 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Limits and Potentials of Deep Learning for Robotics
Apr 18, 2018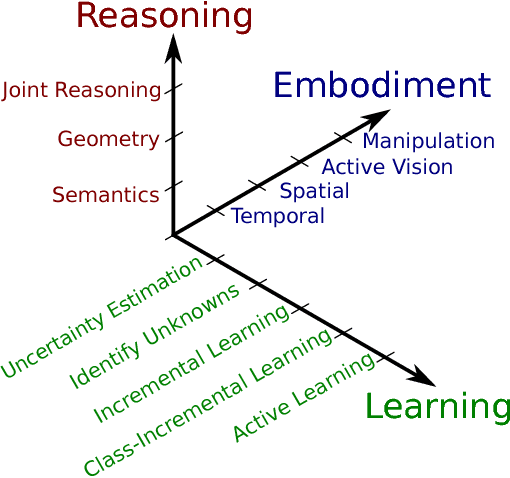


The application of deep learning in robotics leads to very specific problems and research questions that are typically not addressed by the computer vision and machine learning communities. In this paper we discuss a number of robotics-specific learning, reasoning, and embodiment challenges for deep learning. We explain the need for better evaluation metrics, highlight the importance and unique challenges for deep robotic learning in simulation, and explore the spectrum between purely data-driven and model-driven approaches. We hope this paper provides a motivating overview of important research directions to overcome the current limitations, and help fulfill the promising potentials of deep learning in robotics.
Simple Online and Realtime Tracking
Jul 07, 2017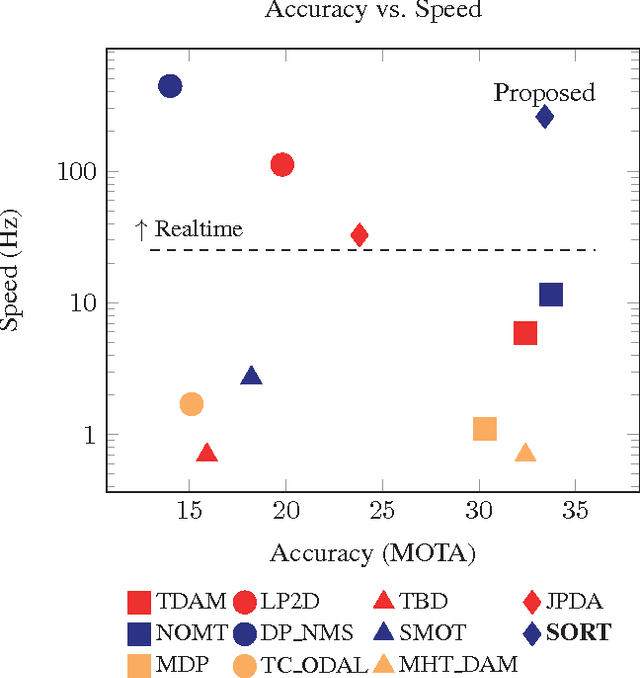
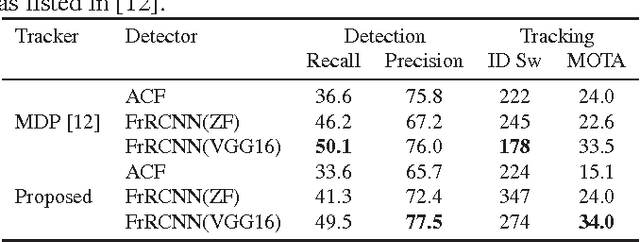
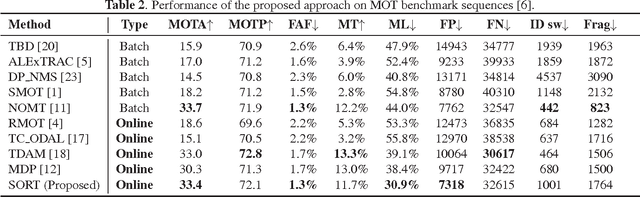
This paper explores a pragmatic approach to multiple object tracking where the main focus is to associate objects efficiently for online and realtime applications. To this end, detection quality is identified as a key factor influencing tracking performance, where changing the detector can improve tracking by up to 18.9%. Despite only using a rudimentary combination of familiar techniques such as the Kalman Filter and Hungarian algorithm for the tracking components, this approach achieves an accuracy comparable to state-of-the-art online trackers. Furthermore, due to the simplicity of our tracking method, the tracker updates at a rate of 260 Hz which is over 20x faster than other state-of-the-art trackers.
Multi-Modal Trip Hazard Affordance Detection On Construction Sites
Jun 21, 2017



Trip hazards are a significant contributor to accidents on construction and manufacturing sites, where over a third of Australian workplace injuries occur [1]. Current safety inspections are labour intensive and limited by human fallibility,making automation of trip hazard detection appealing from both a safety and economic perspective. Trip hazards present an interesting challenge to modern learning techniques because they are defined as much by affordance as by object type; for example wires on a table are not a trip hazard, but can be if lying on the ground. To address these challenges, we conduct a comprehensive investigation into the performance characteristics of 11 different colour and depth fusion approaches, including 4 fusion and one non fusion approach; using colour and two types of depth images. Trained and tested on over 600 labelled trip hazards over 4 floors and 2000m$\mathrm{^{2}}$ in an active construction site,this approach was able to differentiate between identical objects in different physical configurations (see Figure 1). Outperforming a colour-only detector, our multi-modal trip detector fuses colour and depth information to achieve a 4% absolute improvement in F1-score. These investigative results and the extensive publicly available dataset moves us one step closer to assistive or fully automated safety inspection systems on construction sites.
Peduncle Detection of Sweet Pepper for Autonomous Crop Harvesting - Combined Colour and 3D Information
Jan 30, 2017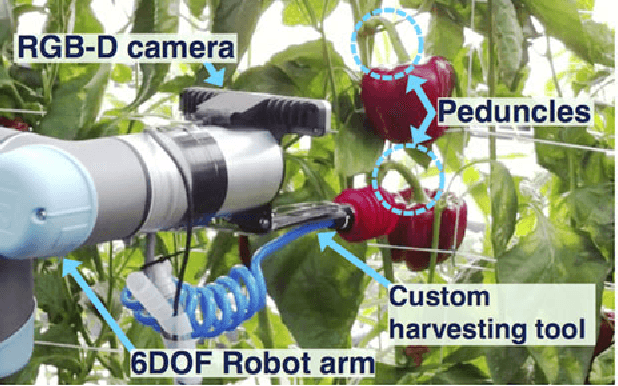
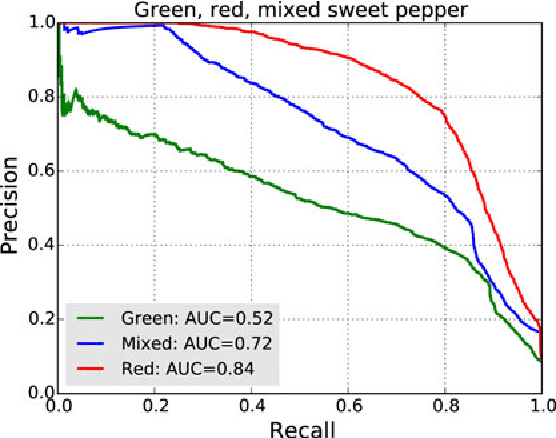
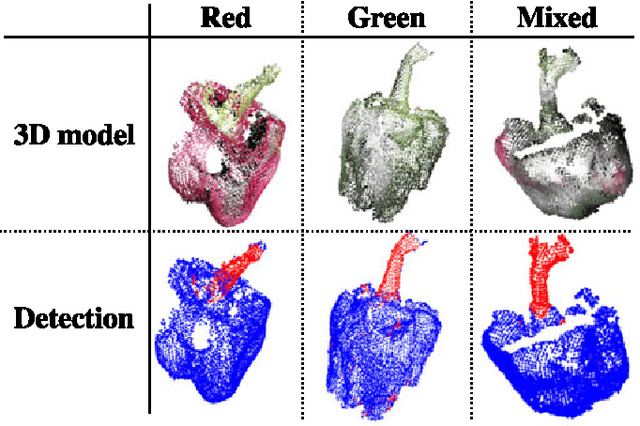
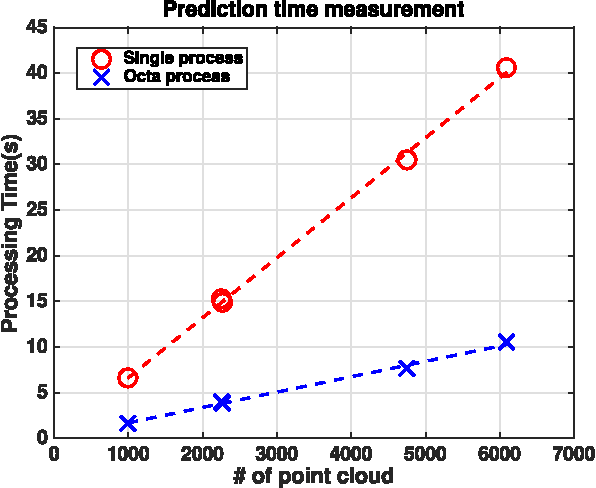
This paper presents a 3D visual detection method for the challenging task of detecting peduncles of sweet peppers (Capsicum annuum) in the field. Cutting the peduncle cleanly is one of the most difficult stages of the harvesting process, where the peduncle is the part of the crop that attaches it to the main stem of the plant. Accurate peduncle detection in 3D space is therefore a vital step in reliable autonomous harvesting of sweet peppers, as this can lead to precise cutting while avoiding damage to the surrounding plant. This paper makes use of both colour and geometry information acquired from an RGB-D sensor and utilises a supervised-learning approach for the peduncle detection task. The performance of the proposed method is demonstrated and evaluated using qualitative and quantitative results (the Area-Under-the-Curve (AUC) of the detection precision-recall curve). We are able to achieve an AUC of 0.71 for peduncle detection on field-grown sweet peppers. We release a set of manually annotated 3D sweet pepper and peduncle images to assist the research community in performing further research on this topic.
Deep Learning Features at Scale for Visual Place Recognition
Jan 18, 2017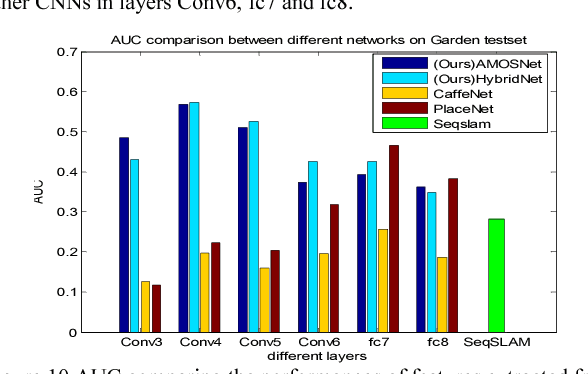
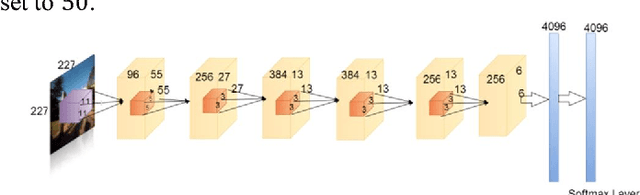


The success of deep learning techniques in the computer vision domain has triggered a range of initial investigations into their utility for visual place recognition, all using generic features from networks that were trained for other types of recognition tasks. In this paper, we train, at large scale, two CNN architectures for the specific place recognition task and employ a multi-scale feature encoding method to generate condition- and viewpoint-invariant features. To enable this training to occur, we have developed a massive Specific PlacEs Dataset (SPED) with hundreds of examples of place appearance change at thousands of different places, as opposed to the semantic place type datasets currently available. This new dataset enables us to set up a training regime that interprets place recognition as a classification problem. We comprehensively evaluate our trained networks on several challenging benchmark place recognition datasets and demonstrate that they achieve an average 10% increase in performance over other place recognition algorithms and pre-trained CNNs. By analyzing the network responses and their differences from pre-trained networks, we provide insights into what a network learns when training for place recognition, and what these results signify for future research in this area.
Action Recognition: From Static Datasets to Moving Robots
Jan 18, 2017
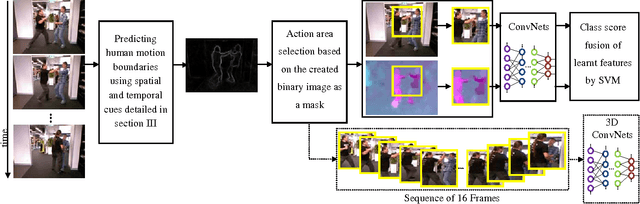
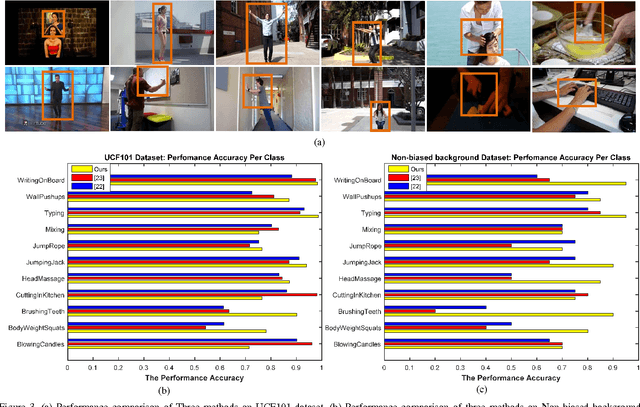

Deep learning models have achieved state-of-the- art performance in recognizing human activities, but often rely on utilizing background cues present in typical computer vision datasets that predominantly have a stationary camera. If these models are to be employed by autonomous robots in real world environments, they must be adapted to perform independently of background cues and camera motion effects. To address these challenges, we propose a new method that firstly generates generic action region proposals with good potential to locate one human action in unconstrained videos regardless of camera motion and then uses action proposals to extract and classify effective shape and motion features by a ConvNet framework. In a range of experiments, we demonstrate that by actively proposing action regions during both training and testing, state-of-the-art or better performance is achieved on benchmarks. We show the outperformance of our approach compared to the state-of-the-art in two new datasets; one emphasizes on irrelevant background, the other highlights the camera motion. We also validate our action recognition method in an abnormal behavior detection scenario to improve workplace safety. The results verify a higher success rate for our method due to the ability of our system to recognize human actions regardless of environment and camera motion.
The ACRV Picking Benchmark : A Robotic Shelf Picking Benchmark to Foster Reproducible Research
Dec 14, 2016



Robotic challenges like the Amazon Picking Challenge (APC) or the DARPA Challenges are an established and important way to drive scientific progress. They make research comparable on a well-defined benchmark with equal test conditions for all participants. However, such challenge events occur only occasionally, are limited to a small number of contestants, and the test conditions are very difficult to replicate after the main event. We present a new physical benchmark challenge for robotic picking: the ACRV Picking Benchmark (APB). Designed to be reproducible, it consists of a set of 42 common objects, a widely available shelf, and exact guidelines for object arrangement using stencils. A well-defined evaluation protocol enables the comparison of \emph{complete} robotic systems -- including perception and manipulation -- instead of sub-systems only. Our paper also describes and reports results achieved by an open baseline system based on a Baxter robot.
Evaluation of Object Detection Proposals Under Condition Variations
Dec 10, 2015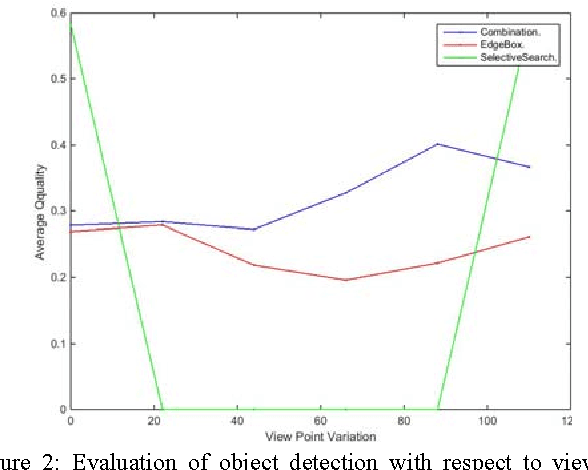
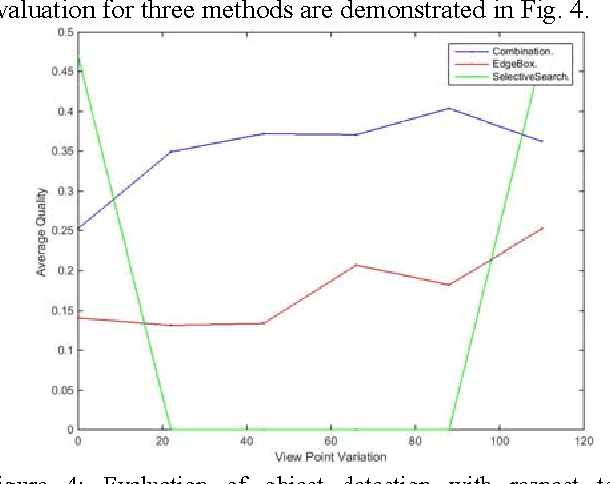
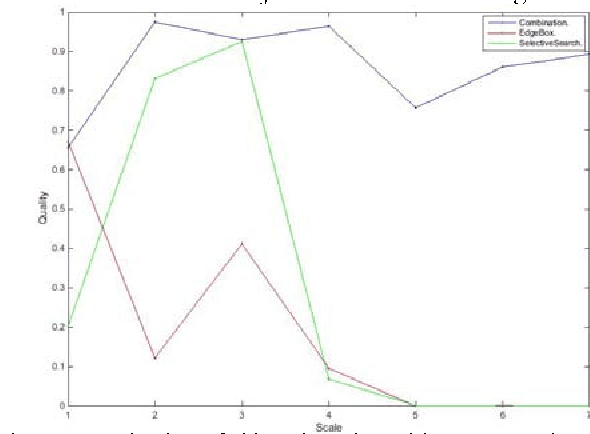
Object detection is a fundamental task in many computer vision applications, therefore the importance of evaluating the quality of object detection is well acknowledged in this domain. This process gives insight into the capabilities of methods in handling environmental changes. In this paper, a new method for object detection is introduced that combines the Selective Search and EdgeBoxes. We tested these three methods under environmental variations. Our experiments demonstrate the outperformance of the combination method under illumination and view point variations.
Fine-Grained Classification via Mixture of Deep Convolutional Neural Networks
Nov 30, 2015
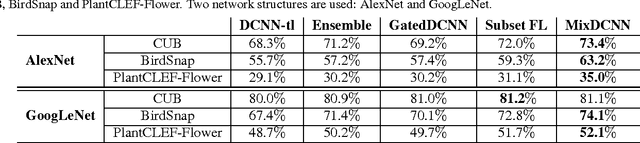
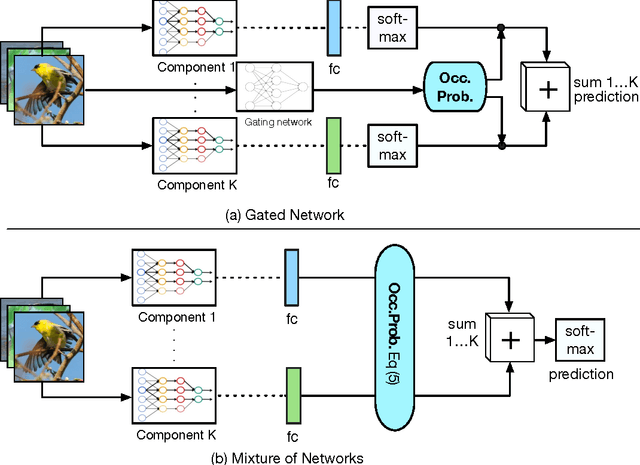

We present a novel deep convolutional neural network (DCNN) system for fine-grained image classification, called a mixture of DCNNs (MixDCNN). The fine-grained image classification problem is characterised by large intra-class variations and small inter-class variations. To overcome these problems our proposed MixDCNN system partitions images into K subsets of similar images and learns an expert DCNN for each subset. The output from each of the K DCNNs is combined to form a single classification decision. In contrast to previous techniques, we provide a formulation to perform joint end-to-end training of the K DCNNs simultaneously. Extensive experiments, on three datasets using two network structures (AlexNet and GoogLeNet), show that the proposed MixDCNN system consistently outperforms other methods. It provides a relative improvement of 12.7% and achieves state-of-the-art results on two datasets.
Towards Vision-Based Deep Reinforcement Learning for Robotic Motion Control
Nov 13, 2015


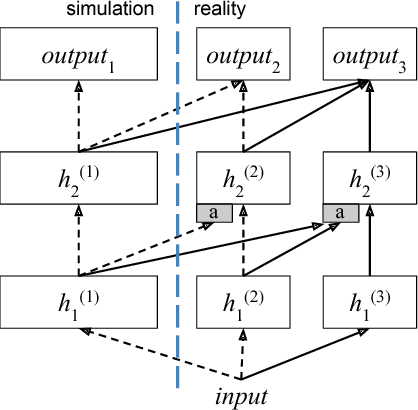
This paper introduces a machine learning based system for controlling a robotic manipulator with visual perception only. The capability to autonomously learn robot controllers solely from raw-pixel images and without any prior knowledge of configuration is shown for the first time. We build upon the success of recent deep reinforcement learning and develop a system for learning target reaching with a three-joint robot manipulator using external visual observation. A Deep Q Network (DQN) was demonstrated to perform target reaching after training in simulation. Transferring the network to real hardware and real observation in a naive approach failed, but experiments show that the network works when replacing camera images with synthetic images.