 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconfigurable Robots for Scaling Reef Restoration
May 10, 2022



Coral reefs are under increasing threat from the impacts of climate change. Whilst current restoration approaches are effective, they require significant human involvement and equipment, and have limited deployment scale. Harvesting wild coral spawn from mass spawning events, rearing them to the larval stage and releasing the larvae onto degraded reefs is an emerging solution for reef restoration known as coral reseeding. This paper presents a reconfigurable autonomous surface vehicle system that can eliminate risky diving, cover greater areas with coral larvae, has a sensory suite for additional data measurement, and requires minimal non-technical expert training. A key feature is an on-board real-time benthic substrate classification model that predicts when to release larvae to increase settlement rate and ultimately, survivability. The presented robot design is reconfigurable, light weight, scalable, and easy to transport. Results from restoration deployments at Lizard Island demonstrate improved coral larvae release onto appropriate coral substrate, while also achieving 21.8 times more area coverage compared to manual methods.
Zero-shot Sim-to-Real Transfer with Modular Priors
Sep 20, 2018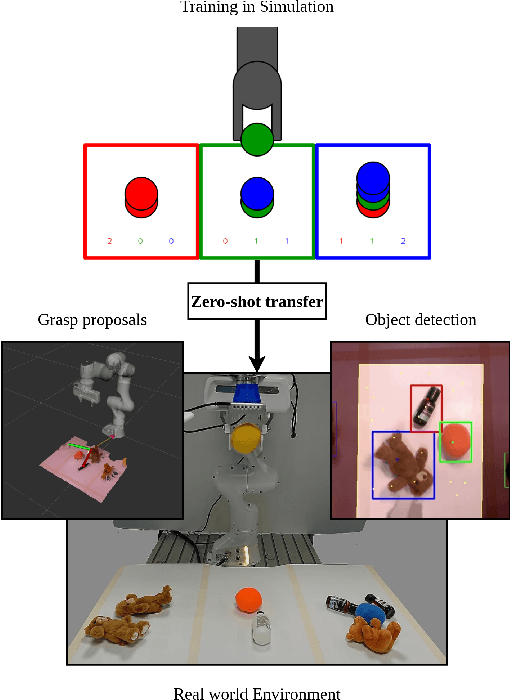
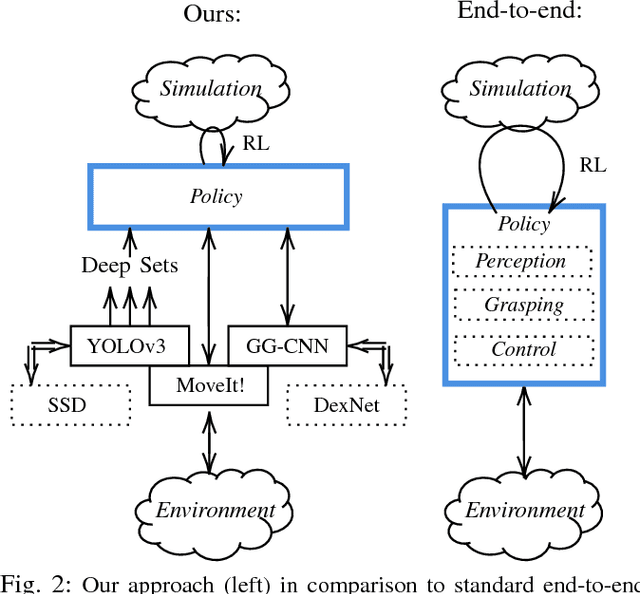
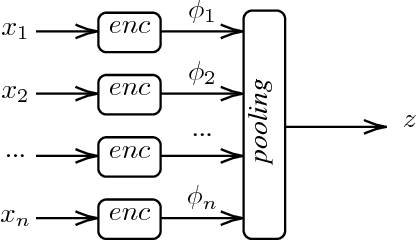

Current end-to-end Reinforcement Learning (RL) approaches are severely limited by restrictively large search spaces and are prone to overfitting to their training environment. This is because in end-to-end RL perception, decision-making and low-level control are all being learned jointly from very sparse reward signals, with little capability of incorporating prior knowledge or existing algorithms. In this work, we propose a novel framework that effectively decouples RL for high-level decision making from low-level perception and control. This allows us to transfer a learned policy from a highly abstract simulation to a real robot without requiring any transfer learning. We therefore coin our approach zero-shot sim-to-real transfer. We successfully demonstrate our approach on the robot manipulation task of object sorting. A key component of our approach is a deep sets encoder that enables us to reinforcement learn the high-level policy based on the variable-length output of a pre-trained object detector, instead of learning from raw pixels. We show that this method can learn effective policies within mere minutes of highly simplified simulation. The learned policies can be directly deployed on a robot without further training, and generalize to variations of the task unseen during training.