 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRICE: Reactive Interaction Controller for Cluttered Canopy Environment
Jun 12, 2025Robotic navigation in dense, cluttered environments such as agricultural canopies presents significant challenges due to physical and visual occlusion caused by leaves and branches. Traditional vision-based or model-dependent approaches often fail in these settings, where physical interaction without damaging foliage and branches is necessary to reach a target. We present a novel reactive controller that enables safe navigation for a robotic arm in a contact-rich, cluttered, deformable environment using end-effector position and real-time tactile feedback. Our proposed framework's interaction strategy is based on a trade-off between minimizing disturbance by maneuvering around obstacles and pushing through them to move towards the target. We show that over 35 trials in 3 experimental plant setups with an occluded target, the proposed controller successfully reached the target in all trials without breaking any branch and outperformed the state-of-the-art model-free controller in robustness and adaptability. This work lays the foundation for safe, adaptive interaction in cluttered, contact-rich deformable environments, enabling future agricultural tasks such as pruning and harvesting in plant canopies.
Online Adaptive Traversability Estimation through Interaction for Unstructured, Densely Vegetated Environments
Feb 04, 2025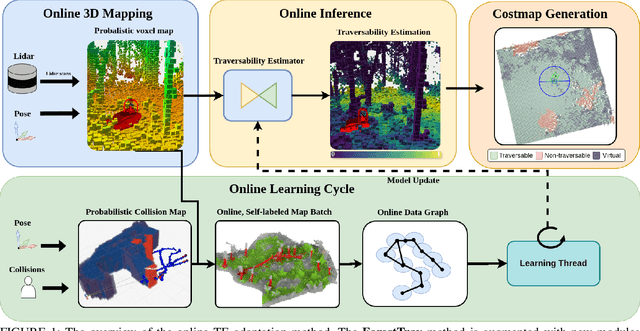

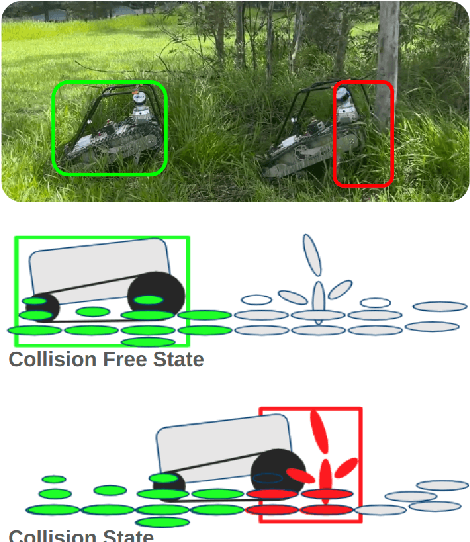
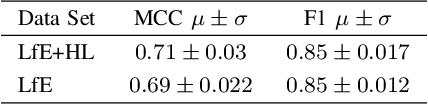
Navigating densely vegetated environments poses significant challenges for autonomous ground vehicles. Learning-based systems typically use prior and in-situ data to predict terrain traversability but often degrade in performance when encountering out-of-distribution elements caused by rapid environmental changes or novel conditions. This paper presents a novel, lidar-only, online adaptive traversability estimation (TE) method that trains a model directly on the robot using self-supervised data collected through robot-environment interaction. The proposed approach utilises a probabilistic 3D voxel representation to integrate lidar measurements and robot experience, creating a salient environmental model. To ensure computational efficiency, a sparse graph-based representation is employed to update temporarily evolving voxel distributions. Extensive experiments with an unmanned ground vehicle in natural terrain demonstrate that the system adapts to complex environments with as little as 8 minutes of operational data, achieving a Matthews Correlation Coefficient (MCC) score of 0.63 and enabling safe navigation in densely vegetated environments. This work examines different training strategies for voxel-based TE methods and offers recommendations for training strategies to improve adaptability. The proposed method is validated on a robotic platform with limited computational resources (25W GPU), achieving accuracy comparable to offline-trained models while maintaining reliable performance across varied environments.
Dynamically Modulating Visual Place Recognition Sequence Length For Minimum Acceptable Performance Scenarios
Jul 01, 2024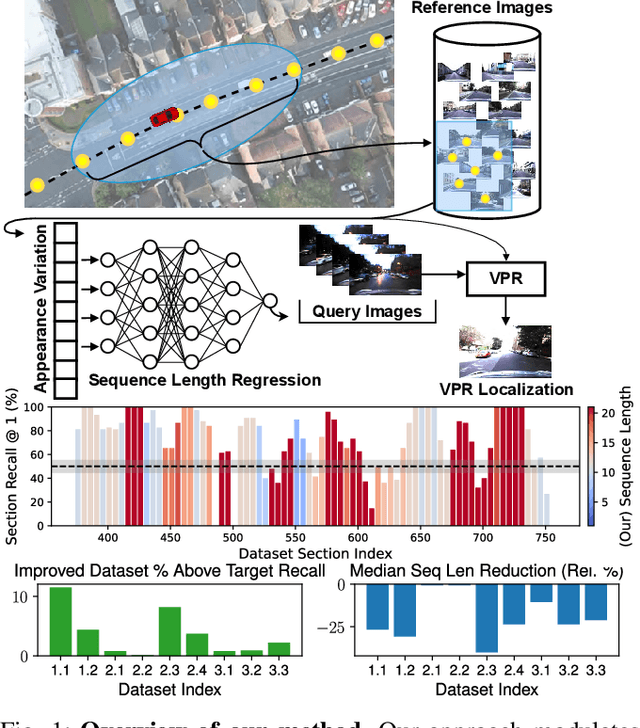
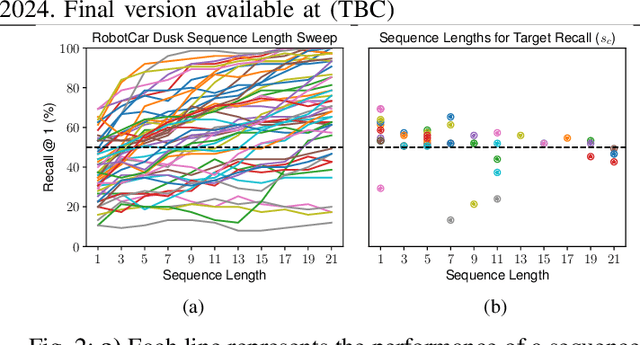
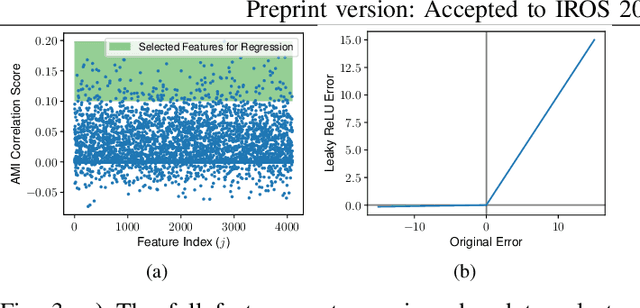

Mobile robots and autonomous vehicles are often required to function in environments where critical position estimates from sensors such as GPS become uncertain or unreliable. Single image visual place recognition (VPR) provides an alternative for localization but often requires techniques such as sequence matching to improve robustness, which incurs additional computation and latency costs. Even then, the sequence length required to localize at an acceptable performance level varies widely; and simply setting overly long fixed sequence lengths creates unnecessary latency, computational overhead, and can even degrade performance. In these scenarios it is often more desirable to meet or exceed a set target performance at minimal expense. In this paper we present an approach which uses a calibration set of data to fit a model that modulates sequence length for VPR as needed to exceed a target localization performance. We make use of a coarse position prior, which could be provided by any other localization system, and capture the variation in appearance across this region. We use the correlation between appearance variation and sequence length to curate VPR features and fit a multilayer perceptron (MLP) for selecting the optimal length. We demonstrate that this method is effective at modulating sequence length to maximize the number of sections in a dataset which meet or exceed a target performance whilst minimizing the median length used. We show applicability across several datasets and reveal key phenomena like generalization capabilities, the benefits of curating features and the utility of non-state-of-the-art feature extractors with nuanced properties.
ForestTrav: Accurate, Efficient and Deployable Forest Traversability Estimation for Autonomous Ground Vehicles
May 22, 2023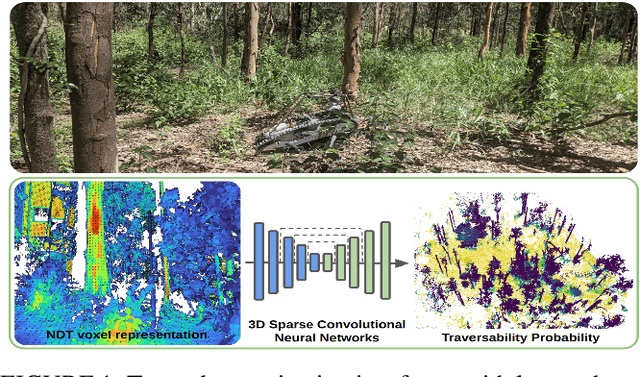
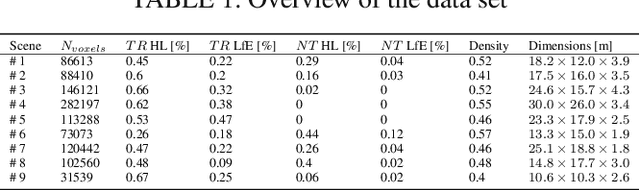
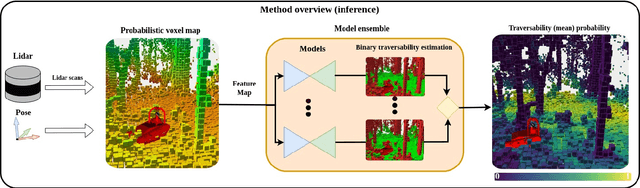
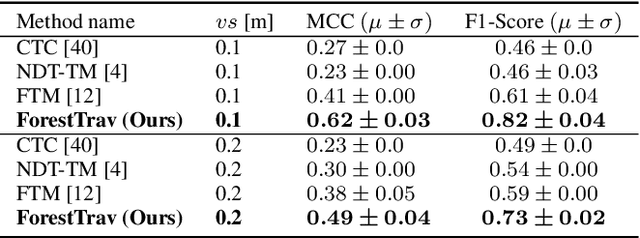
Autonomous navigation in unstructured vegetated environments remains an open challenge. To successfully operate in these settings, ground vehicles must assess the traversability of the environment and determine which vegetation is pliable enough to push through. In this work, we propose a novel method that combines a high-fidelity and feature-rich 3D voxel representation while leveraging the structural context and sparseness of \acfp{SCNN} to assess \ac{TE} in densely vegetated environments. The proposed method is thoroughly evaluated on an accurately-labeled real-world data set that we provide to the community. It is shown to outperform state-of-the-art methods by a significant margin (0.59 vs. 0.39 MCC score at 0.1m voxel resolution) in challenging scenes and to generalize to unseen environments. In addition, the method is economical in the amount of training data and training time required: a model is trained in minutes on a desktop computer. We show that by exploiting the context of the environment, our method can use different feature combinations with only limited performance variations. For example, our approach can be used with lidar-only features, whilst still assessing complex vegetated environments accurately, which was not demonstrated previously in the literature in such environments. In addition, we propose an approach to assess a traversability estimator's sensitivity to information quality and show our method's sensitivity is low.
Improving Road Segmentation in Challenging Domains Using Similar Place Priors
May 27, 2022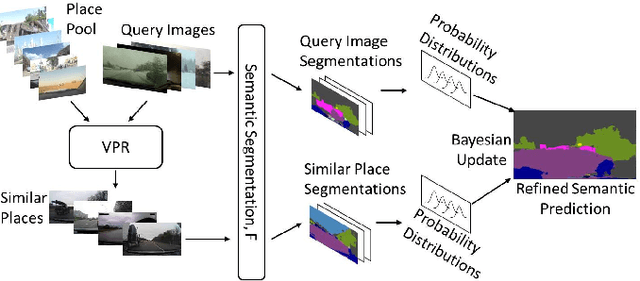
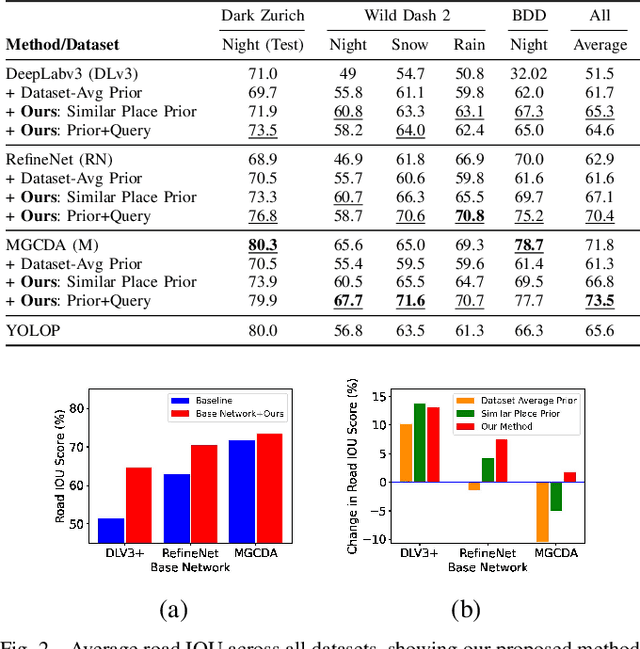
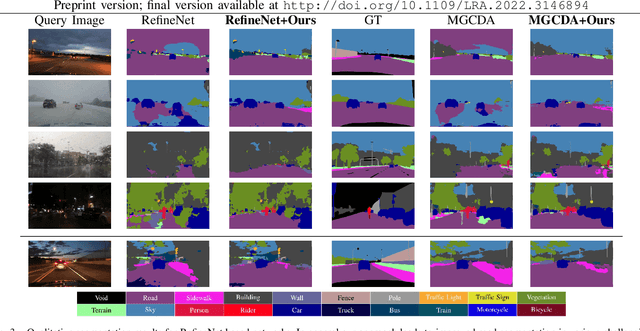
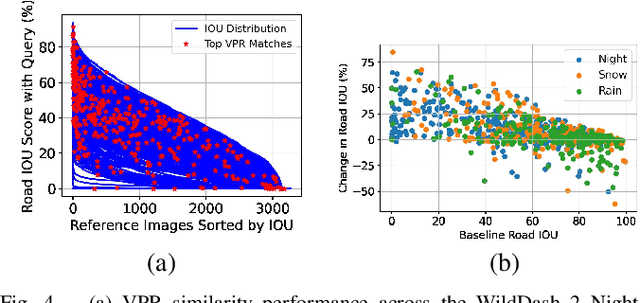
Road segmentation in challenging domains, such as night, snow or rain, is a difficult task. Most current approaches boost performance using fine-tuning, domain adaptation, style transfer, or by referencing previously acquired imagery. These approaches share one or more of three significant limitations: a reliance on large amounts of annotated training data that can be costly to obtain, both anticipation of and training data from the type of environmental conditions expected at inference time, and/or imagery captured from a previous visit to the location. In this research, we remove these restrictions by improving road segmentation based on similar places. We use Visual Place Recognition (VPR) to find similar but geographically distinct places, and fuse segmentations for query images and these similar place priors using a Bayesian approach and novel segmentation quality metric. Ablation studies show the need to re-evaluate notions of VPR utility for this task. We demonstrate the system achieving state-of-the-art road segmentation performance across multiple challenging condition scenarios including night time and snow, without requiring any prior training or previous access to the same geographical locations. Furthermore, we show that this method is network agnostic, improves multiple baseline techniques and is competitive against methods specialised for road prediction.
* Accepted into IEEE Robotics and Automation Letters (RA-L) and presented at IEEE International Conference on Robotics and Automation (ICRA 2022)
PointCrack3D: Crack Detection in Unstructured Environments using a 3D-Point-Cloud-Based Deep Neural Network
Nov 23, 2021


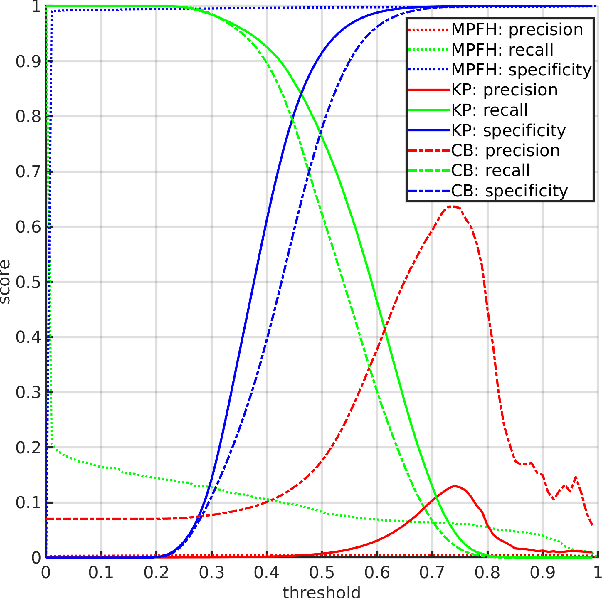
Surface cracks on buildings, natural walls and underground mine tunnels can indicate serious structural integrity issues that threaten the safety of the structure and people in the environment. Timely detection and monitoring of cracks are crucial to managing these risks, especially if the systems can be made highly automated through robots. Vision-based crack detection algorithms using deep neural networks have exhibited promise for structured surfaces such as walls or civil engineering tunnels, but little work has addressed highly unstructured environments such as rock cliffs and bare mining tunnels. To address this challenge, this paper presents PointCrack3D, a new 3D-point-cloud-based crack detection algorithm for unstructured surfaces. The method comprises three key components: an adaptive down-sampling method that maintains sufficient crack point density, a DNN that classifies each point as crack or non-crack, and a post-processing clustering method that groups crack points into crack instances. The method was validated experimentally on a new large natural rock dataset, comprising coloured LIDAR point clouds spanning more than 900 m^2 and 412 individual cracks. Results demonstrate a crack detection rate of 97% overall and 100% for cracks with a maximum width of more than 3 cm, significantly outperforming the state of the art. Furthermore, for cross-validation, PointCrack3D was applied to an entirely new dataset acquired in different locations and not used at all in training and shown to detect 100% of its crack instances. We also characterise the relationship between detection performance, crack width and number of points per crack, providing a foundation upon which to make decisions about both practical deployments and future research directions.
Refractive Light-Field Features for Curved Transparent Objects in Structure from Motion
Apr 17, 2021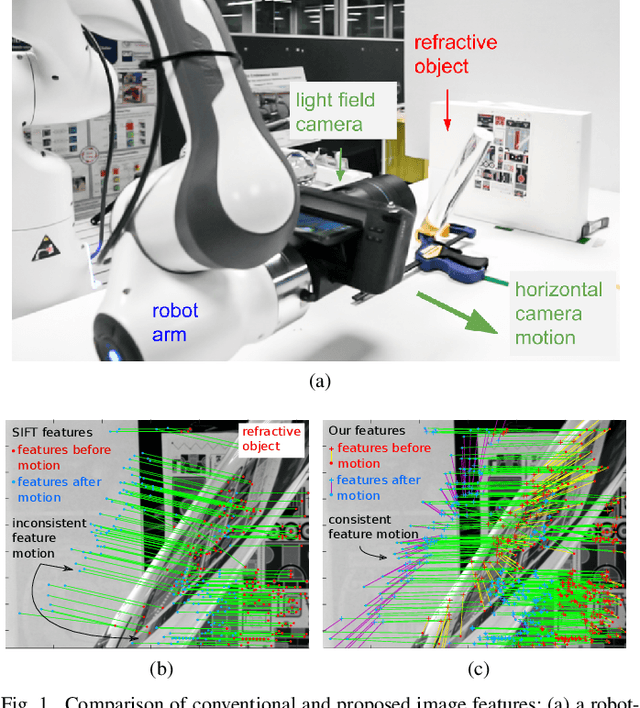
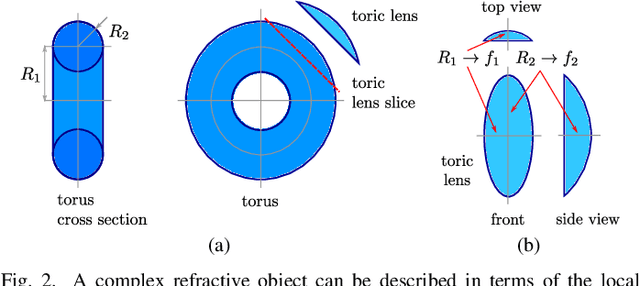
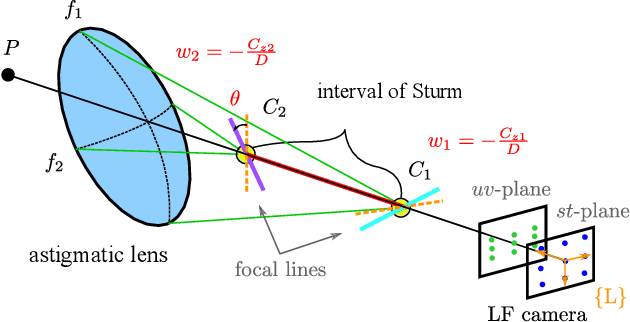
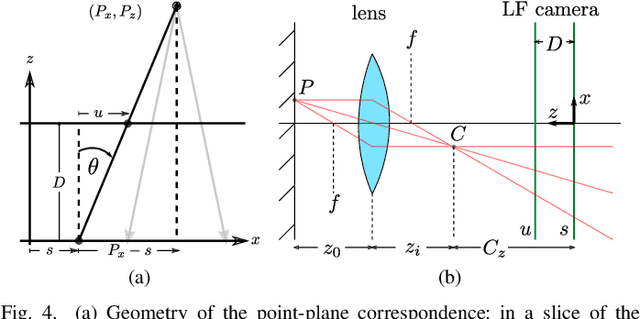
Curved refractive objects are common in the human environment, and have a complex visual appearance that can cause robotic vision algorithms to fail. Light-field cameras allow us to address this challenge by capturing the view-dependent appearance of such objects in a single exposure. We propose a novel image feature for light fields that detects and describes the patterns of light refracted through curved transparent objects. We derive characteristic points based on these features allowing them to be used in place of conventional 2D features. Using our features, we demonstrate improved structure-from-motion performance in challenging scenes containing refractive objects, including quantitative evaluations that show improved camera pose estimates and 3D reconstructions. Additionally, our methods converge 15-35% more frequently than the state-of-the-art. Our method is a critical step towards allowing robots to operate around refractive objects, with applications in manufacturing, quality assurance, pick-and-place, and domestic robots working with acrylic, glass and other transparent materials.
Ctrl-Z: Recovering from Instability in Reinforcement Learning
Oct 09, 2019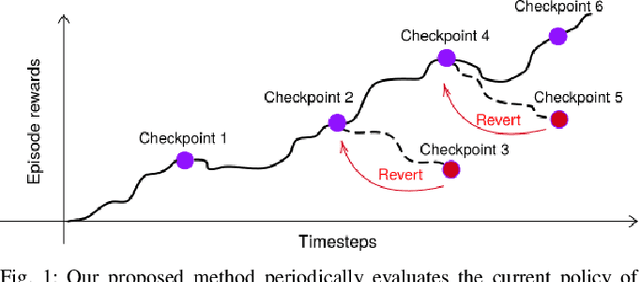
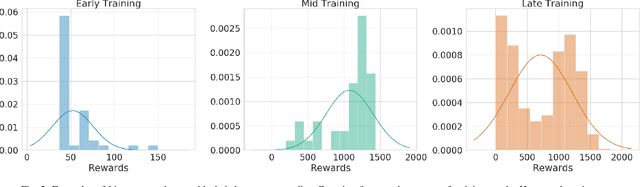

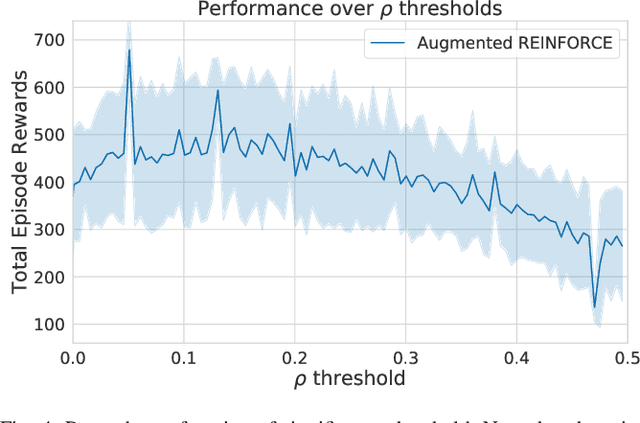
When learning behavior, training data is often generated by the learner itself; this can result in unstable training dynamics, and this problem has particularly important applications in safety-sensitive real-world control tasks such as robotics. In this work, we propose a principled and model-agnostic approach to mitigate the issue of unstable learning dynamics by maintaining a history of a reinforcement learning agent over the course of training, and reverting to the parameters of a previous agent whenever performance significantly decreases. We develop techniques for evaluating this performance through statistical hypothesis testing of continued improvement, and evaluate them on a standard suite of challenging benchmark tasks involving continuous control of simulated robots. We show improvements over state-of-the-art reinforcement learning algorithms in performance and robustness to hyperparameters, outperforming DDPG in 5 out of 6 evaluation environments and showing no decrease in performance with TD3, which is known to be relatively stable. In this way, our approach takes an important step towards increasing data efficiency and stability in training for real-world robotic applications.
LookUP: Vision-Only Real-Time Precise Underground Localisation for Autonomous Mining Vehicles
Mar 20, 2019

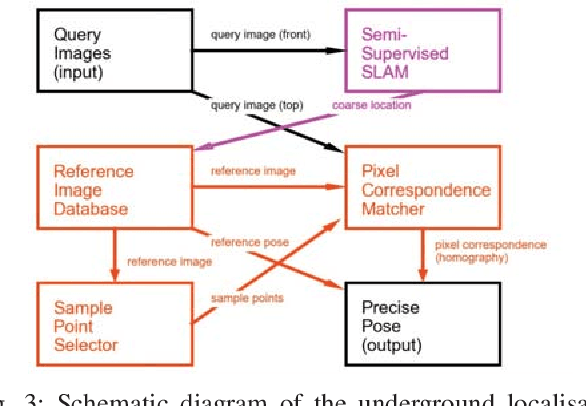

A key capability for autonomous underground mining vehicles is real-time accurate localisation. While significant progress has been made, currently deployed systems have several limitations ranging from dependence on costly additional infrastructure to failure of both visual and range sensor-based techniques in highly aliased or visually challenging environments. In our previous work, we presented a lightweight coarse vision-based localisation system that could map and then localise to within a few metres in an underground mining environment. However, this level of precision is insufficient for providing a cheaper, more reliable vision-based automation alternative to current range sensor-based systems. Here we present a new precision localisation system dubbed "LookUP", which learns a neural-network-based pixel sampling strategy for estimating homographies based on ceiling-facing cameras without requiring any manual labelling. This new system runs in real time on limited computation resource and is demonstrated on two different underground mine sites, achieving real time performance at ~5 frames per second and a much improved average localisation error of ~1.2 metre.
Distinguishing Refracted Features using Light Field Cameras with Application to Structure from Motion
May 31, 2018
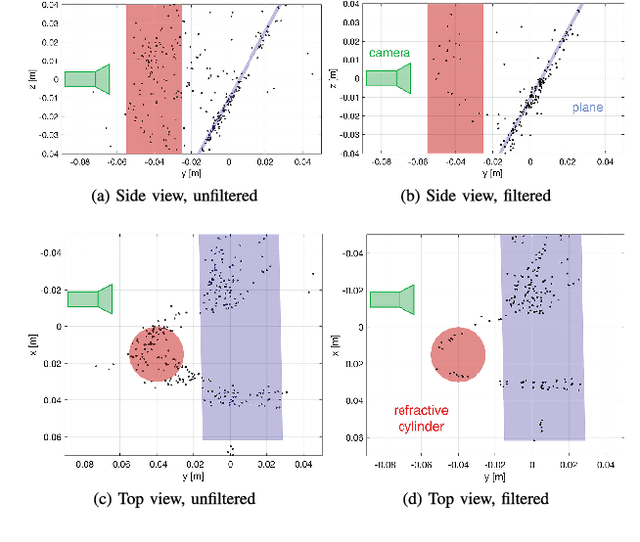


Robots must reliably interact with refractive objects in many applications; however, refractive objects can cause many robotic vision algorithms to become unreliable or even fail, particularly feature-based matching applications, such as structure-from-motion. We propose a method to distinguish between refracted and Lambertian image features using a light field camera. Specifically, we propose to use textural cross-correlation to characterise apparent feature motion in a single light field, and compare this motion to its Lambertian equivalent based on 4D light field geometry. Our refracted feature distinguisher has a 34.3% higher rate of detection compared to state-of-the-art for light fields captured with large baselines relative to the refractive object. Our method also applies to light field cameras with much smaller baselines than previously considered, yielding up to 2 times better detection for 2D-refractive objects, such as a sphere, and up to 8 times better for 1D-refractive objects, such as a cylinder. For structure from motion, we demonstrate that rejecting refracted features using our distinguisher yields up to 42.4% lower reprojection error, and lower failure rate when the robot is approaching refractive objects. Our method lead to more robust robot vision in the presence of refractive objects.