 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Free-Form Deformations for 3D Object Reconstruction
Mar 29, 2018



Representing 3D shape in deep learning frameworks in an accurate, efficient and compact manner still remains an open challenge. Most existing work addresses this issue by employing voxel-based representations. While these approaches benefit greatly from advances in computer vision by generalizing 2D convolutions to the 3D setting, they also have several considerable drawbacks. The computational complexity of voxel-encodings grows cubically with the resolution thus limiting such representations to low-resolution 3D reconstruction. In an attempt to solve this problem, point cloud representations have been proposed. Although point clouds are more efficient than voxel representations as they only cover surfaces rather than volumes, they do not encode detailed geometric information about relationships between points. In this paper we propose a method to learn free-form deformations (FFD) for the task of 3D reconstruction from a single image. By learning to deform points sampled from a high-quality mesh, our trained model can be used to produce arbitrarily dense point clouds or meshes with fine-grained geometry. We evaluate our proposed framework on both synthetic and real-world data and achieve state-of-the-art results on point-cloud and volumetric metrics. Additionally, we qualitatively demonstrate its applicability to label transferring for 3D semantic segmentation.
On Encoding Temporal Evolution for Real-time Action Prediction
Feb 08, 2018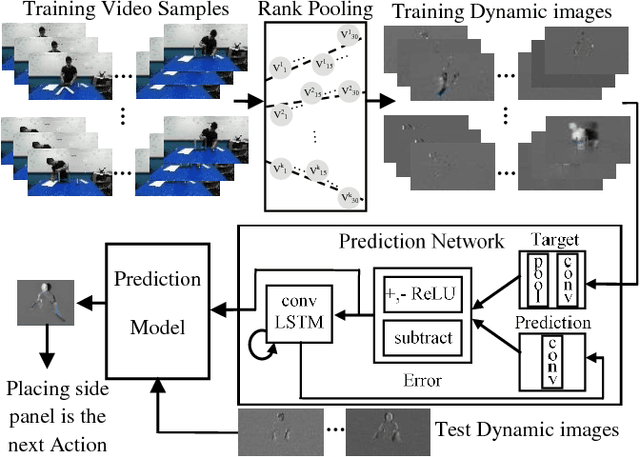
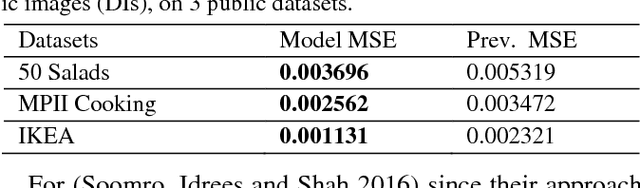

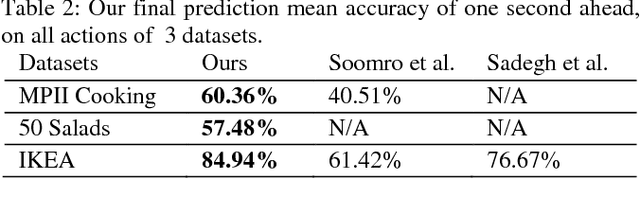
Anticipating future actions is a key component of intelligence, specifically when it applies to real-time systems, such as robots or autonomous cars. While recent works have addressed prediction of raw RGB pixel values, we focus on anticipating the motion evolution in future video frames. To this end, we construct dynamic images (DIs) by summarising moving pixels through a sequence of future frames. We train a convolutional LSTMs to predict the next DIs based on an unsupervised learning process, and then recognise the activity associated with the predicted DI. We demonstrate the effectiveness of our approach on 3 benchmark action datasets showing that despite running on videos with complex activities, our approach is able to anticipate the next human action with high accuracy and obtain better results than the state-of-the-art methods.
Unsupervised Human Action Detection by Action Matching
May 16, 2017
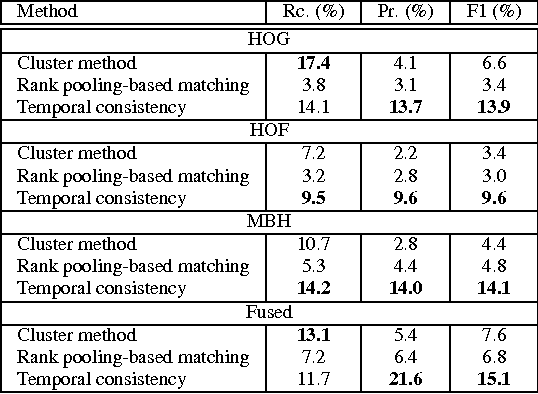
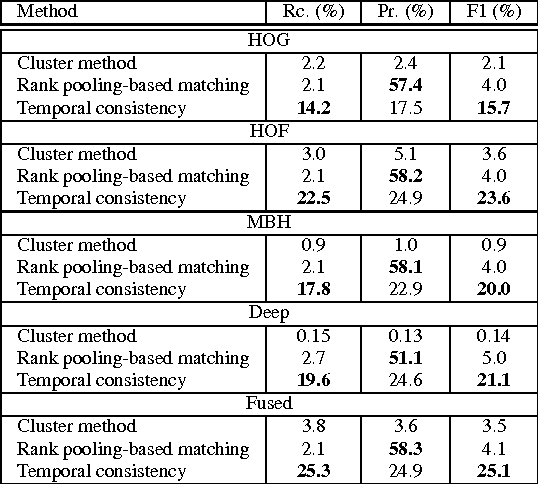
We propose a new task of unsupervised action detection by action matching. Given two long videos, the objective is to temporally detect all pairs of matching video segments. A pair of video segments are matched if they share the same human action. The task is category independent---it does not matter what action is being performed---and no supervision is used to discover such video segments. Unsupervised action detection by action matching allows us to align videos in a meaningful manner. As such, it can be used to discover new action categories or as an action proposal technique within, say, an action detection pipeline. Moreover, it is a useful pre-processing step for generating video highlights, e.g., from sports videos. We present an effective and efficient method for unsupervised action detection. We use an unsupervised temporal encoding method and exploit the temporal consistency in human actions to obtain candidate action segments. We evaluate our method on this challenging task using three activity recognition benchmarks, namely, the MPII Cooking activities dataset, the THUMOS15 action detection benchmark and a new dataset called the IKEA dataset. On the MPII Cooking dataset we detect action segments with a precision of 21.6% and recall of 11.7% over 946 long video pairs and over 5000 ground truth action segments. Similarly, on THUMOS dataset we obtain 18.4% precision and 25.1% recall over 5094 ground truth action segment pairs.
What Would You Do? Acting by Learning to Predict
Mar 08, 2017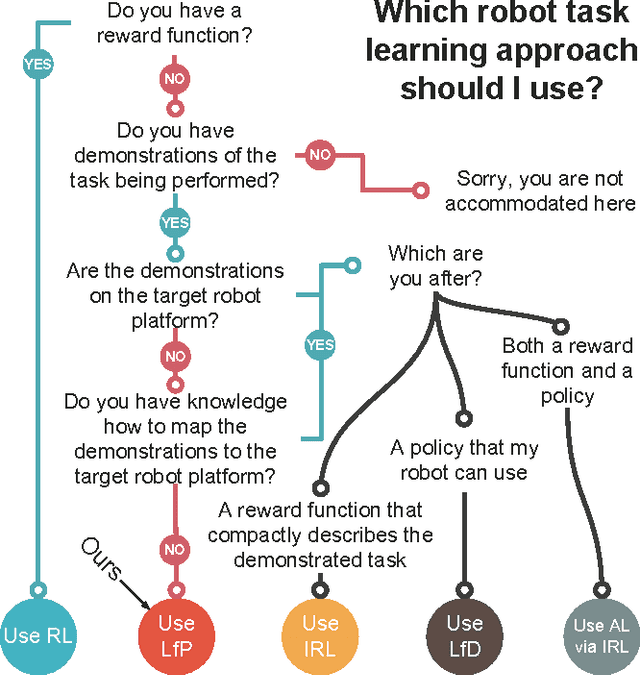

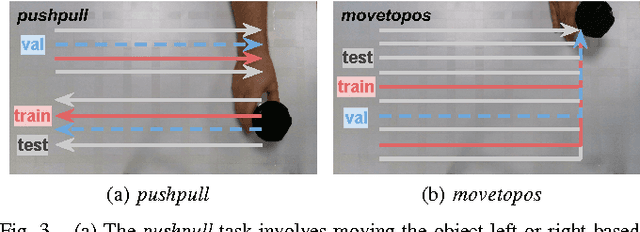
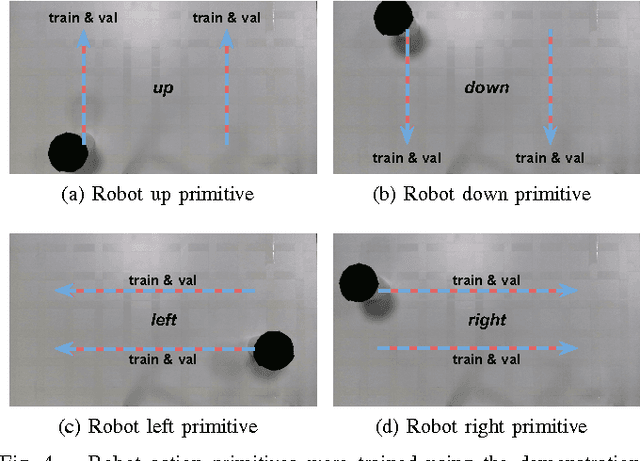
We propose to learn tasks directly from visual demonstrations by learning to predict the outcome of human and robot actions on an environment. We enable a robot to physically perform a human demonstrated task without knowledge of the thought processes or actions of the human, only their visually observable state transitions. We evaluate our approach on two table-top, object manipulation tasks and demonstrate generalisation to previously unseen states. Our approach reduces the priors required to implement a robot task learning system compared with the existing approaches of Learning from Demonstration, Reinforcement Learning and Inverse Reinforcement Learning.
ARTiS: Appearance-based Action Recognition in Task Space for Real-Time Human-Robot Collaboration
Mar 07, 2017
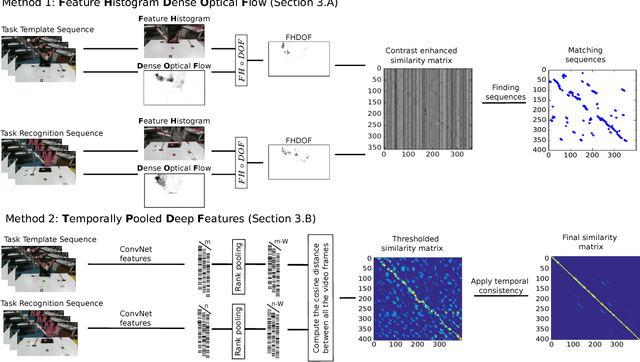
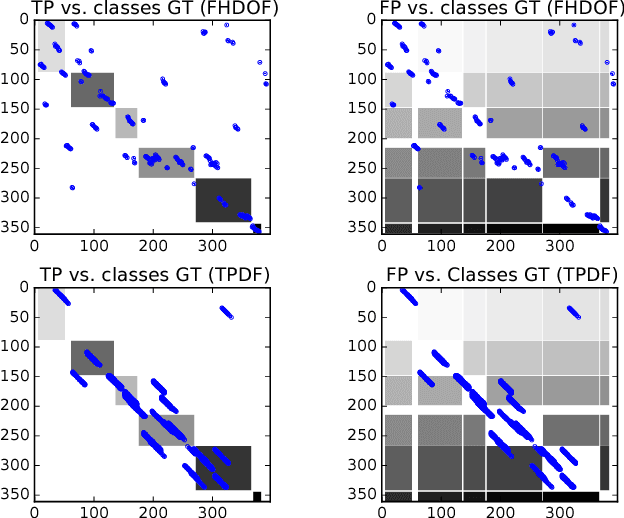
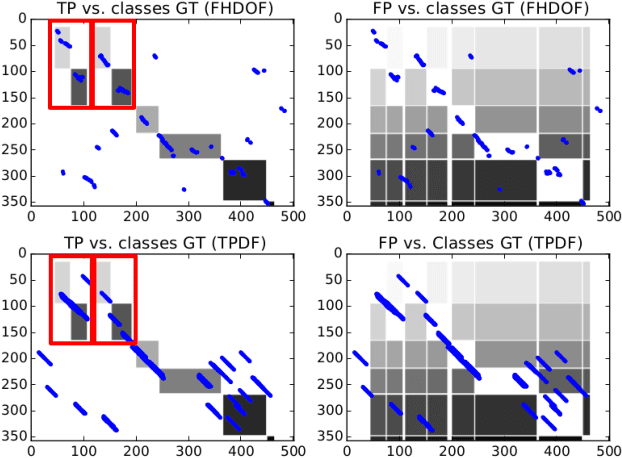
To have a robot actively supporting a human during a collaborative task, it is crucial that robots are able to identify the current action in order to predict the next one. Common approaches make use of high-level knowledge, such as object affordances, semantics or understanding of actions in terms of pre- and post-conditions. These approaches often require hand-coded a priori knowledge, time- and resource-intensive or supervised learning techniques. We propose to reframe this problem as an appearance-based place recognition problem. In our framework, we regard sequences of visual images of human actions as a map in analogy to the visual place recognition problem. Observing the task for the second time, our approach is able to recognize pre-observed actions in a one-shot learning approach and is thereby able to recognize the current observation in the task space. We propose two new methods for creating and aligning action observations within a task map. We compare and verify our approaches with real data of humans assembling several types of IKEA flat packs.
Action Recognition: From Static Datasets to Moving Robots
Jan 18, 2017
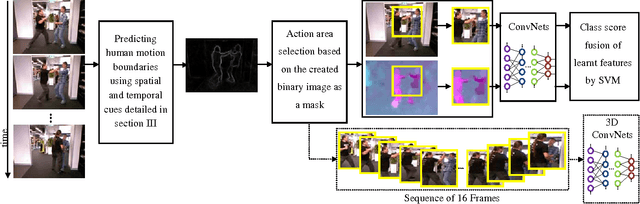
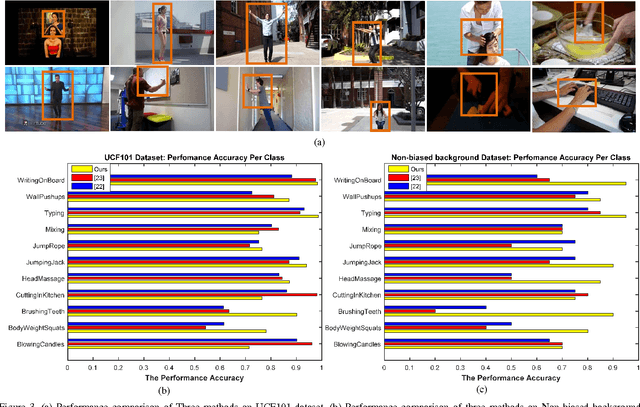

Deep learning models have achieved state-of-the- art performance in recognizing human activities, but often rely on utilizing background cues present in typical computer vision datasets that predominantly have a stationary camera. If these models are to be employed by autonomous robots in real world environments, they must be adapted to perform independently of background cues and camera motion effects. To address these challenges, we propose a new method that firstly generates generic action region proposals with good potential to locate one human action in unconstrained videos regardless of camera motion and then uses action proposals to extract and classify effective shape and motion features by a ConvNet framework. In a range of experiments, we demonstrate that by actively proposing action regions during both training and testing, state-of-the-art or better performance is achieved on benchmarks. We show the outperformance of our approach compared to the state-of-the-art in two new datasets; one emphasizes on irrelevant background, the other highlights the camera motion. We also validate our action recognition method in an abnormal behavior detection scenario to improve workplace safety. The results verify a higher success rate for our method due to the ability of our system to recognize human actions regardless of environment and camera motion.
Bags of Affine Subspaces for Robust Object Tracking
Feb 05, 2016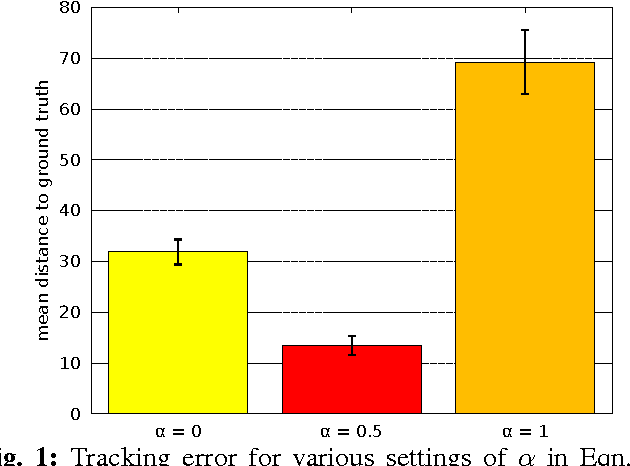

We propose an adaptive tracking algorithm where the object is modelled as a continuously updated bag of affine subspaces, with each subspace constructed from the object's appearance over several consecutive frames. In contrast to linear subspaces, affine subspaces explicitly model the origin of subspaces. Furthermore, instead of using a brittle point-to-subspace distance during the search for the object in a new frame, we propose to use a subspace-to-subspace distance by representing candidate image areas also as affine subspaces. Distances between subspaces are then obtained by exploiting the non-Euclidean geometry of Grassmann manifolds. Experiments on challenging videos (containing object occlusions, deformations, as well as variations in pose and illumination) indicate that the proposed method achieves higher tracking accuracy than several recent discriminative trackers.
Evaluation of Object Detection Proposals Under Condition Variations
Dec 10, 2015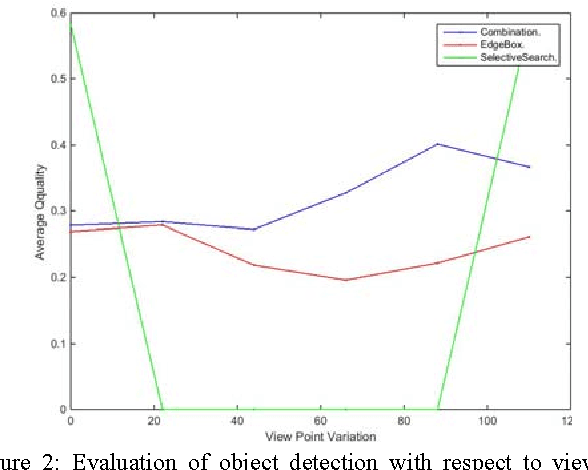
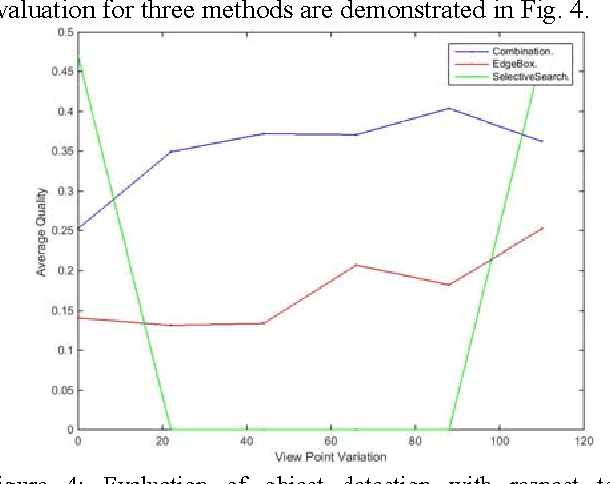
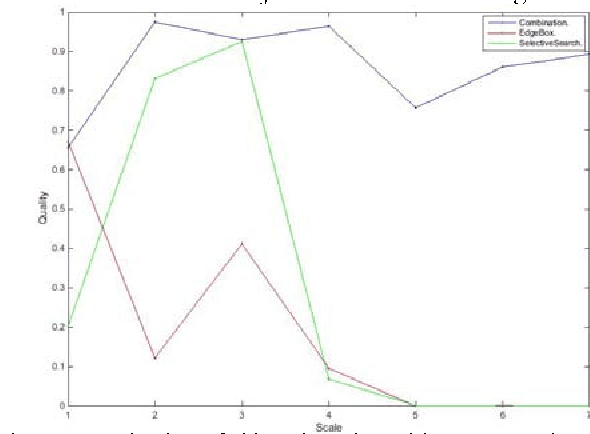
Object detection is a fundamental task in many computer vision applications, therefore the importance of evaluating the quality of object detection is well acknowledged in this domain. This process gives insight into the capabilities of methods in handling environmental changes. In this paper, a new method for object detection is introduced that combines the Selective Search and EdgeBoxes. We tested these three methods under environmental variations. Our experiments demonstrate the outperformance of the combination method under illumination and view point variations.
On the Performance of ConvNet Features for Place Recognition
Jul 29, 2015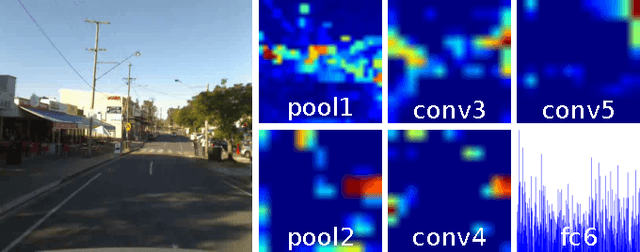
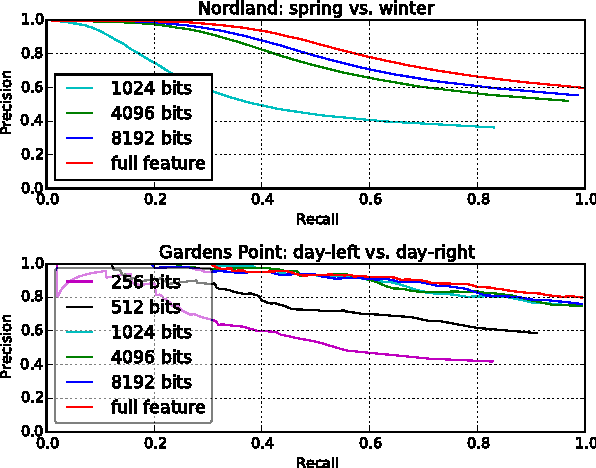

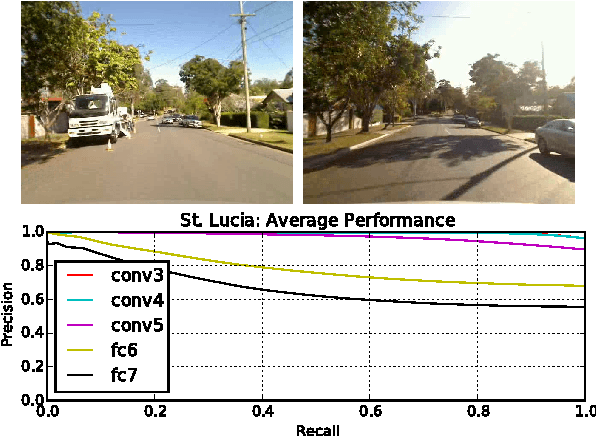
After the incredible success of deep learning in the computer vision domain, there has been much interest in applying Convolutional Network (ConvNet) features in robotic fields such as visual navigation and SLAM. Unfortunately, there are fundamental differences and challenges involved. Computer vision datasets are very different in character to robotic camera data, real-time performance is essential, and performance priorities can be different. This paper comprehensively evaluates and compares the utility of three state-of-the-art ConvNets on the problems of particular relevance to navigation for robots; viewpoint-invariance and condition-invariance, and for the first time enables real-time place recognition performance using ConvNets with large maps by integrating a variety of existing (locality-sensitive hashing) and novel (semantic search space partitioning) optimization techniques. We present extensive experiments on four real world datasets cultivated to evaluate each of the specific challenges in place recognition. The results demonstrate that speed-ups of two orders of magnitude can be achieved with minimal accuracy degradation, enabling real-time performance. We confirm that networks trained for semantic place categorization also perform better at (specific) place recognition when faced with severe appearance changes and provide a reference for which networks and layers are optimal for different aspects of the place recognition problem.
Object Tracking via Non-Euclidean Geometry: A Grassmann Approach
Mar 03, 2014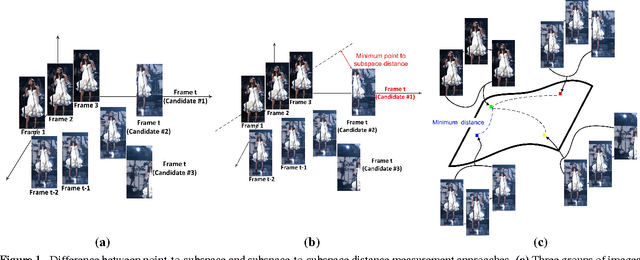
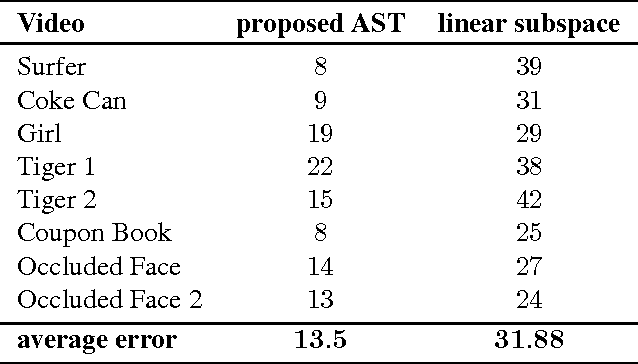
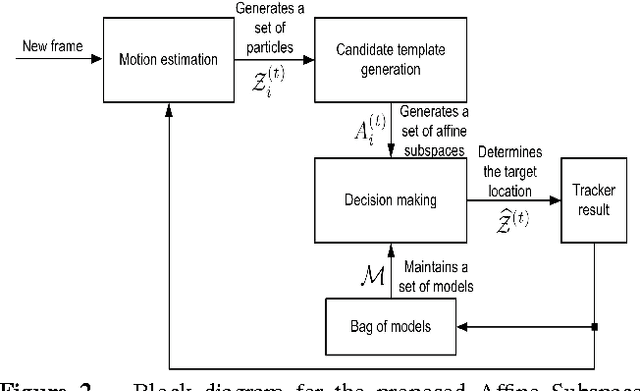

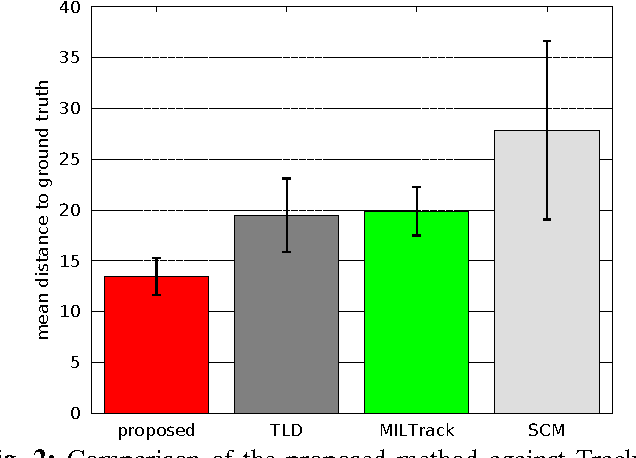
A robust visual tracking system requires an object appearance model that is able to handle occlusion, pose, and illumination variations in the video stream. This can be difficult to accomplish when the model is trained using only a single image. In this paper, we first propose a tracking approach based on affine subspaces (constructed from several images) which are able to accommodate the abovementioned variations. We use affine subspaces not only to represent the object, but also the candidate areas that the object may occupy. We furthermore propose a novel approach to measure affine subspace-to-subspace distance via the use of non-Euclidean geometry of Grassmann manifolds. The tracking problem is then considered as an inference task in a Markov Chain Monte Carlo framework via particle filtering. Quantitative evaluation on challenging video sequences indicates that the proposed approach obtains considerably better performance than several recent state-of-the-art methods such as Tracking-Learning-Detection and MILtrack.