet training of ResNetE-18, achieving a 3.12$\times$ memory reduction over the aforementioned standard. Such savings will allow for unnecessary cloud offloading to be avoided, reducing latency, increasing energy efficiency and safeguarding privacy.
LUTNet: Learning FPGA Configurations for Highly Efficient Neural Network Inference
Oct 24, 2019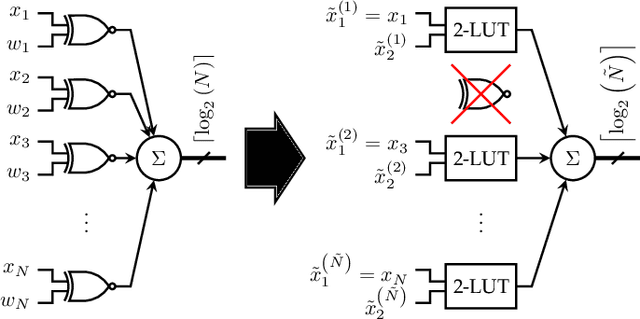

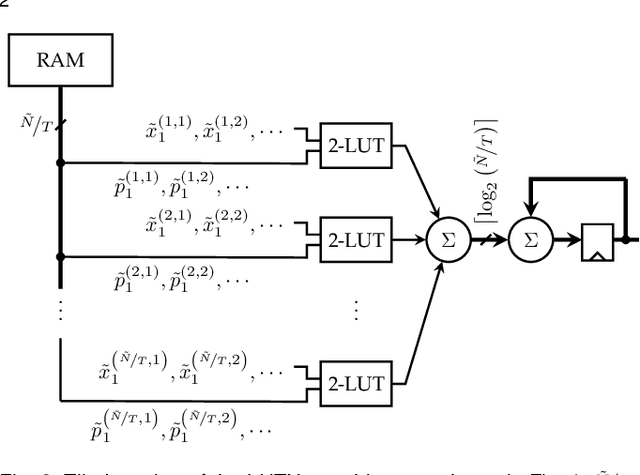
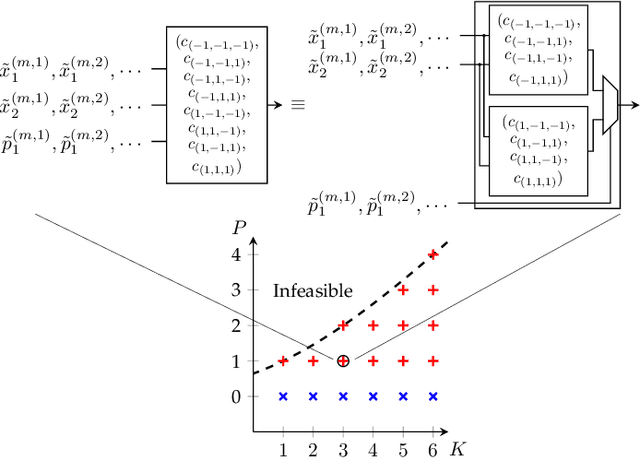
Research has shown that deep neural networks contain significant redundancy, and thus that high classification accuracy can be achieved even when weights and activations are quantised down to binary values. Network binarisation on FPGAs greatly increases area efficiency by replacing resource-hungry multipliers with lightweight XNOR gates. However, an FPGA's fundamental building block, the K-LUT, is capable of implementing far more than an XNOR: it can perform any K-input Boolean operation. Inspired by this observation, we propose LUTNet, an end-to-end hardware-software framework for the construction of area-efficient FPGA-based neural network accelerators using the native LUTs as inference operators. We describe the realisation of both unrolled and tiled LUTNet architectures, with the latter facilitating smaller, less power-hungry deployment over the former while sacrificing area and energy efficiency along with throughput. For both varieties, we demonstrate that the exploitation of LUT flexibility allows for far heavier pruning than possible in prior works, resulting in significant area savings while achieving comparable accuracy. Against the state-of-the-art binarised neural network implementation, we achieve up to twice the area efficiency for several standard network models when inferencing popular datasets. We also demonstrate that even greater energy efficiency improvements are obtainable.
Automatic Generation of Multi-precision Multi-arithmetic CNN Accelerators for FPGAs
Oct 21, 2019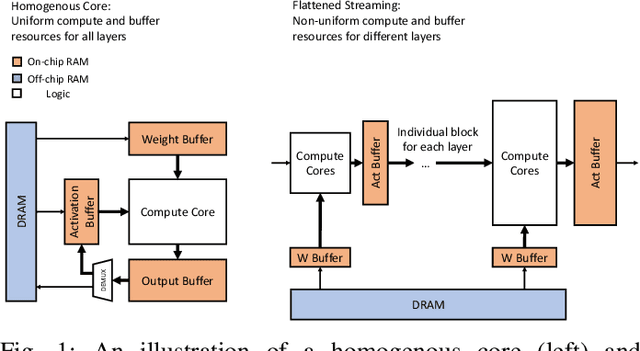
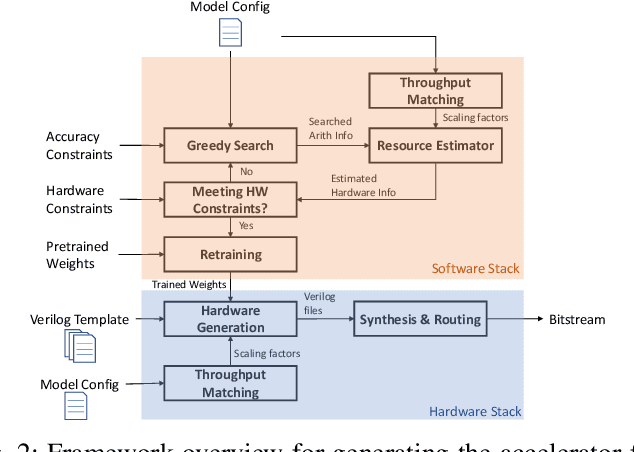
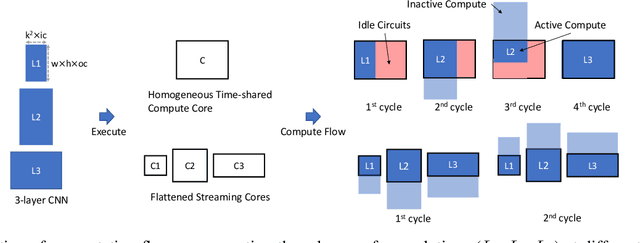
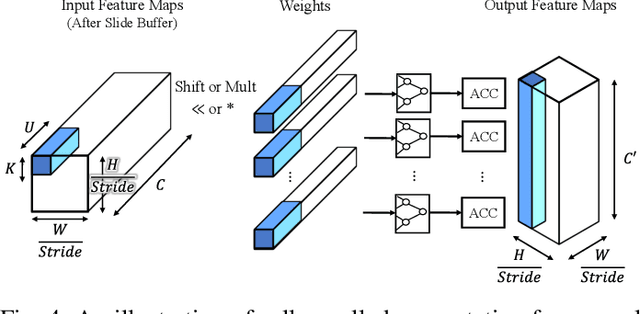
Modern deep Convolutional Neural Networks (CNNs) are computationally demanding, yet real applications often require high throughput and low latency. To help tackle these problems, we propose Tomato, a framework designed to automate the process of generating efficient CNN accelerators. The generated design is pipelined and each convolution layer uses different arithmetics at various precisions. Using Tomato, we showcase state-of-the-art multi-precision multi-arithmetic networks, including MobileNet-V1, running on FPGAs. To our knowledge, this is the first multi-precision multi-arithmetic auto-generation framework for CNNs. In software, Tomato fine-tunes pretrained networks to use a mixture of short powers-of-2 and fixed-point weights with a minimal loss in classification accuracy. The fine-tuned parameters are combined with the templated hardware designs to automatically produce efficient inference circuits in FPGAs. We demonstrate how our approach significantly reduces model sizes and computation complexities, and permits us to pack a complete ImageNet network onto a single FPGA without accessing off-chip memories for the first time. Furthermore, we show how Tomato produces implementations of networks with various sizes running on single or multiple FPGAs. To the best of our knowledge, our automatically generated accelerators outperform closest FPGA-based competitors by at least 2-4x for lantency and throughput; the generated accelerator runs ImageNet classification at a rate of more than 3000 frames per second.
LUTNet: Rethinking Inference in FPGA Soft Logic
Apr 01, 2019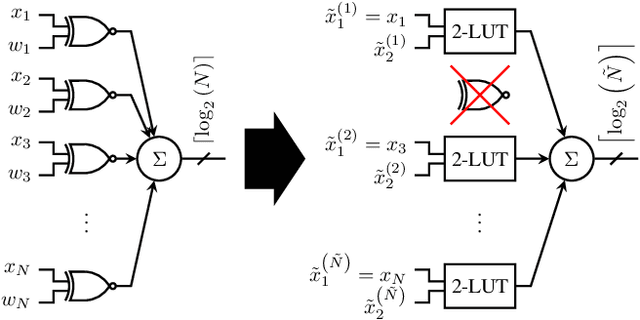
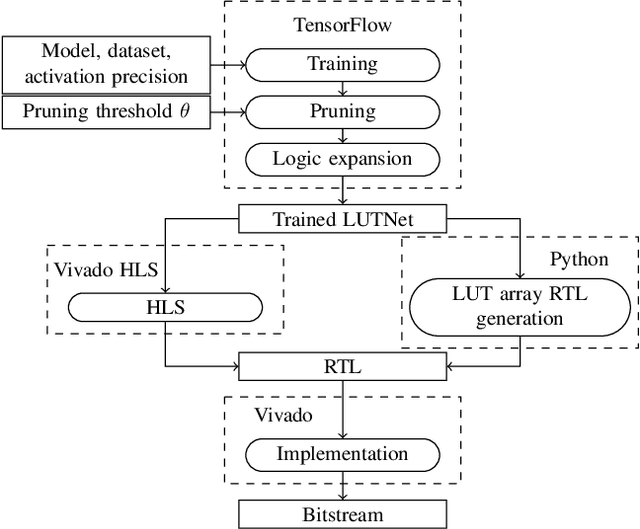
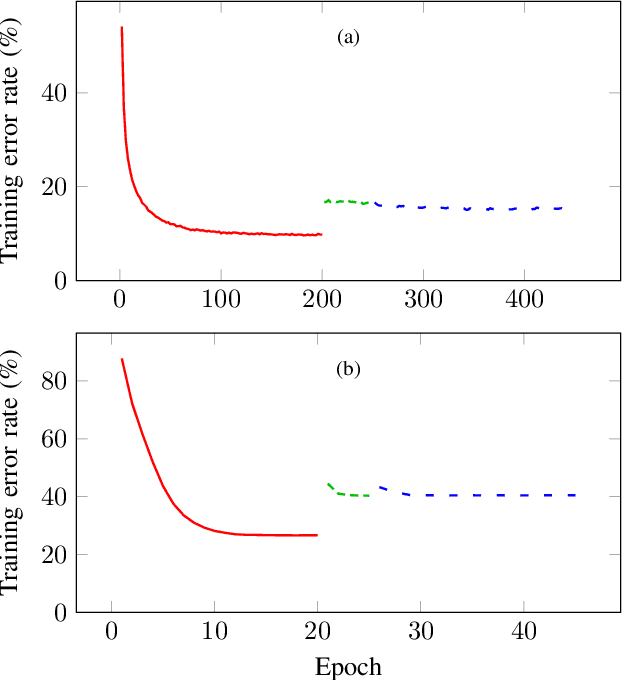
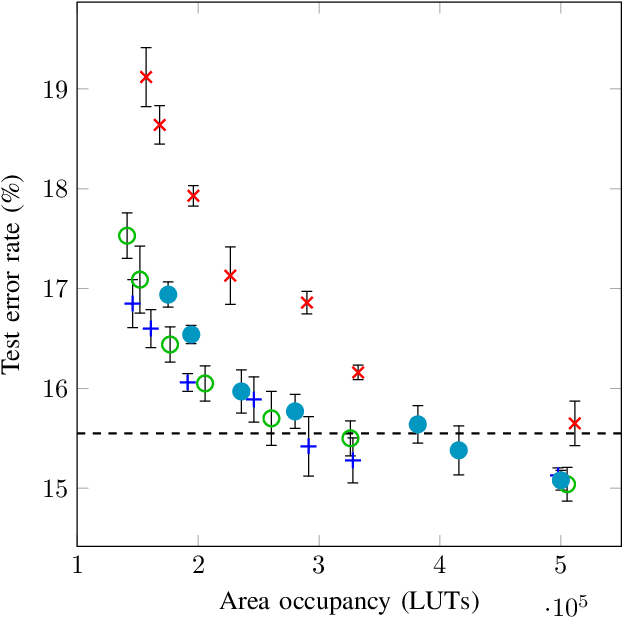
Research has shown that deep neural networks contain significant redundancy, and that high classification accuracies can be achieved even when weights and activations are quantised down to binary values. Network binarisation on FPGAs greatly increases area efficiency by replacing resource-hungry multipliers with lightweight XNOR gates. However, an FPGA's fundamental building block, the K-LUT, is capable of implementing far more than an XNOR: it can perform any K-input Boolean operation. Inspired by this observation, we propose LUTNet, an end-to-end hardware-software framework for the construction of area-efficient FPGA-based neural network accelerators using the native LUTs as inference operators. We demonstrate that the exploitation of LUT flexibility allows for far heavier pruning than possible in prior works, resulting in significant area savings while achieving comparable accuracy. Against the state-of-the-art binarised neural network implementation, we achieve twice the area efficiency for several standard network models when inferencing popular datasets. We also demonstrate that even greater energy efficiency improvements are obtainable.
Deep Neural Network Approximation for Custom Hardware: Where We've Been, Where We're Going
Jan 21, 2019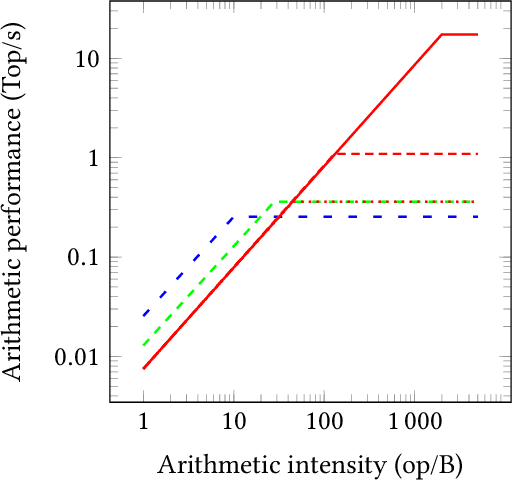
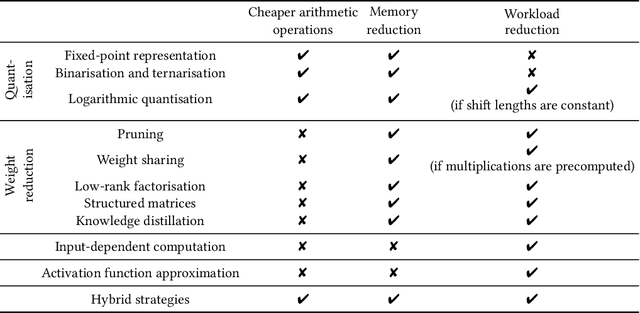
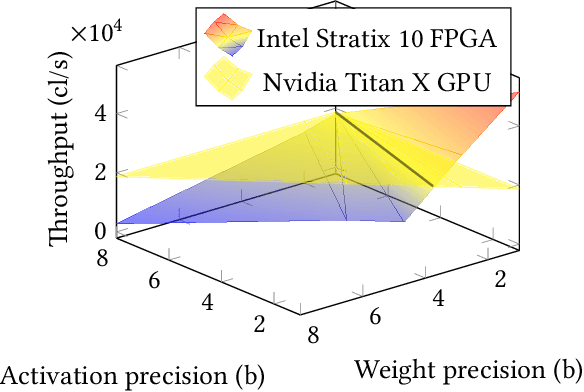
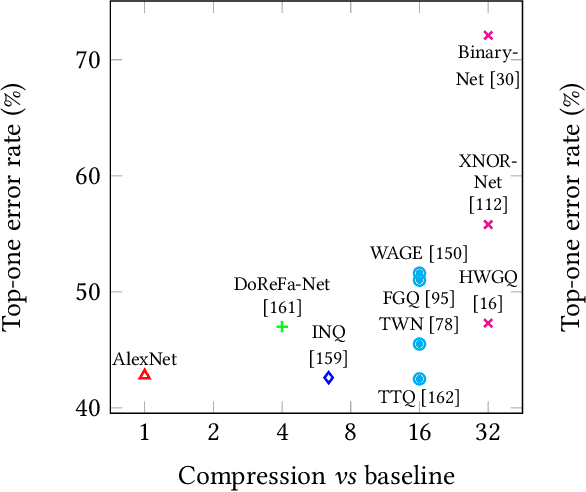
Deep neural networks have proven to be particularly effective in visual and audio recognition tasks. Existing models tend to be computationally expensive and memory intensive, however, and so methods for hardware-oriented approximation have become a hot topic. Research has shown that custom hardware-based neural network accelerators can surpass their general-purpose processor equivalents in terms of both throughput and energy efficiency. Application-tailored accelerators, when co-designed with approximation-based network training methods, transform large, dense and computationally expensive networks into small, sparse and hardware-efficient alternatives, increasing the feasibility of network deployment. In this article, we provide a comprehensive evaluation of approximation methods for high-performance network inference along with in-depth discussion of their effectiveness for custom hardware implementation. We also include proposals for future research based on a thorough analysis of current trends. This article represents the first survey providing detailed comparisons of custom hardware accelerators featuring approximation for both convolutional and recurrent neural networks, through which we hope to inspire exciting new developments in the field.