 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvidential Deep Learning for Uncertainty Quantification and Out-of-Distribution Detection in Jet Identification using Deep Neural Networks
Jan 10, 2025



Current methods commonly used for uncertainty quantification (UQ) in deep learning (DL) models utilize Bayesian methods which are computationally expensive and time-consuming. In this paper, we provide a detailed study of UQ based on evidential deep learning (EDL) for deep neural network models designed to identify jets in high energy proton-proton collisions at the Large Hadron Collider and explore its utility in anomaly detection. EDL is a DL approach that treats learning as an evidence acquisition process designed to provide confidence (or epistemic uncertainty) about test data. Using publicly available datasets for jet classification benchmarking, we explore hyperparameter optimizations for EDL applied to the challenge of UQ for jet identification. We also investigate how the uncertainty is distributed for each jet class, how this method can be implemented for the detection of anomalies, how the uncertainty compares with Bayesian ensemble methods, and how the uncertainty maps onto latent spaces for the models. Our studies uncover some pitfalls of EDL applied to anomaly detection and a more effective way to quantify uncertainty from EDL as compared with the foundational EDL setup. These studies illustrate a methodological approach to interpreting EDL in jet classification models, providing new insights on how EDL quantifies uncertainty and detects out-of-distribution data which may lead to improved EDL methods for DL models applied to classification tasks.
Exploiting Spline Models for the Training of Fully Connected Layers in Neural Network
Feb 12, 2021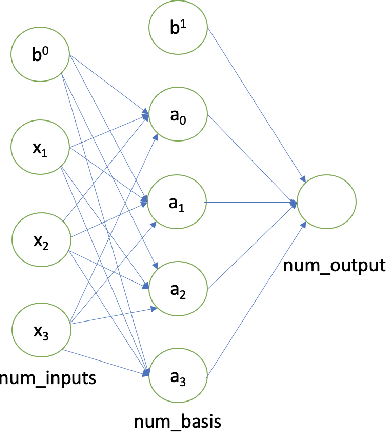

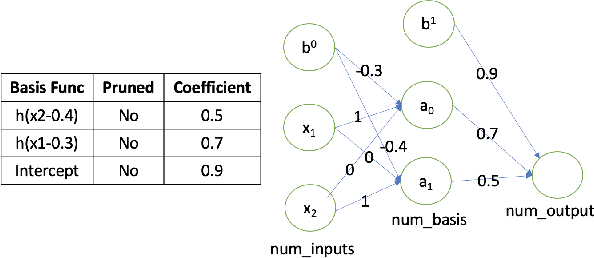
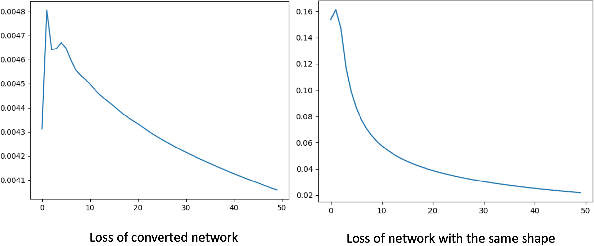
The fully connected (FC) layer, one of the most fundamental modules in artificial neural networks (ANN), is often considered difficult and inefficient to train due to issues including the risk of overfitting caused by its large amount of parameters. Based on previous work studying ANN from linear spline perspectives, we propose a spline-based approach that eases the difficulty of training FC layers. Given some dataset, we first obtain a continuous piece-wise linear (CPWL) fit through spline methods such as multivariate adaptive regression spline (MARS). Next, we construct an ANN model from the linear spline model and continue to train the ANN model on the dataset using gradient descent optimization algorithms. Our experimental results and theoretical analysis show that our approach reduces the computational cost, accelerates the convergence of FC layers, and significantly increases the interpretability of the resulting model (FC layers) compared with standard ANN training with random parameter initialization followed by gradient descent optimizations.
Convolution Based Spectral Partitioning Architecture for Hyperspectral Image Classification
Jun 27, 2019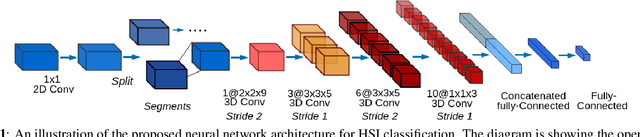
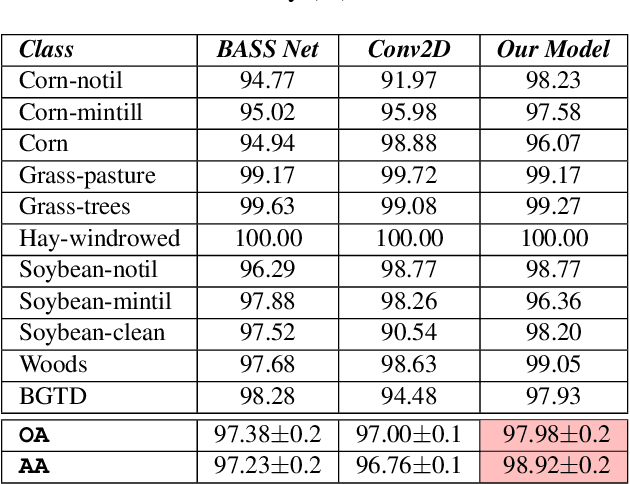
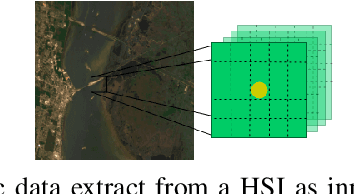
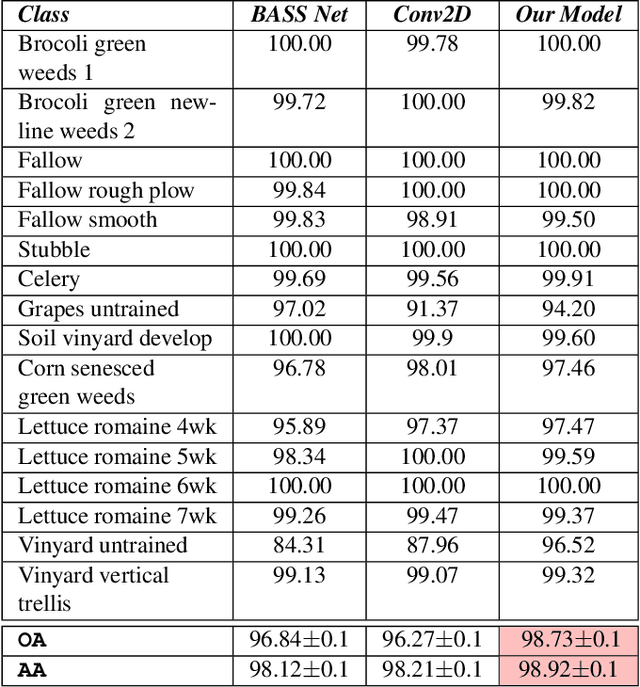
Hyperspectral images (HSIs) can distinguish materials with high number of spectral bands, which is widely adopted in remote sensing applications and benefits in high accuracy land cover classifications. However, HSIs processing are tangled with the problem of high dimensionality and limited amount of labelled data. To address these challenges, this paper proposes a deep learning architecture using three dimensional convolutional neural networks with spectral partitioning to perform effective feature extraction. We conduct experiments using Indian Pines and Salinas scenes acquired by NASA Airborne Visible/Infra-Red Imaging Spectrometer. In comparison to prior results, our architecture shows competitive performance for classification results over current methods.
Optimizing CNN-based Hyperspectral ImageClassification on FPGAs
Jun 27, 2019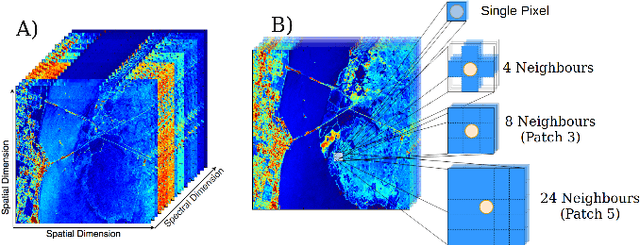
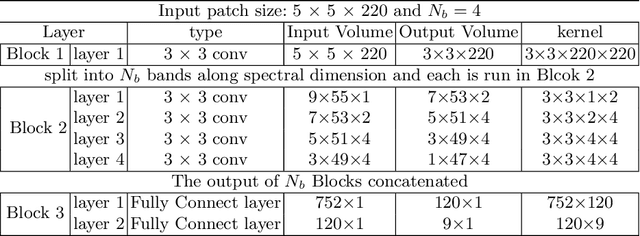
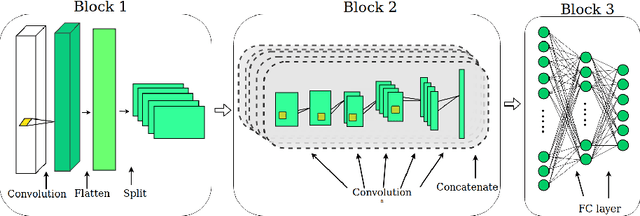
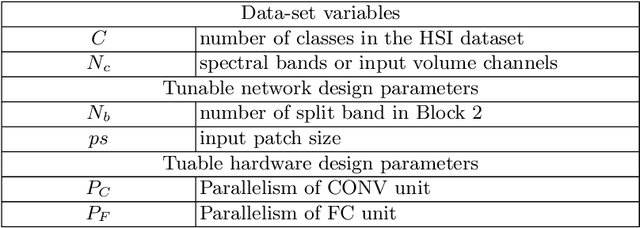
Hyperspectral image (HSI) classification has been widely adopted in applications involving remote sensing imagery analysis which require high classification accuracy and real-time processing speed. Methods based on Convolutional neural networks (CNNs) have been proven to achieve state-of-the-art accuracy in classifying HSIs. However, CNN models are often too computationally intensive to achieve real-time response due to the high dimensional nature of HSI, compared to traditional methods such as Support Vector Machines (SVMs). Besides, previous CNN models used in HSI are not specially designed for efficient implementation on embedded devices such as FPGAs. This paper proposes a novel CNN-based algorithm for HSI classification which takes into account hardware efficiency. A customized architecture which enables the proposed algorithm to be mapped effectively onto FPGA resources is then proposed to support real-time on-board classification with low power consumption. Implementation results show that our proposed accelerator on a Xilinx Zynq 706 FPGA board achieves more than 70x faster than an Intel 8-core Xeon CPU and 3x faster than an NVIDIA GeForce 1080 GPU. Compared to previous SVM-based FPGA accelerators, we achieve comparable processing speed but provide a much higher classification accuracy.