 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUp to 100x Faster Data-free Knowledge Distillation
Dec 12, 2021
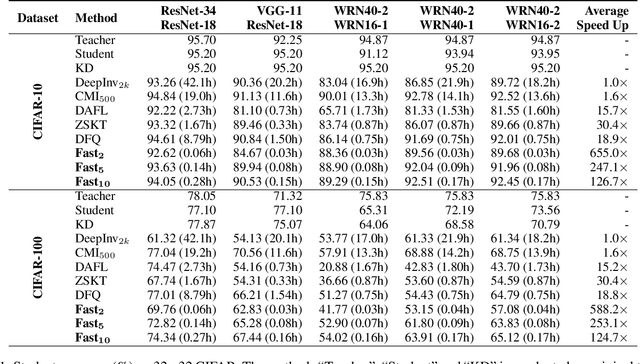
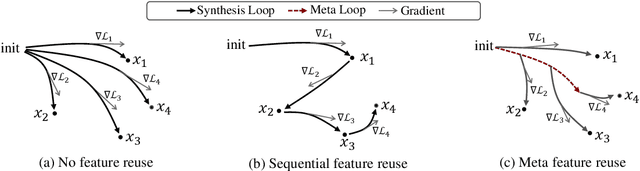

Data-free knowledge distillation (DFKD) has recently been attracting increasing attention from research communities, attributed to its capability to compress a model only using synthetic data. Despite the encouraging results achieved, state-of-the-art DFKD methods still suffer from the inefficiency of data synthesis, making the data-free training process extremely time-consuming and thus inapplicable for large-scale tasks. In this work, we introduce an efficacious scheme, termed as FastDFKD, that allows us to accelerate DFKD by a factor of orders of magnitude. At the heart of our approach is a novel strategy to reuse the shared common features in training data so as to synthesize different data instances. Unlike prior methods that optimize a set of data independently, we propose to learn a meta-synthesizer that seeks common features as the initialization for the fast data synthesis. As a result, FastDFKD achieves data synthesis within only a few steps, significantly enhancing the efficiency of data-free training. Experiments over CIFAR, NYUv2, and ImageNet demonstrate that the proposed FastDFKD achieves 10$\times$ and even 100$\times$ acceleration while preserving performances on par with state of the art.
Exploiting Spline Models for the Training of Fully Connected Layers in Neural Network
Feb 12, 2021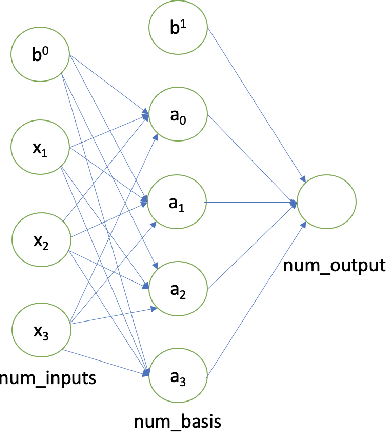

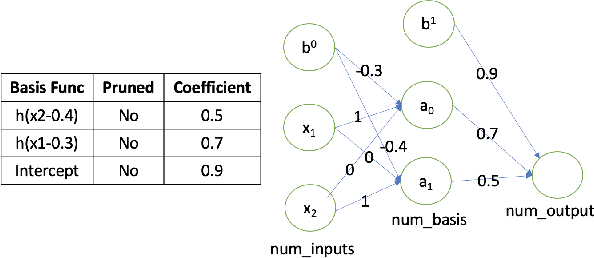
The fully connected (FC) layer, one of the most fundamental modules in artificial neural networks (ANN), is often considered difficult and inefficient to train due to issues including the risk of overfitting caused by its large amount of parameters. Based on previous work studying ANN from linear spline perspectives, we propose a spline-based approach that eases the difficulty of training FC layers. Given some dataset, we first obtain a continuous piece-wise linear (CPWL) fit through spline methods such as multivariate adaptive regression spline (MARS). Next, we construct an ANN model from the linear spline model and continue to train the ANN model on the dataset using gradient descent optimization algorithms. Our experimental results and theoretical analysis show that our approach reduces the computational cost, accelerates the convergence of FC layers, and significantly increases the interpretability of the resulting model (FC layers) compared with standard ANN training with random parameter initialization followed by gradient descent optimizations.