 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobot Navigation in Unseen Spaces using an Abstract Map
Jan 31, 2020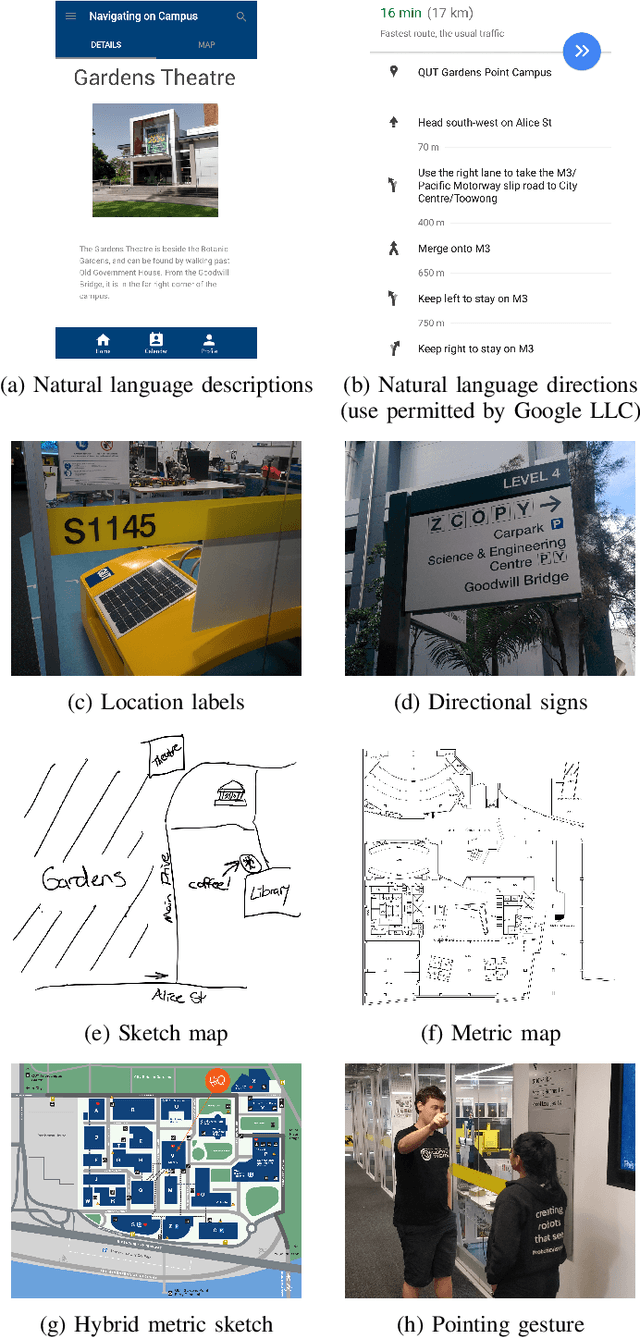

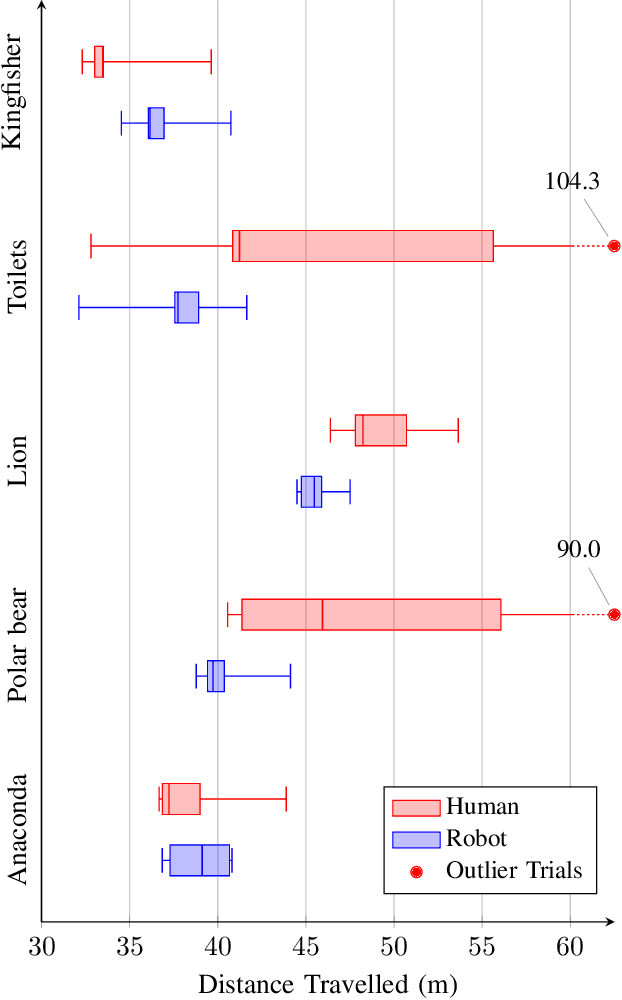
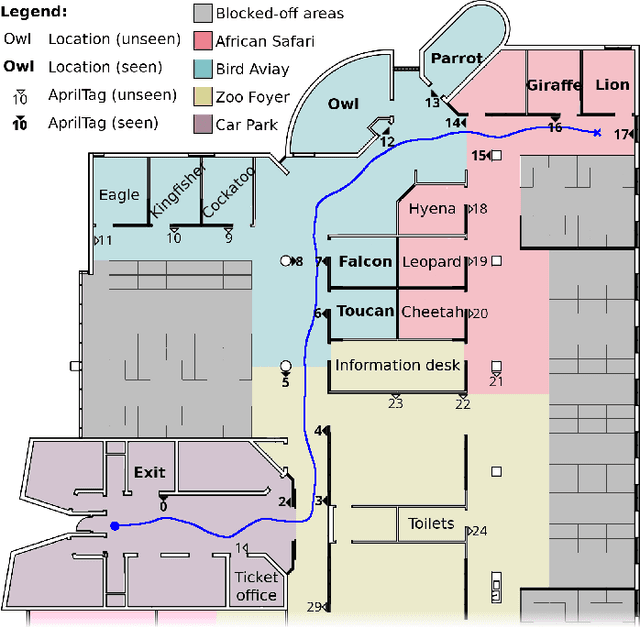
Human navigation in built environments depends on symbolic spatial information which has unrealised potential to enhance robot navigation capabilities. Information sources such as labels, signs, maps, planners, spoken directions, and navigational gestures communicate a wealth of spatial information to the navigators of built environments; a wealth of information that robots typically ignore. We present a robot navigation system that uses the same symbolic spatial information employed by humans to purposefully navigate in unseen built environments with a level of performance comparable to humans. The navigation system uses a novel data structure called the abstract map to imagine malleable spatial models for unseen spaces from spatial symbols. Sensorimotor perceptions from a robot are then employed to provide purposeful navigation to symbolic goal locations in the unseen environment. We show how a dynamic system can be used to create malleable spatial models for the abstract map, and provide an open source implementation to encourage future work in the area of symbolic navigation. Symbolic navigation performance of humans and a robot is evaluated in a real-world built environment. The paper concludes with a qualitative analysis of human navigation strategies, providing further insights into how the symbolic navigation capabilities of robots in unseen built environments can be improved in the future.
ARTiS: Appearance-based Action Recognition in Task Space for Real-Time Human-Robot Collaboration
Mar 07, 2017
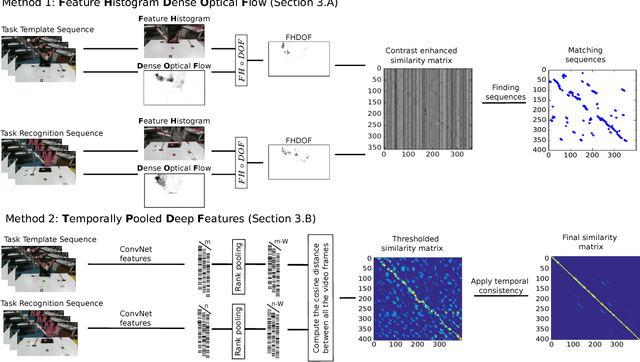
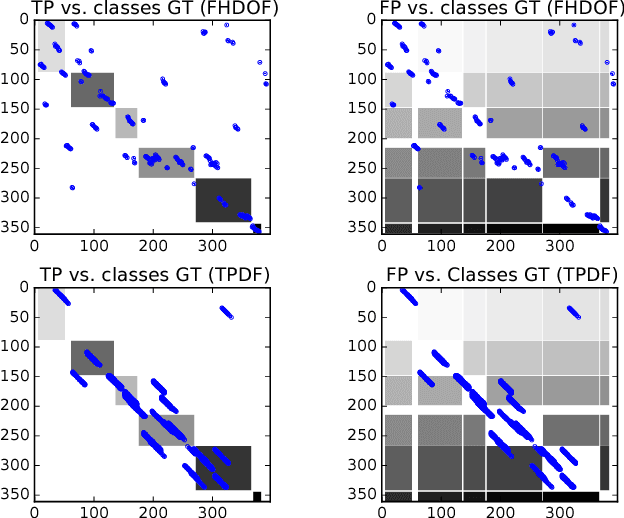
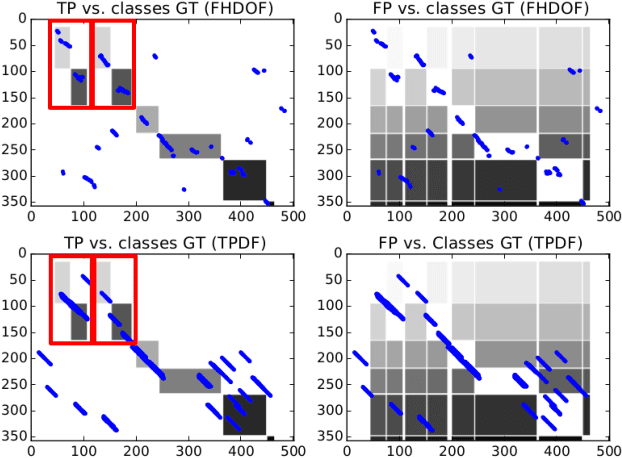
To have a robot actively supporting a human during a collaborative task, it is crucial that robots are able to identify the current action in order to predict the next one. Common approaches make use of high-level knowledge, such as object affordances, semantics or understanding of actions in terms of pre- and post-conditions. These approaches often require hand-coded a priori knowledge, time- and resource-intensive or supervised learning techniques. We propose to reframe this problem as an appearance-based place recognition problem. In our framework, we regard sequences of visual images of human actions as a map in analogy to the visual place recognition problem. Observing the task for the second time, our approach is able to recognize pre-observed actions in a one-shot learning approach and is thereby able to recognize the current observation in the task space. We propose two new methods for creating and aligning action observations within a task map. We compare and verify our approaches with real data of humans assembling several types of IKEA flat packs.
Place Categorization and Semantic Mapping on a Mobile Robot
Jul 09, 2015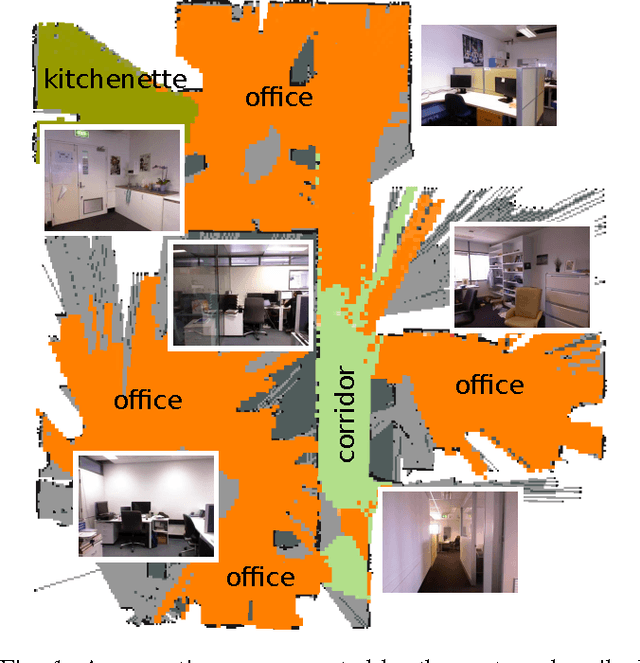

In this paper we focus on the challenging problem of place categorization and semantic mapping on a robot without environment-specific training. Motivated by their ongoing success in various visual recognition tasks, we build our system upon a state-of-the-art convolutional network. We overcome its closed-set limitations by complementing the network with a series of one-vs-all classifiers that can learn to recognize new semantic classes online. Prior domain knowledge is incorporated by embedding the classification system into a Bayesian filter framework that also ensures temporal coherence. We evaluate the classification accuracy of the system on a robot that maps a variety of places on our campus in real-time. We show how semantic information can boost robotic object detection performance and how the semantic map can be used to modulate the robot's behaviour during navigation tasks. The system is made available to the community as a ROS module.