 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Approaches to Grasp Synthesis: A Review
Jul 06, 2022


Grasping is the process of picking an object by applying forces and torques at a set of contacts. Recent advances in deep-learning methods have allowed rapid progress in robotic object grasping. We systematically surveyed the publications over the last decade, with a particular interest in grasping an object using all 6 degrees of freedom of the end-effector pose. Our review found four common methodologies for robotic grasping: sampling-based approaches, direct regression, reinforcement learning, and exemplar approaches. Furthermore, we found two 'supporting methods' around grasping that use deep-learning to support the grasping process, shape approximation, and affordances. We have distilled the publications found in this systematic review (85 papers) into ten key takeaways we consider crucial for future robotic grasping and manipulation research. An online version of the survey is available at https://rhys-newbury.github.io/projects/6dof/
Follow the Gradient: Crossing the Reality Gap using Differentiable Physics
Sep 10, 2021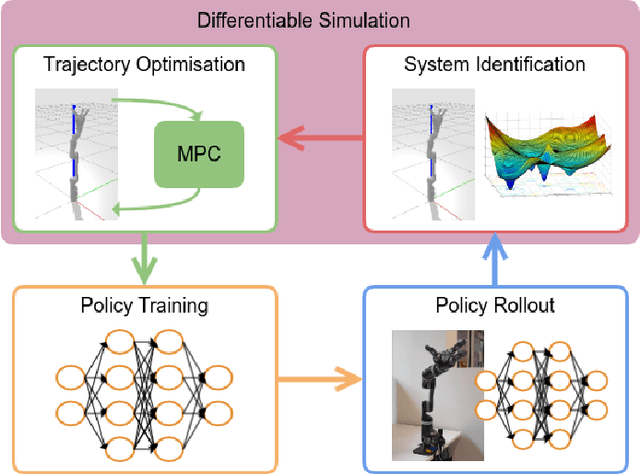

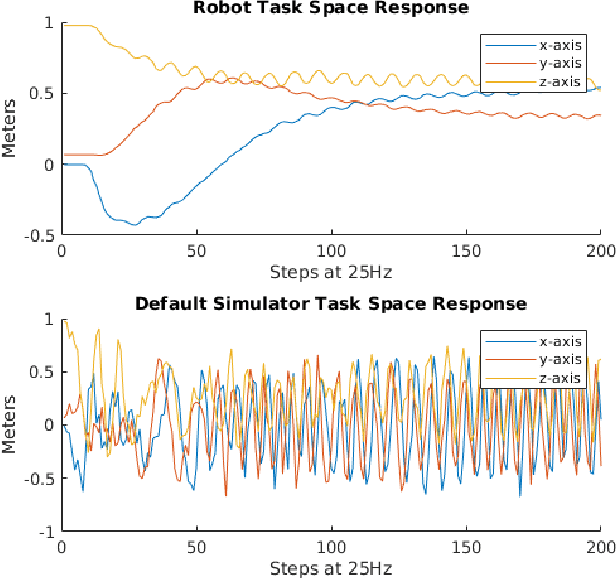
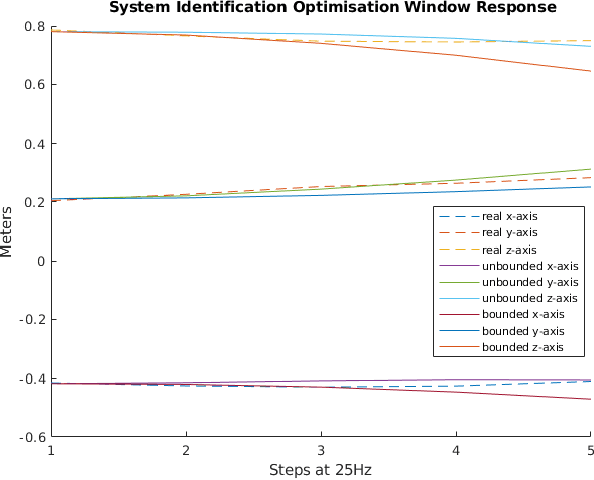
We propose a novel iterative approach for crossing the reality gap that utilises live robot rollouts and differentiable physics. Our method, RealityGrad, demonstrates for the first time, an efficient sim2real transfer in combination with a real2sim model optimisation for closing the reality gap. Differentiable physics has become an alluring alternative to classical rigid-body simulation due to the current culmination of automatic differentiation libraries, compute and non-linear optimisation libraries. Our method builds on this progress and employs differentiable physics for efficient trajectory optimisation. We demonstrate RealitGrad on a dynamic control task for a serial link robot manipulator and present results that show its efficiency and ability to quickly improve not just the robot's performance in real world tasks but also enhance the simulation model for future tasks. One iteration of RealityGrad takes less than 22 minutes on a desktop computer while reducing the error by 2/3, making it efficient compared to other sim2real methods in both compute and time. Our methodology and application of differentiable physics establishes a promising approach for crossing the reality gap and has great potential for scaling to complex environments.
EGAD! an Evolved Grasping Analysis Dataset for diversity and reproducibility in robotic manipulation
Mar 03, 2020

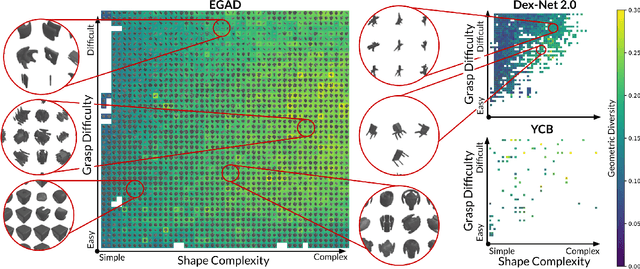
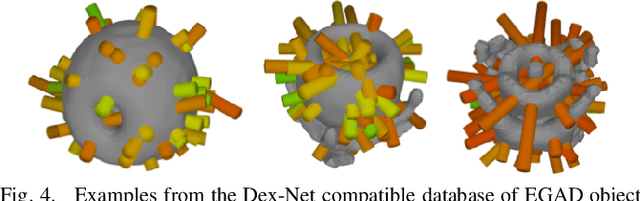
We present the Evolved Grasping Analysis Dataset (EGAD), comprising over 2000 generated objects aimed at training and evaluating robotic visual grasp detection algorithms. The objects in EGAD are geometrically diverse, filling a space ranging from simple to complex shapes and from easy to difficult to grasp, compared to other datasets for robotic grasping, which may be limited in size or contain only a small number of object classes. Additionally, we specify a set of 49 diverse 3D-printable evaluation objects to encourage reproducible testing of robotic grasping systems across a range of complexity and difficulty. The dataset, code and videos can be found at https://dougsm.github.io/egad/
Benchmarking Simulated Robotic Manipulation through a Real World Dataset
Nov 27, 2019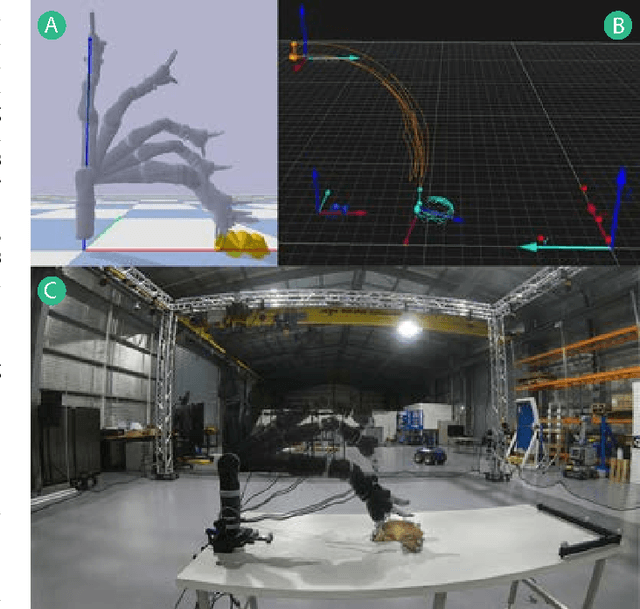

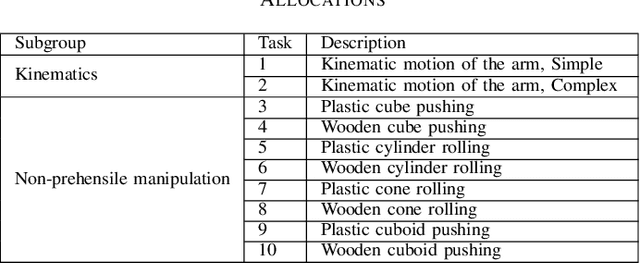
We present a benchmark to facilitate simulated manipulation; an attempt to overcome the obstacles of physical benchmarks through the distribution of a real world, ground truth dataset. Users are given various simulated manipulation tasks with assigned protocols having the objective of replicating the real world results of a recorded dataset. The benchmark comprises of a range of metrics used to characterise the successes of submitted environments whilst providing insight into their deficiencies. We apply our benchmark to two simulation environments, PyBullet and V-Rep, and publish the results. All materials required to benchmark an environment, including protocols and the dataset, can be found at the benchmarks' website https://research.csiro.au/robotics/manipulation-benchmark/.
Evaluating task-agnostic exploration for fixed-batch learning of arbitrary future tasks
Nov 20, 2019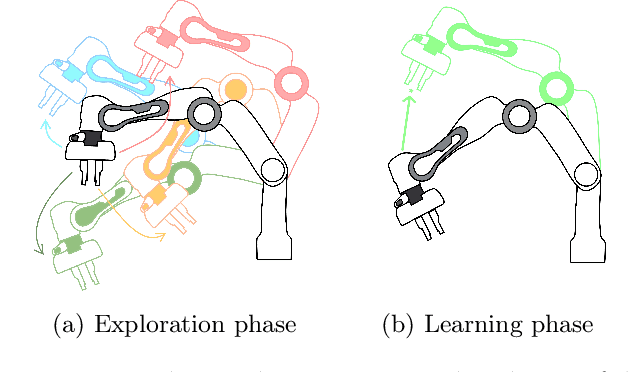
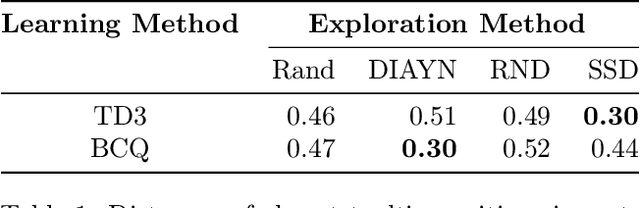

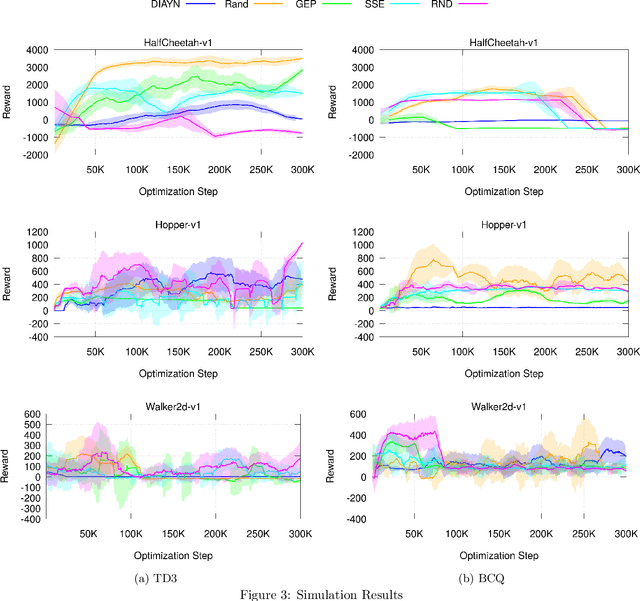
Deep reinforcement learning has been shown to solve challenging tasks where large amounts of training experience is available, usually obtained online while learning the task. Robotics is a significant potential application domain for many of these algorithms, but generating robot experience in the real world is expensive, especially when each task requires a lengthy online training procedure. Off-policy algorithms can in principle learn arbitrary tasks from a diverse enough fixed dataset. In this work, we evaluate popular exploration methods by generating robotics datasets for the purpose of learning to solve tasks completely offline without any further interaction in the real world. We present results on three popular continuous control tasks in simulation, as well as continuous control of a high-dimensional real robot arm. Code documenting all algorithms, experiments, and hyper-parameters is available at https://github.com/qutrobotlearning/batchlearning.
A Perceived Environment Design using a Multi-Modal Variational Autoencoder for learning Active-Sensing
Nov 01, 2019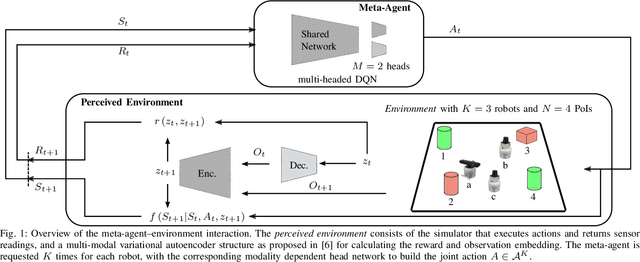
This contribution comprises the interplay between a multi-modal variational autoencoder and an environment to a perceived environment, on which an agent can act. Furthermore, we conclude our work with a comparison to curiosity-driven learning.
Ctrl-Z: Recovering from Instability in Reinforcement Learning
Oct 09, 2019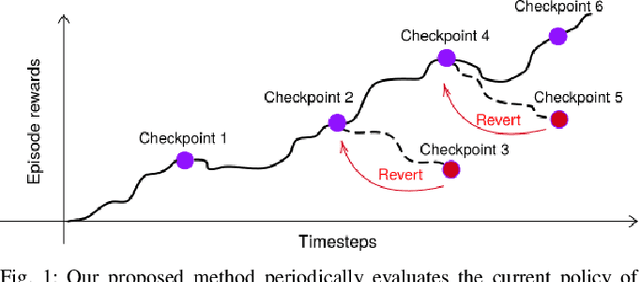
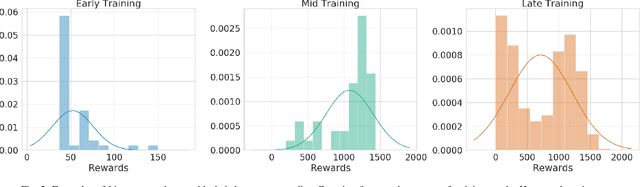

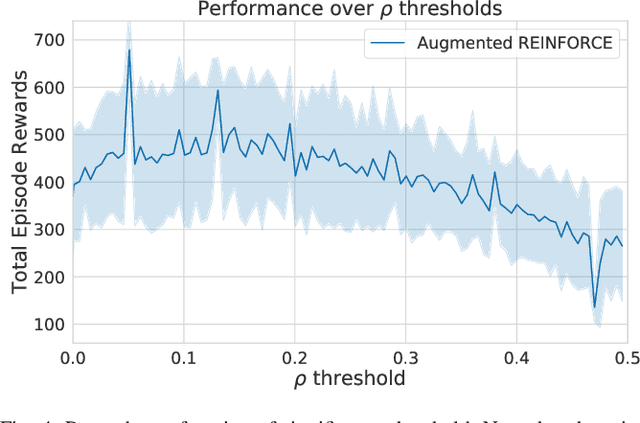
When learning behavior, training data is often generated by the learner itself; this can result in unstable training dynamics, and this problem has particularly important applications in safety-sensitive real-world control tasks such as robotics. In this work, we propose a principled and model-agnostic approach to mitigate the issue of unstable learning dynamics by maintaining a history of a reinforcement learning agent over the course of training, and reverting to the parameters of a previous agent whenever performance significantly decreases. We develop techniques for evaluating this performance through statistical hypothesis testing of continued improvement, and evaluate them on a standard suite of challenging benchmark tasks involving continuous control of simulated robots. We show improvements over state-of-the-art reinforcement learning algorithms in performance and robustness to hyperparameters, outperforming DDPG in 5 out of 6 evaluation environments and showing no decrease in performance with TD3, which is known to be relatively stable. In this way, our approach takes an important step towards increasing data efficiency and stability in training for real-world robotic applications.
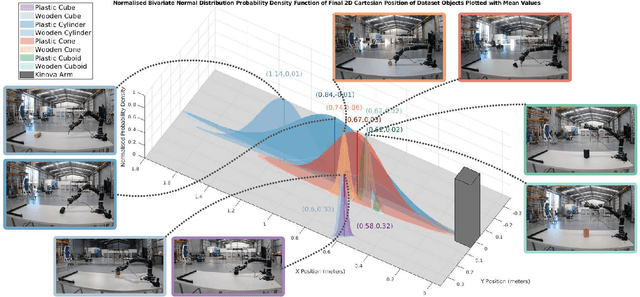
Quantifying the Reality Gap in Robotic Manipulation Tasks
Nov 08, 2018


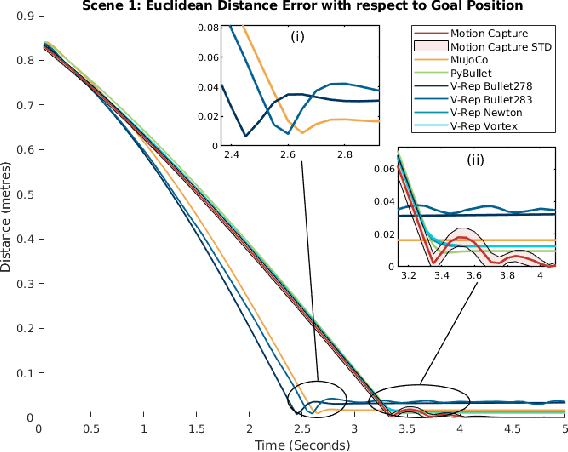
We quantify the accuracy of various simulators compared to a real world robotic reaching and interaction task. Simulators are used in robotics to design solutions for real world hardware without the need for physical access. The `reality gap' prevents solutions developed or learnt in simulation from performing well, or at at all, when transferred to real-world hardware. Making use of a Kinova robotic manipulator and a motion capture system, we record a ground truth enabling comparisons with various simulators, and present quantitative data for various manipulation-oriented robotic tasks. We show the relative strengths and weaknesses of numerous contemporary simulators, highlighting areas of significant discrepancy, and assisting researchers in the field in their selection of appropriate simulators for their use cases. All code and parameter listings are publicly available from: https://bitbucket.csiro.au/scm/~col549/quantifying-the-reality-gap-in-robotic-manipulation-tasks.git .
Multi-View Picking: Next-best-view Reaching for Improved Grasping in Clutter
Sep 23, 2018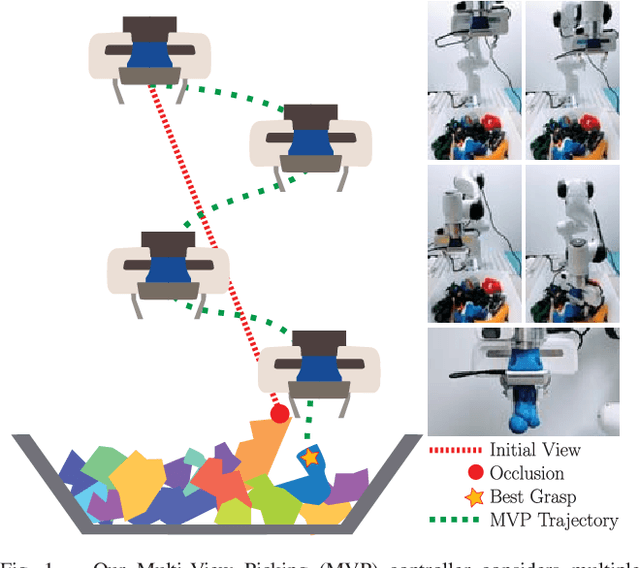
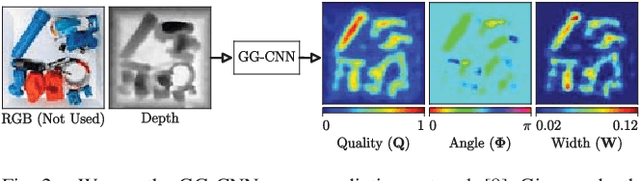
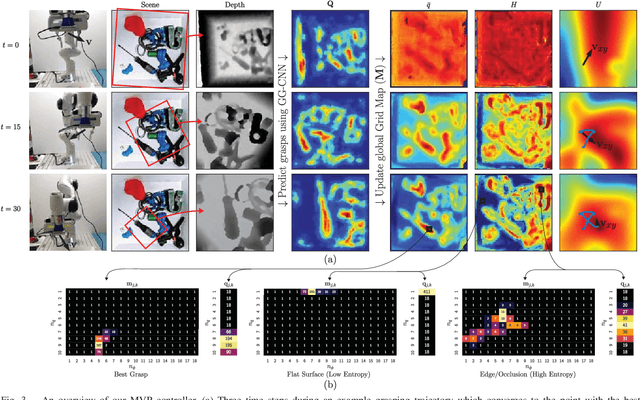

Camera viewpoint selection is an important aspect of visual grasp detection, especially in clutter where many occlusions are present. Where other approaches use a static camera position or fixed data collection routines, our Multi-View Picking (MVP) controller uses an active perception approach to choose informative viewpoints based directly on a distribution of grasp pose estimates in real time, reducing uncertainty in the grasp poses caused by clutter and occlusions. In trials of grasping 20 objects from clutter, our MVP controller achieves 80% grasp success, outperforming a single-viewpoint grasp detector by 12%. We also show that our approach is both more accurate and more efficient than approaches which consider multiple fixed viewpoints.
Zero-shot Sim-to-Real Transfer with Modular Priors
Sep 20, 2018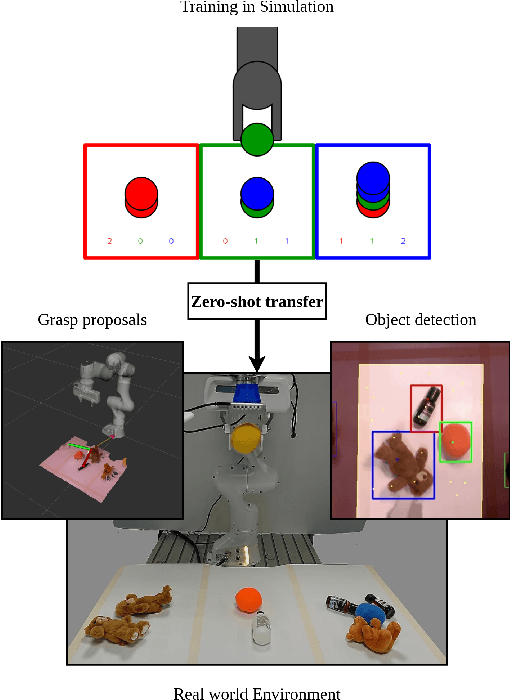
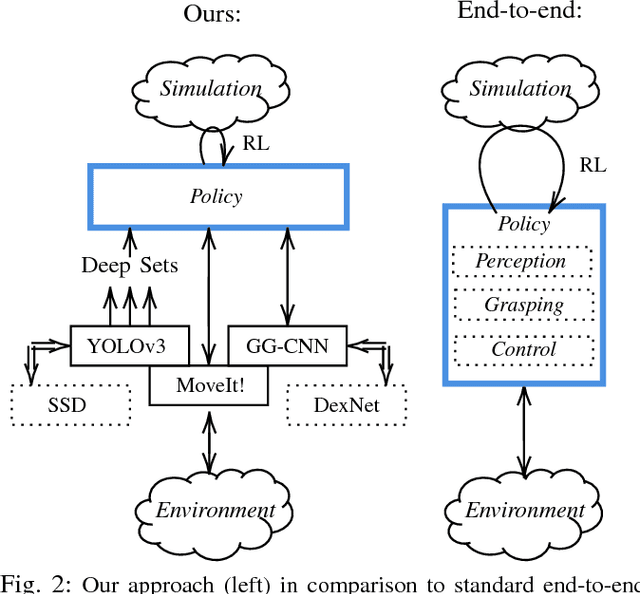
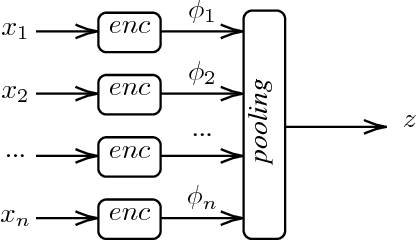

Current end-to-end Reinforcement Learning (RL) approaches are severely limited by restrictively large search spaces and are prone to overfitting to their training environment. This is because in end-to-end RL perception, decision-making and low-level control are all being learned jointly from very sparse reward signals, with little capability of incorporating prior knowledge or existing algorithms. In this work, we propose a novel framework that effectively decouples RL for high-level decision making from low-level perception and control. This allows us to transfer a learned policy from a highly abstract simulation to a real robot without requiring any transfer learning. We therefore coin our approach zero-shot sim-to-real transfer. We successfully demonstrate our approach on the robot manipulation task of object sorting. A key component of our approach is a deep sets encoder that enables us to reinforcement learn the high-level policy based on the variable-length output of a pre-trained object detector, instead of learning from raw pixels. We show that this method can learn effective policies within mere minutes of highly simplified simulation. The learned policies can be directly deployed on a robot without further training, and generalize to variations of the task unseen during training.