 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Calibration and Ground Truth Estimation for High-Precision SLAM Benchmarking in Extended Reality
Dec 08, 2025Simultaneous localization and mapping (SLAM) plays a fundamental role in extended reality (XR) applications. As the standards for immersion in XR continue to increase, the demands for SLAM benchmarking have become more stringent. Trajectory accuracy is the key metric, and marker-based optical motion capture (MoCap) systems are widely used to generate ground truth (GT) because of their drift-free and relatively accurate measurements. However, the precision of MoCap-based GT is limited by two factors: the spatiotemporal calibration with the device under test (DUT) and the inherent jitter in the MoCap measurements. These limitations hinder accurate SLAM benchmarking, particularly for key metrics like rotation error and inter-frame jitter, which are critical for immersive XR experiences. This paper presents a novel continuous-time maximum likelihood estimator to address these challenges. The proposed method integrates auxiliary inertial measurement unit (IMU) data to compensate for MoCap jitter. Additionally, a variable time synchronization method and a pose residual based on screw congruence constraints are proposed, enabling precise spatiotemporal calibration across multiple sensors and the DUT. Experimental results demonstrate that our approach outperforms existing methods, achieving the precision necessary for comprehensive benchmarking of state-of-the-art SLAM algorithms in XR applications. Furthermore, we thoroughly validate the practicality of our method by benchmarking several leading XR devices and open-source SLAM algorithms. The code is publicly available at https://github.com/ylab-xrpg/xr-hpgt.
A Spatiotemporal Hand-Eye Calibration for Trajectory Alignment in Visual(-Inertial) Odometry Evaluation
Apr 23, 2024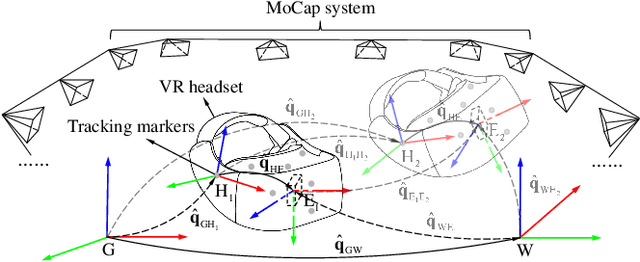
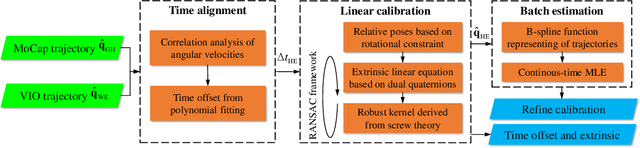
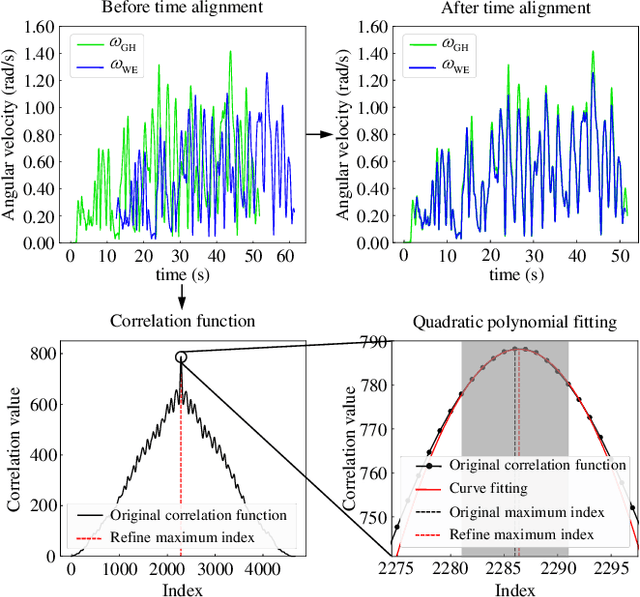

A common prerequisite for evaluating a visual(-inertial) odometry (VO/VIO) algorithm is to align the timestamps and the reference frame of its estimated trajectory with a reference ground-truth derived from a system of superior precision, such as a motion capture system. The trajectory-based alignment, typically modeled as a classic hand-eye calibration, significantly influences the accuracy of evaluation metrics. However, traditional calibration methods are susceptible to the quality of the input poses. Few studies have taken this into account when evaluating VO/VIO trajectories that usually suffer from noise and drift. To fill this gap, we propose a novel spatiotemporal hand-eye calibration algorithm that fully leverages multiple constraints from screw theory for enhanced accuracy and robustness. Experimental results show that our algorithm has better performance and is less noise-prone than state-of-the-art methods.
* 8 pages, 9 figures, 2 tables
WeedMap: A large-scale semantic weed mapping framework using aerial multispectral imaging and deep neural network for precision farming
Sep 06, 2018
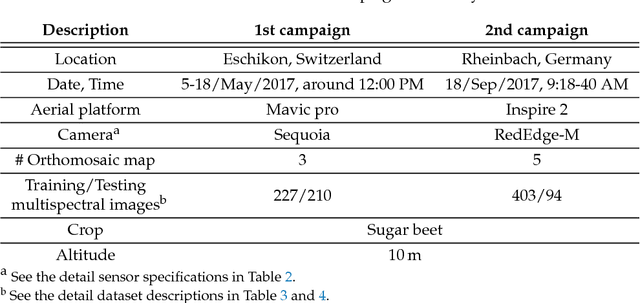
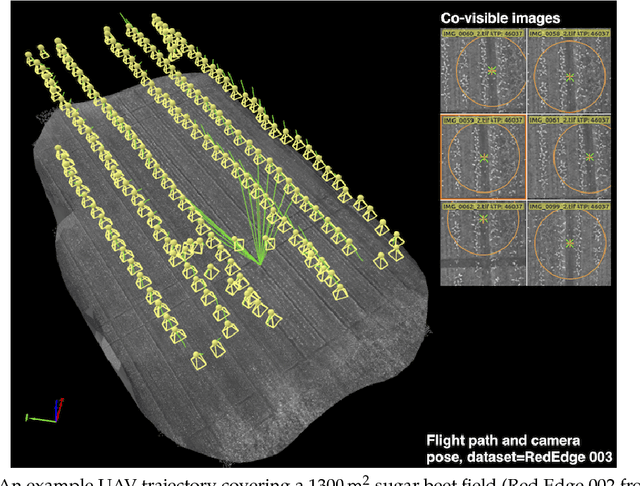
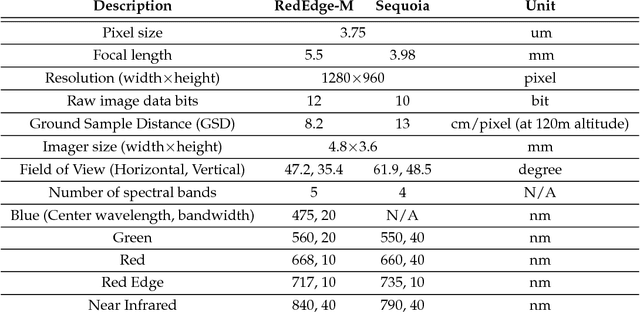
We present a novel weed segmentation and mapping framework that processes multispectral images obtained from an unmanned aerial vehicle (UAV) using a deep neural network (DNN). Most studies on crop/weed semantic segmentation only consider single images for processing and classification. Images taken by UAVs often cover only a few hundred square meters with either color only or color and near-infrared (NIR) channels. Computing a single large and accurate vegetation map (e.g., crop/weed) using a DNN is non-trivial due to difficulties arising from: (1) limited ground sample distances (GSDs) in high-altitude datasets, (2) sacrificed resolution resulting from downsampling high-fidelity images, and (3) multispectral image alignment. To address these issues, we adopt a stand sliding window approach that operates on only small portions of multispectral orthomosaic maps (tiles), which are channel-wise aligned and calibrated radiometrically across the entire map. We define the tile size to be the same as that of the DNN input to avoid resolution loss. Compared to our baseline model (i.e., SegNet with 3 channel RGB inputs) yielding an area under the curve (AUC) of [background=0.607, crop=0.681, weed=0.576], our proposed model with 9 input channels achieves [0.839, 0.863, 0.782]. Additionally, we provide an extensive analysis of 20 trained models, both qualitatively and quantitatively, in order to evaluate the effects of varying input channels and tunable network hyperparameters. Furthermore, we release a large sugar beet/weed aerial dataset with expertly guided annotations for further research in the fields of remote sensing, precision agriculture, and agricultural robotics.
weedNet: Dense Semantic Weed Classification Using Multispectral Images and MAV for Smart Farming
Sep 11, 2017

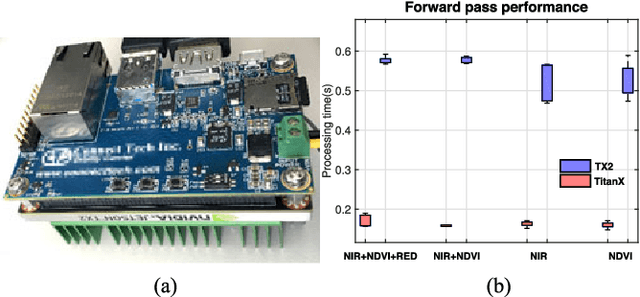

Selective weed treatment is a critical step in autonomous crop management as related to crop health and yield. However, a key challenge is reliable, and accurate weed detection to minimize damage to surrounding plants. In this paper, we present an approach for dense semantic weed classification with multispectral images collected by a micro aerial vehicle (MAV). We use the recently developed encoder-decoder cascaded Convolutional Neural Network (CNN), Segnet, that infers dense semantic classes while allowing any number of input image channels and class balancing with our sugar beet and weed datasets. To obtain training datasets, we established an experimental field with varying herbicide levels resulting in field plots containing only either crop or weed, enabling us to use the Normalized Difference Vegetation Index (NDVI) as a distinguishable feature for automatic ground truth generation. We train 6 models with different numbers of input channels and condition (fine-tune) it to achieve about 0.8 F1-score and 0.78 Area Under the Curve (AUC) classification metrics. For model deployment, an embedded GPU system (Jetson TX2) is tested for MAV integration. Dataset used in this paper is released to support the community and future work.
Generative OpenMax for Multi-Class Open Set Classification
Jul 24, 2017
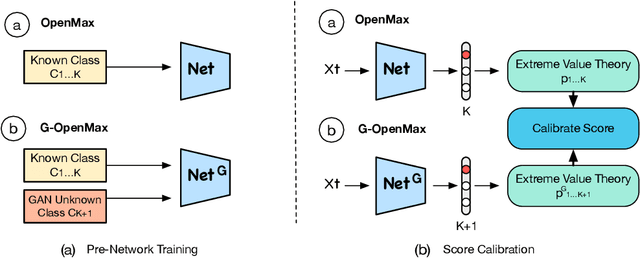


We present a conceptually new and flexible method for multi-class open set classification. Unlike previous methods where unknown classes are inferred with respect to the feature or decision distance to the known classes, our approach is able to provide explicit modelling and decision score for unknown classes. The proposed method, called Gener- ative OpenMax (G-OpenMax), extends OpenMax by employing generative adversarial networks (GANs) for novel category image synthesis. We validate the proposed method on two datasets of handwritten digits and characters, resulting in superior results over previous deep learning based method OpenMax Moreover, G-OpenMax provides a way to visualize samples representing the unknown classes from open space. Our simple and effective approach could serve as a new direction to tackle the challenging multi-class open set classification problem.
Deep Learning Features at Scale for Visual Place Recognition
Jan 18, 2017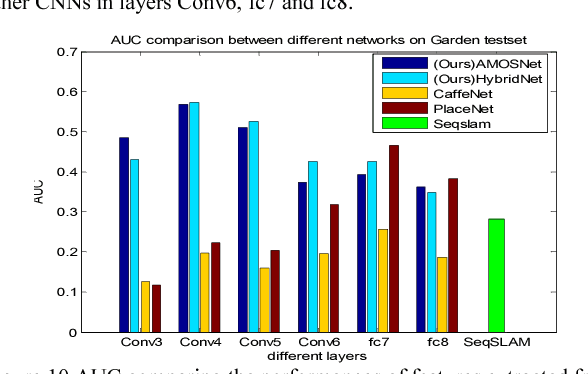


The success of deep learning techniques in the computer vision domain has triggered a range of initial investigations into their utility for visual place recognition, all using generic features from networks that were trained for other types of recognition tasks. In this paper, we train, at large scale, two CNN architectures for the specific place recognition task and employ a multi-scale feature encoding method to generate condition- and viewpoint-invariant features. To enable this training to occur, we have developed a massive Specific PlacEs Dataset (SPED) with hundreds of examples of place appearance change at thousands of different places, as opposed to the semantic place type datasets currently available. This new dataset enables us to set up a training regime that interprets place recognition as a classification problem. We comprehensively evaluate our trained networks on several challenging benchmark place recognition datasets and demonstrate that they achieve an average 10% increase in performance over other place recognition algorithms and pre-trained CNNs. By analyzing the network responses and their differences from pre-trained networks, we provide insights into what a network learns when training for place recognition, and what these results signify for future research in this area.
Convolutional Neural Network-based Place Recognition
Nov 06, 2014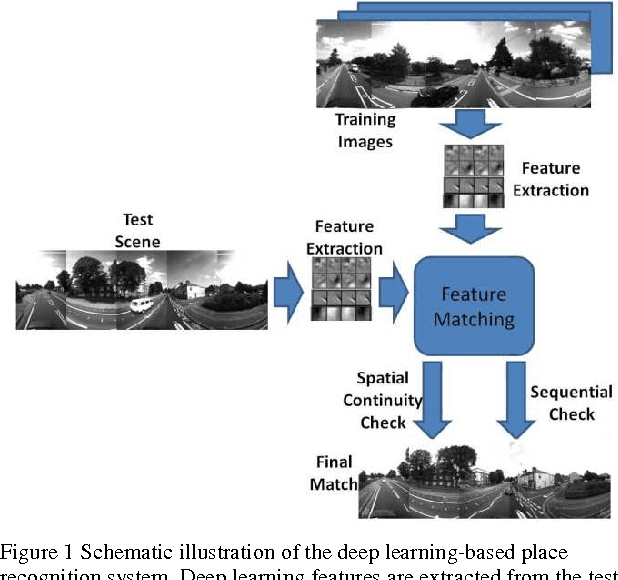
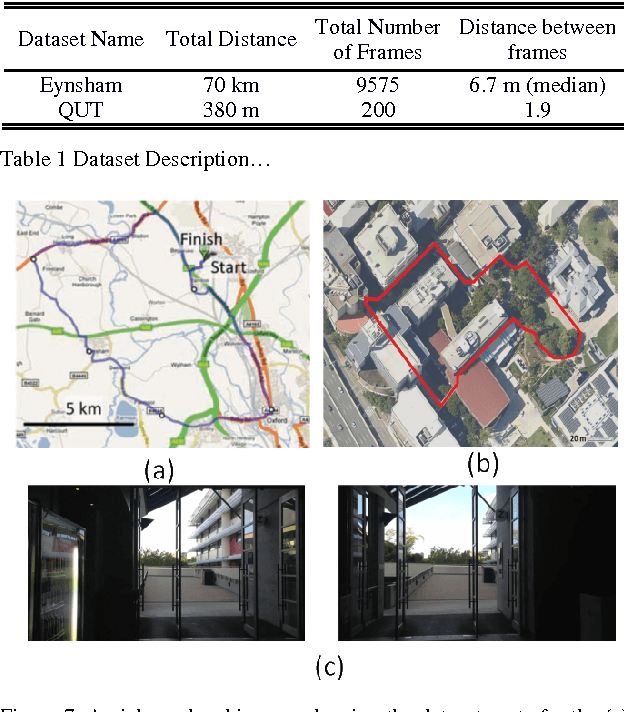
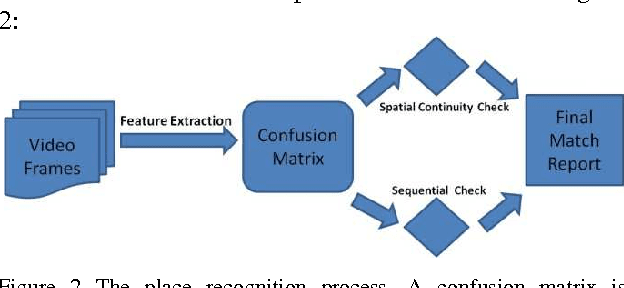
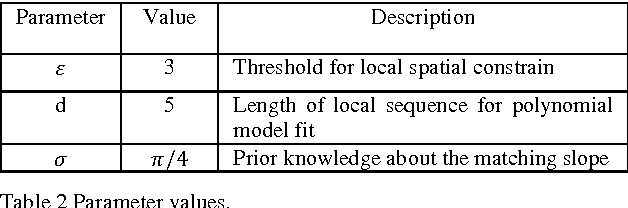
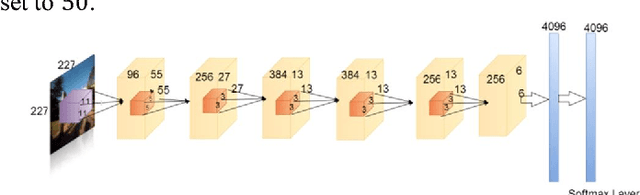
Recently Convolutional Neural Networks (CNNs) have been shown to achieve state-of-the-art performance on various classification tasks. In this paper, we present for the first time a place recognition technique based on CNN models, by combining the powerful features learnt by CNNs with a spatial and sequential filter. Applying the system to a 70 km benchmark place recognition dataset we achieve a 75% increase in recall at 100% precision, significantly outperforming all previous state of the art techniques. We also conduct a comprehensive performance comparison of the utility of features from all 21 layers for place recognition, both for the benchmark dataset and for a second dataset with more significant viewpoint changes.