 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Trip Hazard Affordance Detection On Construction Sites
Jun 21, 2017



Trip hazards are a significant contributor to accidents on construction and manufacturing sites, where over a third of Australian workplace injuries occur [1]. Current safety inspections are labour intensive and limited by human fallibility,making automation of trip hazard detection appealing from both a safety and economic perspective. Trip hazards present an interesting challenge to modern learning techniques because they are defined as much by affordance as by object type; for example wires on a table are not a trip hazard, but can be if lying on the ground. To address these challenges, we conduct a comprehensive investigation into the performance characteristics of 11 different colour and depth fusion approaches, including 4 fusion and one non fusion approach; using colour and two types of depth images. Trained and tested on over 600 labelled trip hazards over 4 floors and 2000m$\mathrm{^{2}}$ in an active construction site,this approach was able to differentiate between identical objects in different physical configurations (see Figure 1). Outperforming a colour-only detector, our multi-modal trip detector fuses colour and depth information to achieve a 4% absolute improvement in F1-score. These investigative results and the extensive publicly available dataset moves us one step closer to assistive or fully automated safety inspection systems on construction sites.
Place Categorization and Semantic Mapping on a Mobile Robot
Jul 09, 2015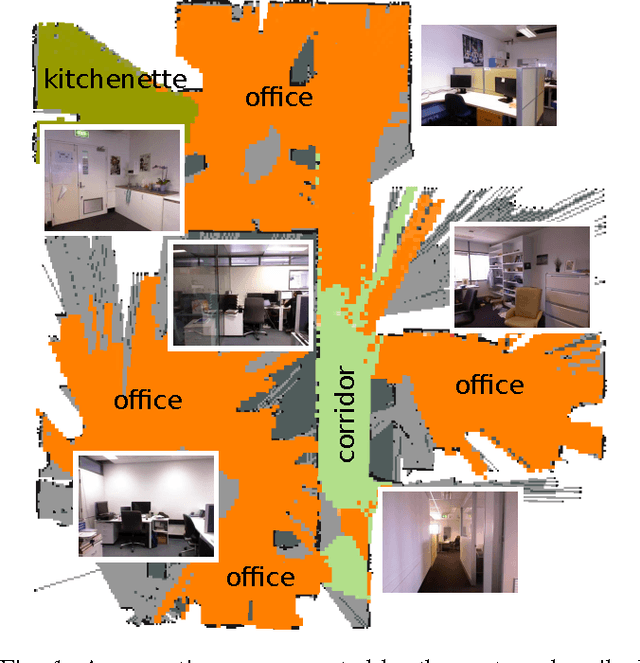
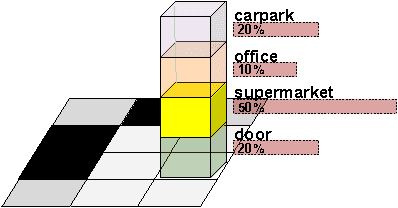

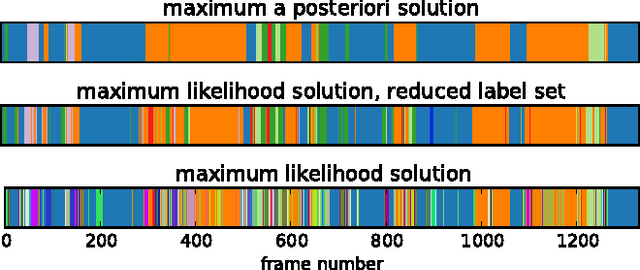
In this paper we focus on the challenging problem of place categorization and semantic mapping on a robot without environment-specific training. Motivated by their ongoing success in various visual recognition tasks, we build our system upon a state-of-the-art convolutional network. We overcome its closed-set limitations by complementing the network with a series of one-vs-all classifiers that can learn to recognize new semantic classes online. Prior domain knowledge is incorporated by embedding the classification system into a Bayesian filter framework that also ensures temporal coherence. We evaluate the classification accuracy of the system on a robot that maps a variety of places on our campus in real-time. We show how semantic information can boost robotic object detection performance and how the semantic map can be used to modulate the robot's behaviour during navigation tasks. The system is made available to the community as a ROS module.