 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconfigurable Robots for Scaling Reef Restoration
May 10, 2022



Coral reefs are under increasing threat from the impacts of climate change. Whilst current restoration approaches are effective, they require significant human involvement and equipment, and have limited deployment scale. Harvesting wild coral spawn from mass spawning events, rearing them to the larval stage and releasing the larvae onto degraded reefs is an emerging solution for reef restoration known as coral reseeding. This paper presents a reconfigurable autonomous surface vehicle system that can eliminate risky diving, cover greater areas with coral larvae, has a sensory suite for additional data measurement, and requires minimal non-technical expert training. A key feature is an on-board real-time benthic substrate classification model that predicts when to release larvae to increase settlement rate and ultimately, survivability. The presented robot design is reconfigurable, light weight, scalable, and easy to transport. Results from restoration deployments at Lizard Island demonstrate improved coral larvae release onto appropriate coral substrate, while also achieving 21.8 times more area coverage compared to manual methods.
Refractive Light-Field Features for Curved Transparent Objects in Structure from Motion
Apr 17, 2021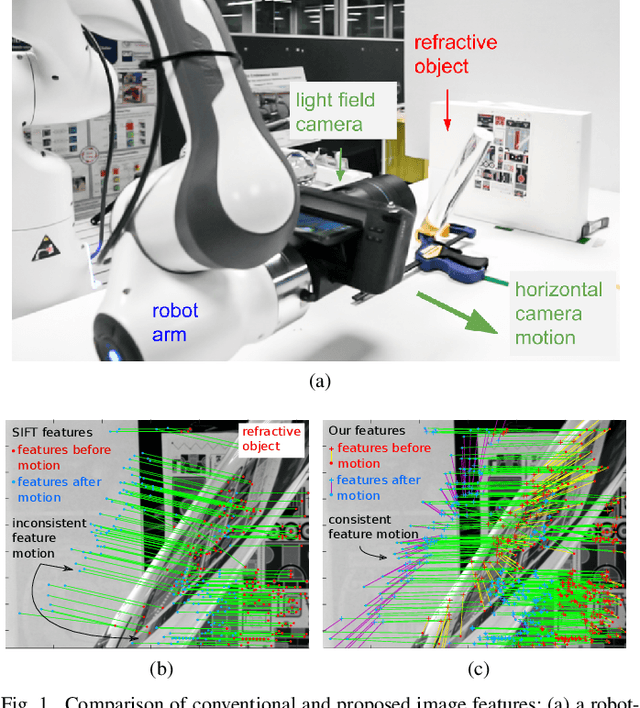
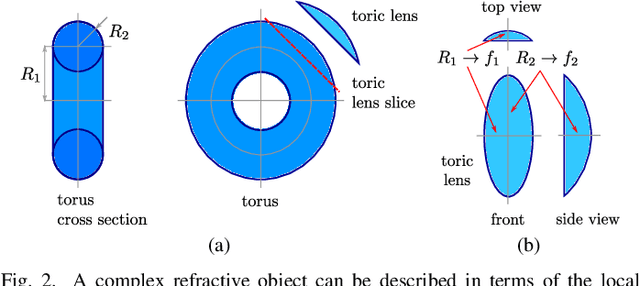
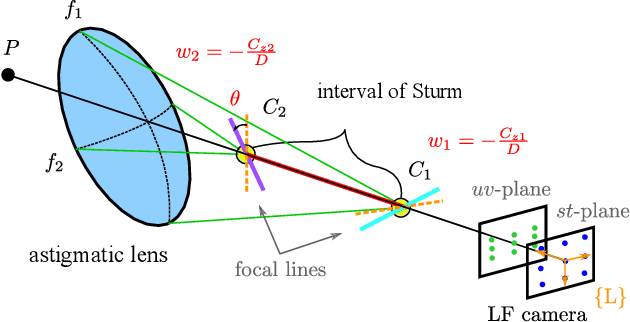
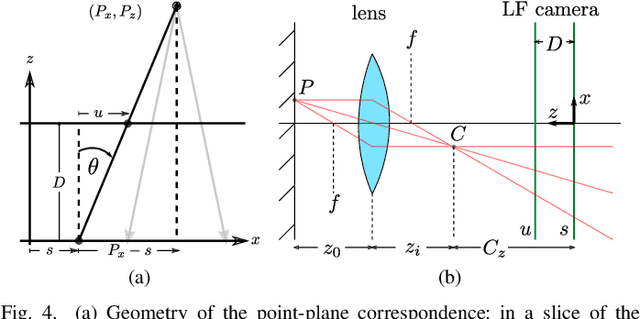
Curved refractive objects are common in the human environment, and have a complex visual appearance that can cause robotic vision algorithms to fail. Light-field cameras allow us to address this challenge by capturing the view-dependent appearance of such objects in a single exposure. We propose a novel image feature for light fields that detects and describes the patterns of light refracted through curved transparent objects. We derive characteristic points based on these features allowing them to be used in place of conventional 2D features. Using our features, we demonstrate improved structure-from-motion performance in challenging scenes containing refractive objects, including quantitative evaluations that show improved camera pose estimates and 3D reconstructions. Additionally, our methods converge 15-35% more frequently than the state-of-the-art. Our method is a critical step towards allowing robots to operate around refractive objects, with applications in manufacturing, quality assurance, pick-and-place, and domestic robots working with acrylic, glass and other transparent materials.
3D Move to See: Multi-perspective visual servoing for improving object views with semantic segmentation
Sep 21, 2018



In this paper, we present a new approach to visual servoing for robotics, referred to as 3D Move to See (3DMTS), based on the principle of finding the next best view using a 3D camera array and a robotic manipulator to obtain multiple samples of the scene from different perspectives. The method uses semantic vision and an objective function applied to each perspective to sample a gradient representing the direction of the next best view. The method is demonstrated within simulation and on a real robotic platform containing a custom 3D camera array for the challenging scenario of robotic harvesting in a highly occluded and unstructured environment. It was shown on a real robotic platform that by moving the end effector using the gradient of an objective function leads to a locally optimal view of the object of interest, even amongst occlusions. The overall performance of the 3DMTS method obtained a mean increase in target size by 29.3% compared to a baseline method using a single RGB-D camera, which obtained 9.17%. The results demonstrate qualitatively and quantitatively that the 3DMTS method performed better in most scenarios, and yielded three times the target size compared to the baseline method. The increased target size in the final view will improve the detection of key features of the object of interest for further manipulation, such as grasping and harvesting.
Distinguishing Refracted Features using Light Field Cameras with Application to Structure from Motion
May 31, 2018
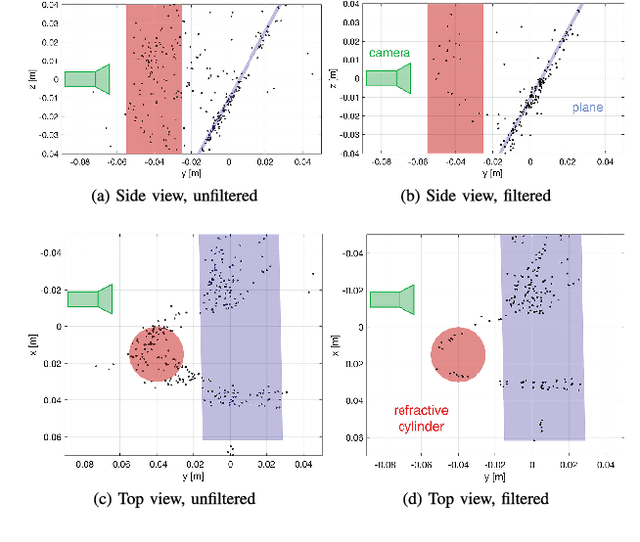


Robots must reliably interact with refractive objects in many applications; however, refractive objects can cause many robotic vision algorithms to become unreliable or even fail, particularly feature-based matching applications, such as structure-from-motion. We propose a method to distinguish between refracted and Lambertian image features using a light field camera. Specifically, we propose to use textural cross-correlation to characterise apparent feature motion in a single light field, and compare this motion to its Lambertian equivalent based on 4D light field geometry. Our refracted feature distinguisher has a 34.3% higher rate of detection compared to state-of-the-art for light fields captured with large baselines relative to the refractive object. Our method also applies to light field cameras with much smaller baselines than previously considered, yielding up to 2 times better detection for 2D-refractive objects, such as a sphere, and up to 8 times better for 1D-refractive objects, such as a cylinder. For structure from motion, we demonstrate that rejecting refracted features using our distinguisher yields up to 42.4% lower reprojection error, and lower failure rate when the robot is approaching refractive objects. Our method lead to more robust robot vision in the presence of refractive objects.
Mirrored Light Field Video Camera Adapter
Dec 16, 2016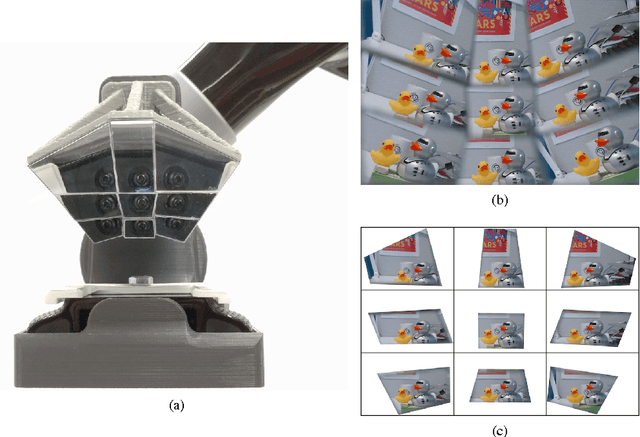

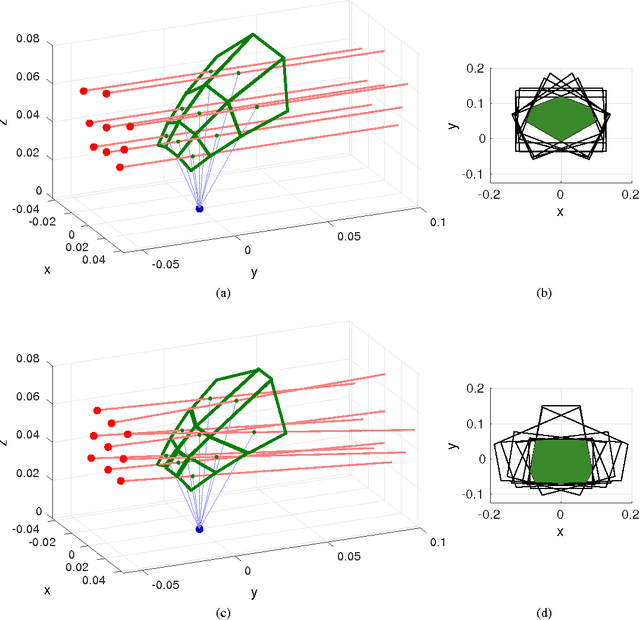

This paper proposes the design of a custom mirror-based light field camera adapter that is cheap, simple in construction, and accessible. Mirrors of different shape and orientation reflect the scene into an upwards-facing camera to create an array of virtual cameras with overlapping field of view at specified depths, and deliver video frame rate light fields. We describe the design, construction, decoding and calibration processes of our mirror-based light field camera adapter in preparation for an open-source release to benefit the robotic vision community.