 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolution Based Spectral Partitioning Architecture for Hyperspectral Image Classification
Jun 27, 2019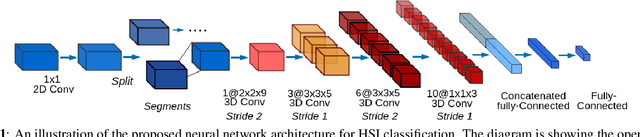
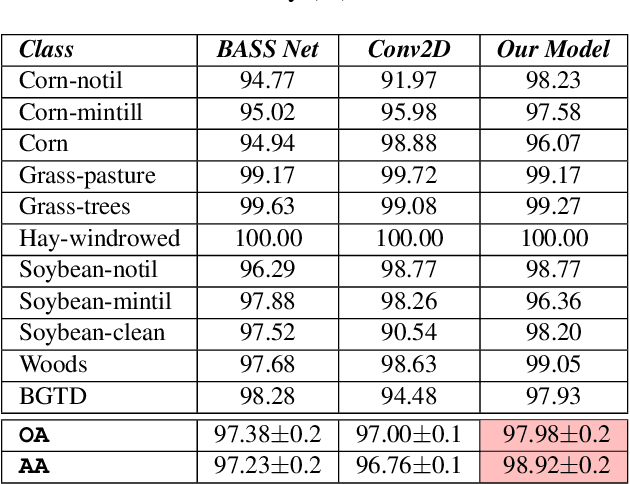
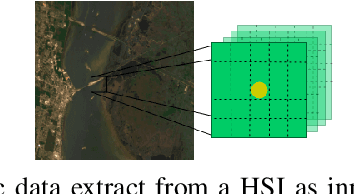
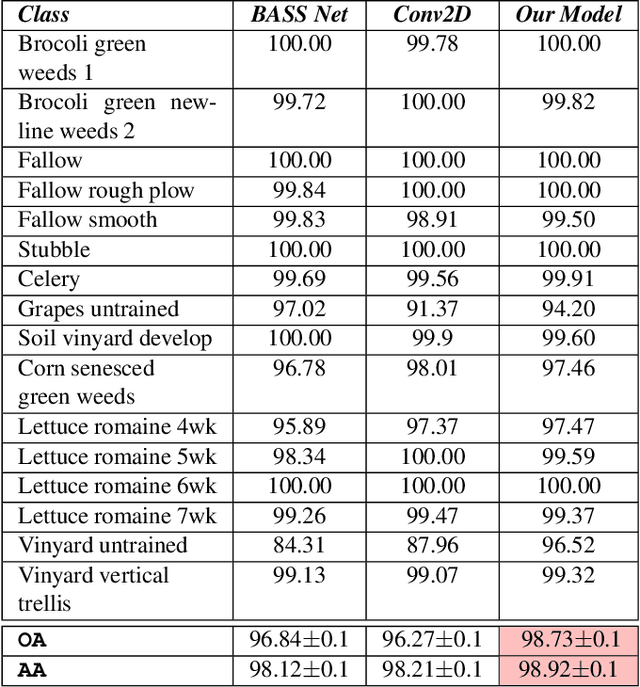
Hyperspectral images (HSIs) can distinguish materials with high number of spectral bands, which is widely adopted in remote sensing applications and benefits in high accuracy land cover classifications. However, HSIs processing are tangled with the problem of high dimensionality and limited amount of labelled data. To address these challenges, this paper proposes a deep learning architecture using three dimensional convolutional neural networks with spectral partitioning to perform effective feature extraction. We conduct experiments using Indian Pines and Salinas scenes acquired by NASA Airborne Visible/Infra-Red Imaging Spectrometer. In comparison to prior results, our architecture shows competitive performance for classification results over current methods.
Deep Neural Network Approximation for Custom Hardware: Where We've Been, Where We're Going
Jan 21, 2019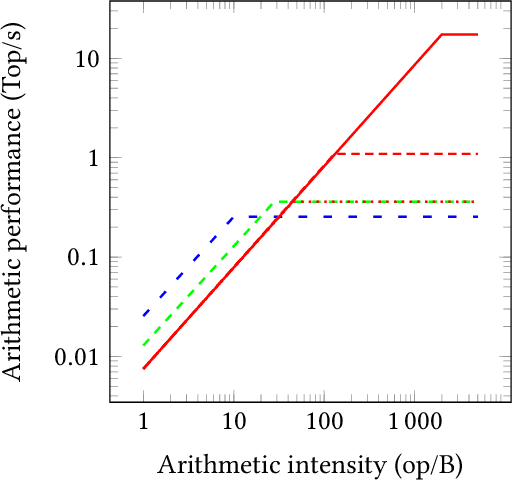
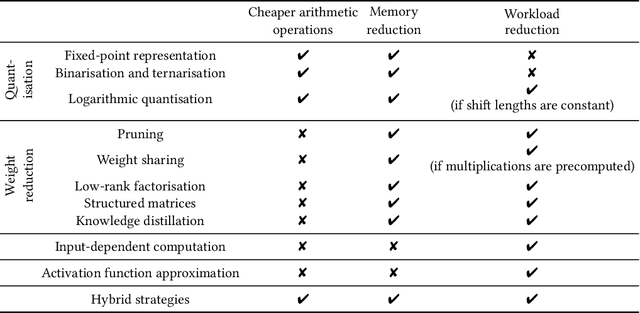
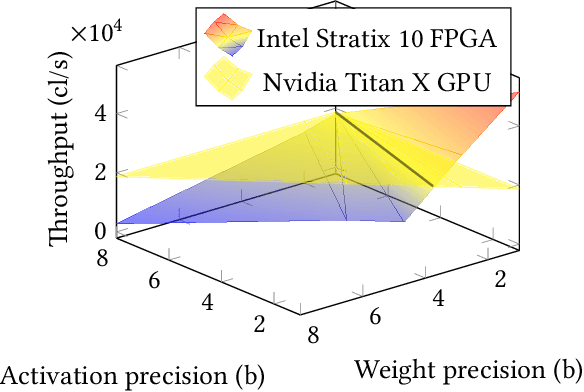
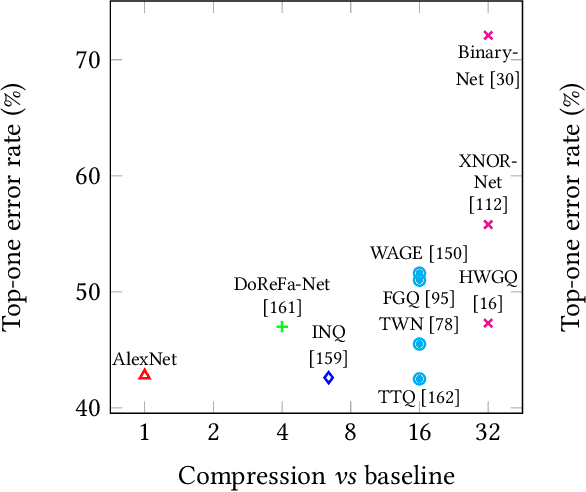
Deep neural networks have proven to be particularly effective in visual and audio recognition tasks. Existing models tend to be computationally expensive and memory intensive, however, and so methods for hardware-oriented approximation have become a hot topic. Research has shown that custom hardware-based neural network accelerators can surpass their general-purpose processor equivalents in terms of both throughput and energy efficiency. Application-tailored accelerators, when co-designed with approximation-based network training methods, transform large, dense and computationally expensive networks into small, sparse and hardware-efficient alternatives, increasing the feasibility of network deployment. In this article, we provide a comprehensive evaluation of approximation methods for high-performance network inference along with in-depth discussion of their effectiveness for custom hardware implementation. We also include proposals for future research based on a thorough analysis of current trends. This article represents the first survey providing detailed comparisons of custom hardware accelerators featuring approximation for both convolutional and recurrent neural networks, through which we hope to inspire exciting new developments in the field.
Towards Efficient Convolutional Neural Network for Domain-Specific Applications on FPGA
Sep 04, 2018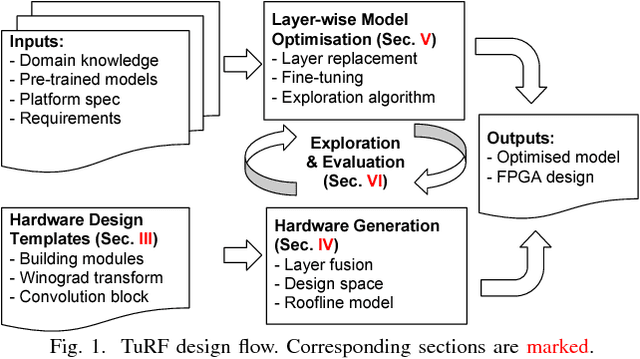
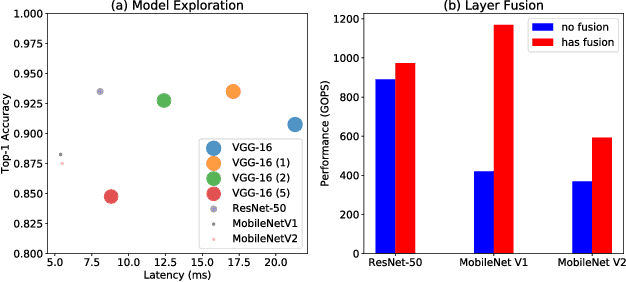
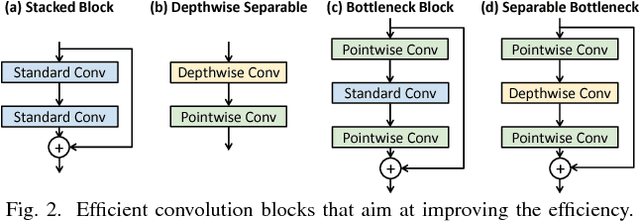
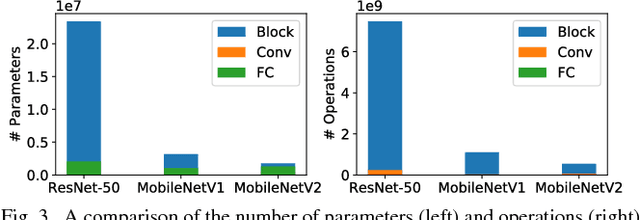
FPGA becomes a popular technology for implementing Convolutional Neural Network (CNN) in recent years. Most CNN applications on FPGA are domain-specific, e.g., detecting objects from specific categories, in which commonly-used CNN models pre-trained on general datasets may not be efficient enough. This paper presents TuRF, an end-to-end CNN acceleration framework to efficiently deploy domain-specific applications on FPGA by transfer learning that adapts pre-trained models to specific domains, replacing standard convolution layers with efficient convolution blocks, and applying layer fusion to enhance hardware design performance. We evaluate TuRF by deploying a pre-trained VGG-16 model for a domain-specific image recognition task onto a Stratix V FPGA. Results show that designs generated by TuRF achieve better performance than prior methods for the original VGG-16 and ResNet-50 models, while for the optimised VGG-16 model TuRF designs are more accurate and easier to process.