 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Calibration and Ground Truth Estimation for High-Precision SLAM Benchmarking in Extended Reality
Dec 08, 2025Simultaneous localization and mapping (SLAM) plays a fundamental role in extended reality (XR) applications. As the standards for immersion in XR continue to increase, the demands for SLAM benchmarking have become more stringent. Trajectory accuracy is the key metric, and marker-based optical motion capture (MoCap) systems are widely used to generate ground truth (GT) because of their drift-free and relatively accurate measurements. However, the precision of MoCap-based GT is limited by two factors: the spatiotemporal calibration with the device under test (DUT) and the inherent jitter in the MoCap measurements. These limitations hinder accurate SLAM benchmarking, particularly for key metrics like rotation error and inter-frame jitter, which are critical for immersive XR experiences. This paper presents a novel continuous-time maximum likelihood estimator to address these challenges. The proposed method integrates auxiliary inertial measurement unit (IMU) data to compensate for MoCap jitter. Additionally, a variable time synchronization method and a pose residual based on screw congruence constraints are proposed, enabling precise spatiotemporal calibration across multiple sensors and the DUT. Experimental results demonstrate that our approach outperforms existing methods, achieving the precision necessary for comprehensive benchmarking of state-of-the-art SLAM algorithms in XR applications. Furthermore, we thoroughly validate the practicality of our method by benchmarking several leading XR devices and open-source SLAM algorithms. The code is publicly available at https://github.com/ylab-xrpg/xr-hpgt.
Up to 100x Faster Data-free Knowledge Distillation
Dec 12, 2021
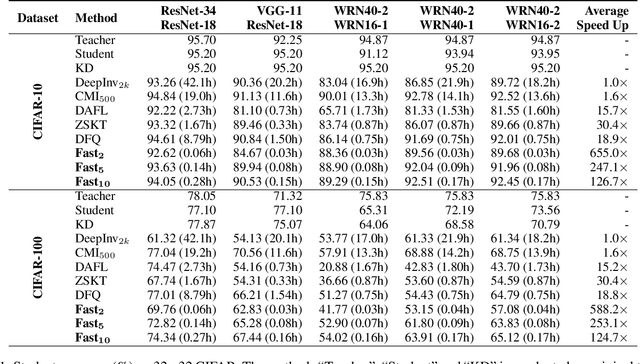
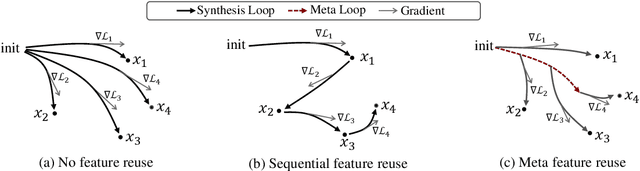

Data-free knowledge distillation (DFKD) has recently been attracting increasing attention from research communities, attributed to its capability to compress a model only using synthetic data. Despite the encouraging results achieved, state-of-the-art DFKD methods still suffer from the inefficiency of data synthesis, making the data-free training process extremely time-consuming and thus inapplicable for large-scale tasks. In this work, we introduce an efficacious scheme, termed as FastDFKD, that allows us to accelerate DFKD by a factor of orders of magnitude. At the heart of our approach is a novel strategy to reuse the shared common features in training data so as to synthesize different data instances. Unlike prior methods that optimize a set of data independently, we propose to learn a meta-synthesizer that seeks common features as the initialization for the fast data synthesis. As a result, FastDFKD achieves data synthesis within only a few steps, significantly enhancing the efficiency of data-free training. Experiments over CIFAR, NYUv2, and ImageNet demonstrate that the proposed FastDFKD achieves 10$\times$ and even 100$\times$ acceleration while preserving performances on par with state of the art.