 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFilter Early, Match Late: Improving Network-Based Visual Place Recognition
Jun 21, 2019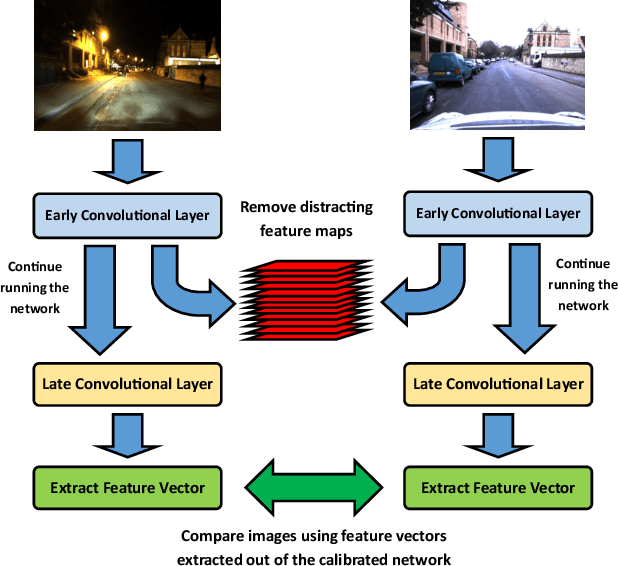
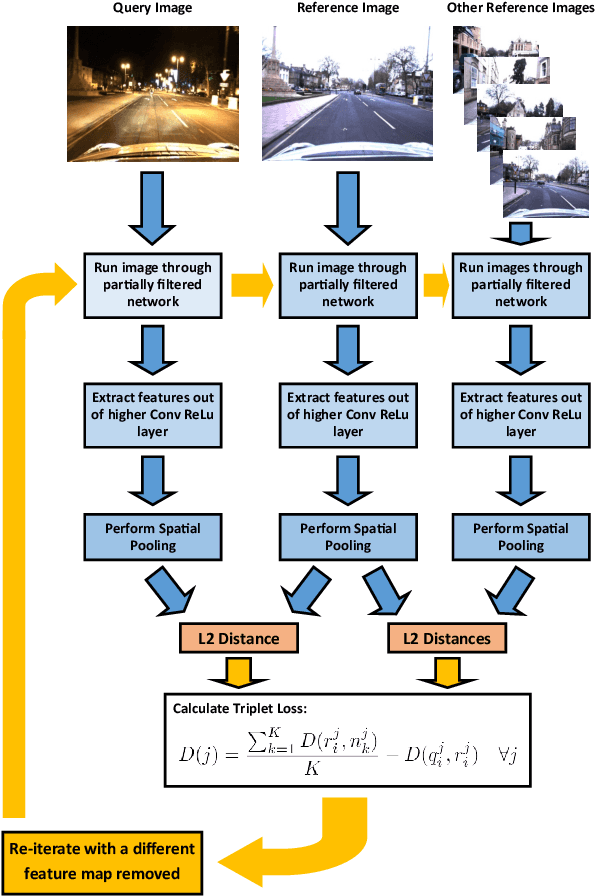
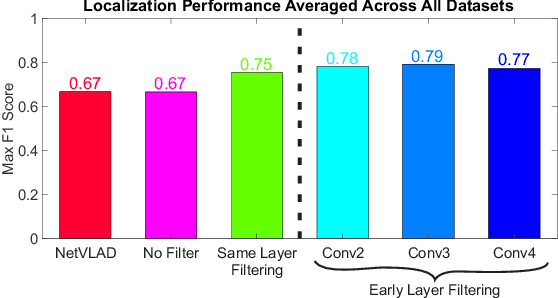

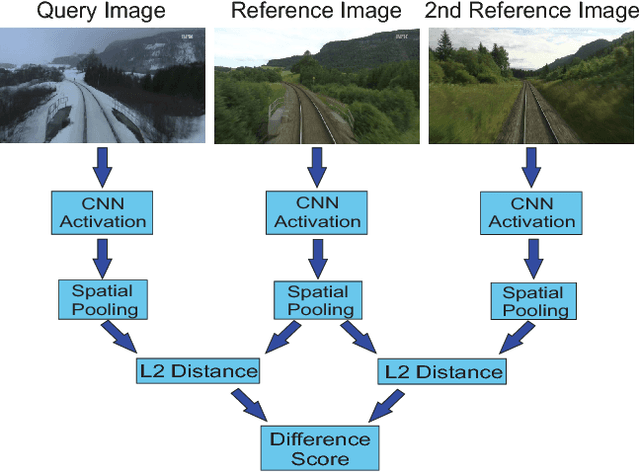
CNNs have excelled at performing place recognition over time, particularly when the neural network is optimized for localization in the current environmental conditions. In this paper we investigate the concept of feature map filtering, where, rather than using all the activations within a convolutional tensor, only the most useful activations are used. Since specific feature maps encode different visual features, the objective is to remove feature maps that are detract from the ability to recognize a location across appearance changes. Our key innovation is to filter the feature maps in an early convolutional layer, but then continue to run the network and extract a feature vector using a later layer in the same network. By filtering early visual features and extracting a feature vector from a higher, more viewpoint invariant later layer, we demonstrate improved condition and viewpoint invariance. Our approach requires image pairs for training from the deployment environment, but we show that state-of-the-art performance can regularly be achieved with as little as a single training image pair. An exhaustive experimental analysis is performed to determine the full scope of causality between early layer filtering and late layer extraction. For validity, we use three datasets: Oxford RobotCar, Nordland, and Gardens Point, achieving overall superior performance to NetVLAD. The work provides a number of new avenues for exploring CNN optimizations, without full re-training.
LookUP: Vision-Only Real-Time Precise Underground Localisation for Autonomous Mining Vehicles
Mar 20, 2019

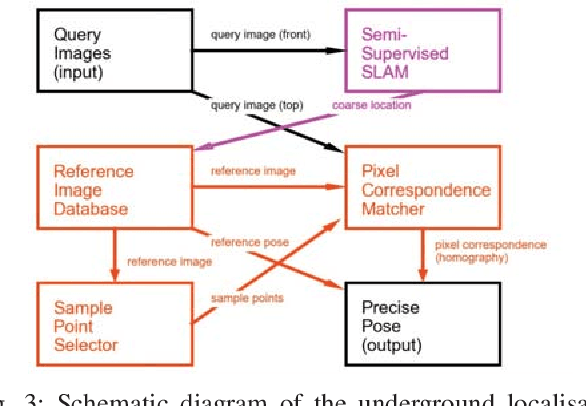

A key capability for autonomous underground mining vehicles is real-time accurate localisation. While significant progress has been made, currently deployed systems have several limitations ranging from dependence on costly additional infrastructure to failure of both visual and range sensor-based techniques in highly aliased or visually challenging environments. In our previous work, we presented a lightweight coarse vision-based localisation system that could map and then localise to within a few metres in an underground mining environment. However, this level of precision is insufficient for providing a cheaper, more reliable vision-based automation alternative to current range sensor-based systems. Here we present a new precision localisation system dubbed "LookUP", which learns a neural-network-based pixel sampling strategy for estimating homographies based on ceiling-facing cameras without requiring any manual labelling. This new system runs in real time on limited computation resource and is demonstrated on two different underground mine sites, achieving real time performance at ~5 frames per second and a much improved average localisation error of ~1.2 metre.
Multi-Process Fusion: Visual Place Recognition Using Multiple Image Processing Methods
Mar 08, 2019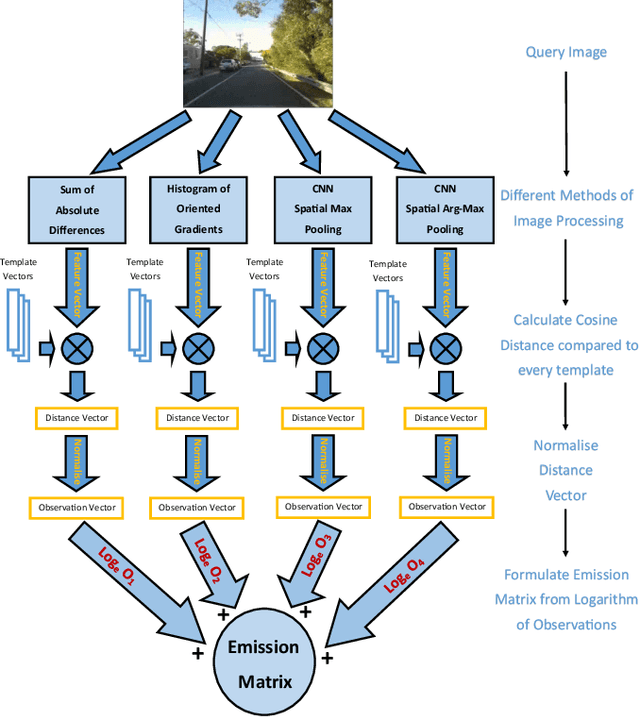
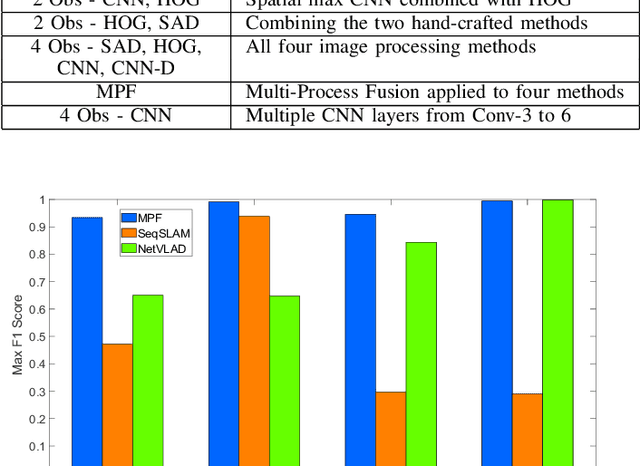
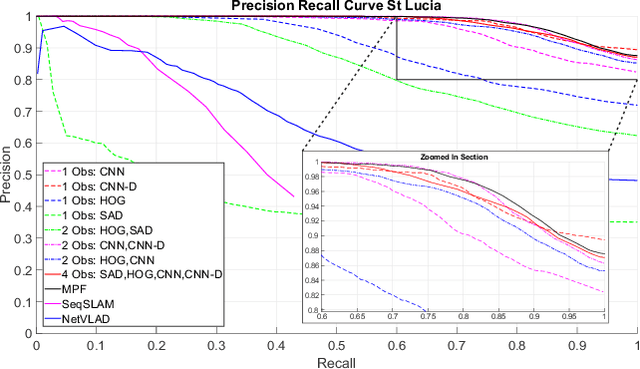
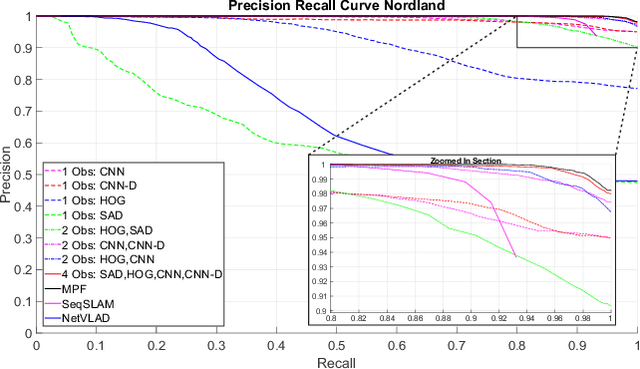
Typical attempts to improve the capability of visual place recognition techniques include the use of multi-sensor fusion and integration of information over time from image sequences. These approaches can improve performance but have disadvantages including the need for multiple physical sensors and calibration processes, both for multiple sensors and for tuning the image matching sequence length. In this paper we address these shortcomings with a novel "multi-sensor" fusion approach applied to multiple image processing methods for a single visual image stream, combined with a dynamic sequence matching length technique and an automatic processing method weighting scheme. In contrast to conventional single method approaches, our approach reduces the performance requirements of a single image processing methodology, instead requiring that within the suite of image processing methods, at least one performs well in any particular environment. In comparison to static sequence length techniques, the dynamic sequence matching technique enables reduced localization latencies through analysis of recognition quality metrics when re-entering familiar locations. We evaluate our approach on multiple challenging benchmark datasets, achieving superior performance to two state-of-the-art visual place recognition systems across environmental changes including winter to summer, afternoon to morning and night to day. Across the four benchmark datasets our proposed approach achieves an average F1 score of 0.96, compared to 0.78 for NetVLAD and 0.49 for SeqSLAM. We provide source code for the multi-fusion method and present analysis explaining how superior performance is achieved despite the multiple, disparate, image processing methods all being applied to a single source of imagery, rather than to multiple separate sensors.
* Pre-print version of article published in Robotics and Automation Letters
Feature Map Filtering: Improving Visual Place Recognition with Convolutional Calibration
Oct 30, 2018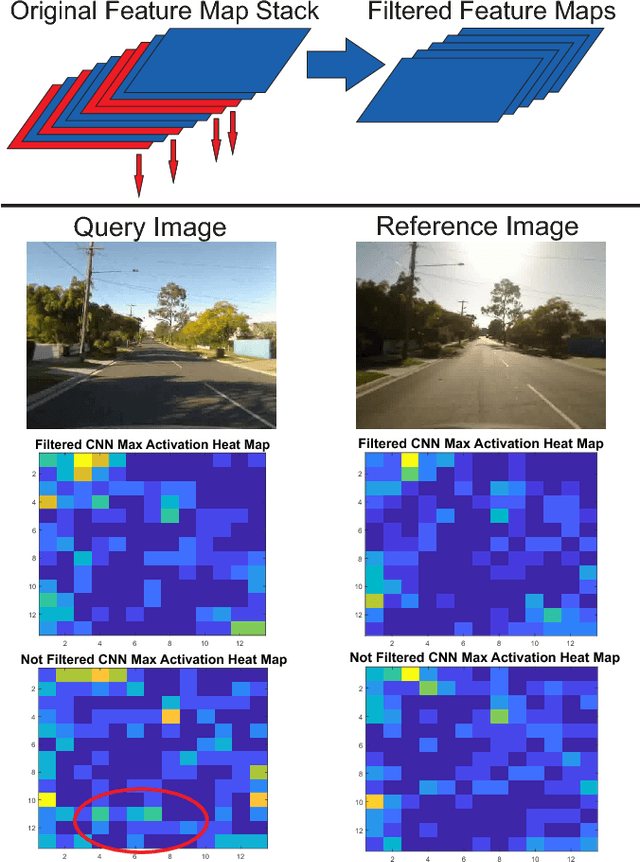
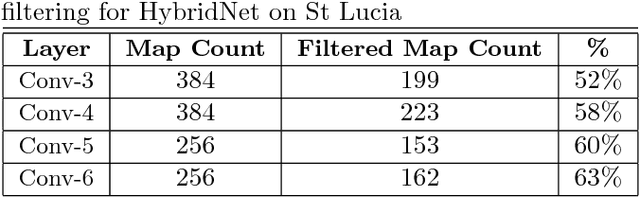
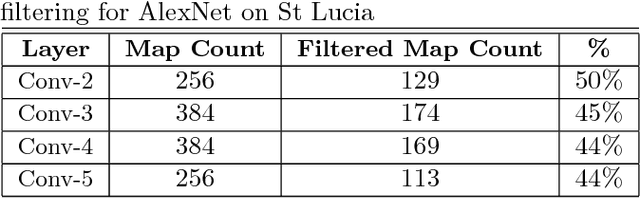
Convolutional Neural Networks (CNNs) have recently been shown to excel at performing visual place recognition under changing appearance and viewpoint. Previously, place recognition has been improved by intelligently selecting relevant spatial keypoints within a convolutional layer and also by selecting the optimal layer to use. Rather than extracting features out of a particular layer, or a particular set of spatial keypoints within a layer, we propose the extraction of features using a subset of the channel dimensionality within a layer. Each feature map learns to encode a different set of weights that activate for different visual features within the set of training images. We propose a method of calibrating a CNN-based visual place recognition system, which selects the subset of feature maps that best encodes the visual features that are consistent between two different appearances of the same location. Using just 50 calibration images, all collected at the beginning of the current environment, we demonstrate a significant and consistent recognition improvement across multiple layers for two different neural networks. We evaluate our proposal on three datasets with different types of appearance changes - afternoon to morning, winter to summer and night to day. Additionally, the dimensionality reduction approach improves the computational processing speed of the recognition system.
Enabling a Pepper Robot to provide Automated and Interactive Tours of a Robotics Laboratory
Apr 10, 2018


The Pepper robot has become a widely recognised face for the perceived potential of social robots to enter our homes and businesses. However, to date, commercial and research applications of the Pepper have been largely restricted to roles in which the robot is able to remain stationary. This restriction is the result of a number of technical limitations, including limited sensing capabilities, and have as a result, reduced the number of roles in which use of the robot can be explored. In this paper, we present our approach to solving these problems, with the intention of opening up new research applications for the robot. To demonstrate the applicability of our approach, we have framed this work within the context of providing interactive tours of an open-plan robotics laboratory.
Rhythmic Representations: Learning Periodic Patterns for Scalable Place Recognition at a Sub-Linear Storage Cost
Dec 22, 2017

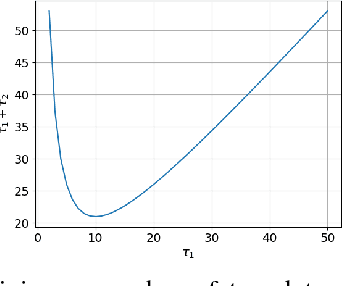
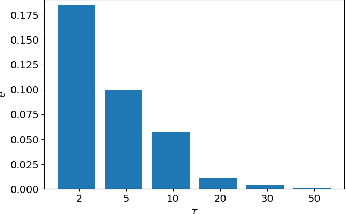
Robotic and animal mapping systems share many challenges and characteristics: they must function in a wide variety of environmental conditions, enable the robot or animal to navigate effectively to find food or shelter, and be computationally tractable from both a speed and storage perspective. With regards to map storage, the mammalian brain appears to take a diametrically opposed approach to all current robotic mapping systems. Where robotic mapping systems attempt to solve the data association problem to minimise representational aliasing, neurons in the brain intentionally break data association by encoding large (potentially unlimited) numbers of places with a single neuron. In this paper, we propose a novel method based on supervised learning techniques that seeks out regularly repeating visual patterns in the environment with mutually complementary co-prime frequencies, and an encoding scheme that enables storage requirements to grow sub-linearly with the size of the environment being mapped. To improve robustness in challenging real-world environments while maintaining storage growth sub-linearity, we incorporate both multi-exemplar learning and data augmentation techniques. Using large benchmark robotic mapping datasets, we demonstrate the combined system achieving high-performance place recognition with sub-linear storage requirements, and characterize the performance-storage growth trade-off curve. The work serves as the first robotic mapping system with sub-linear storage scaling properties, as well as the first large-scale demonstration in real-world environments of one of the proposed memory benefits of these neurons.
Look No Further: Adapting the Localization Sensory Window to the Temporal Characteristics of the Environment
Jul 24, 2017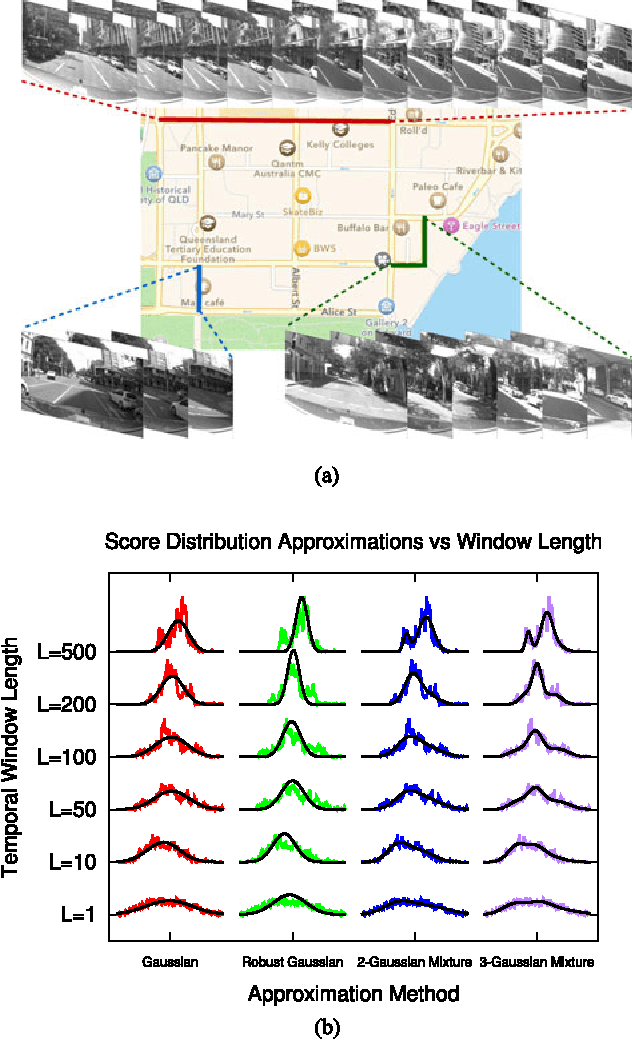
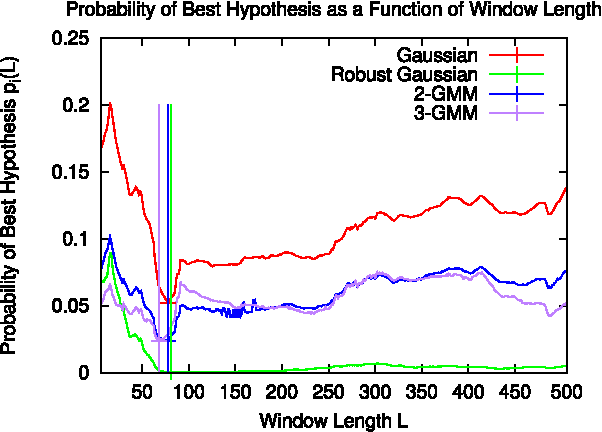
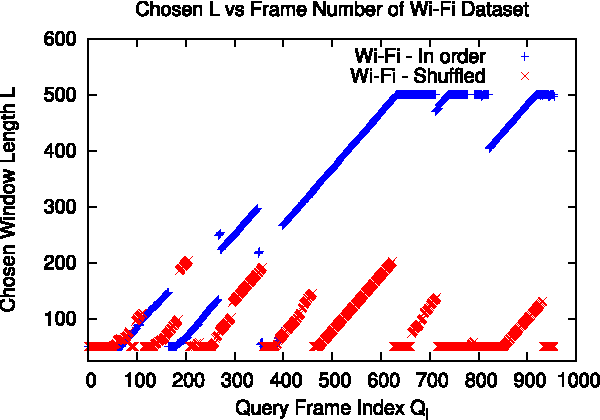
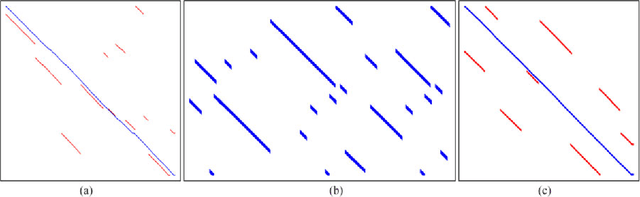
Many localization algorithms use a spatiotemporal window of sensory information in order to recognize spatial locations, and the length of this window is often a sensitive parameter that must be tuned to the specifics of the application. This letter presents a general method for environment-driven variation of the length of the spatiotemporal window based on searching for the most significant localization hypothesis, to use as much context as is appropriate but not more. We evaluate this approach on benchmark datasets using visual and Wi-Fi sensor modalities and a variety of sensory comparison front-ends under in-order and out-of-order traversals of the environment. Our results show that the system greatly reduces the maximum distance traveled without localization compared to a fixed-length approach while achieving competitive localization accuracy, and our proposed method achieves this performance without deployment-time tuning.
* Pre-print of article appearing in 2017 IEEE Robotics and Automation Letters. v2: incorporated reviewer feedback
Deja vu: Scalable Place Recognition Using Mutually Supportive Feature Frequencies
Jul 20, 2017
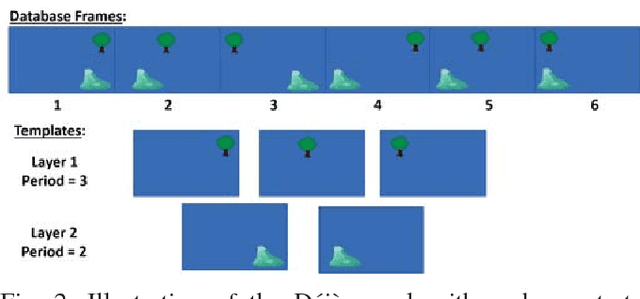
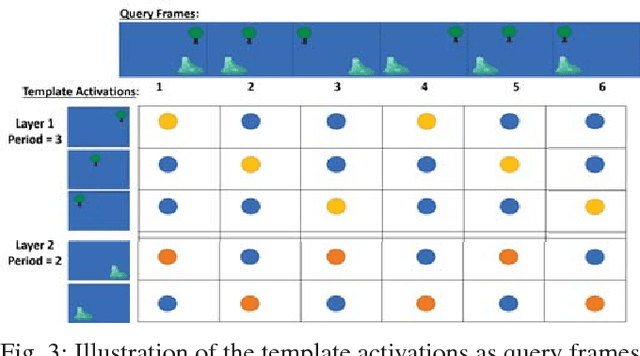
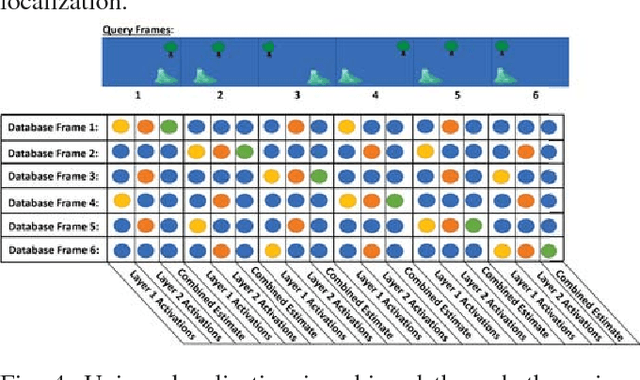
Learning and recognition is a fundamental process performed in many robot operations such as mapping and localization. The majority of approaches share some common characteristics, such as attempting to extract salient features, landmarks or signatures, and growth in data storage and computational requirements as the size of the environment increases. In biological systems, spatial encoding in the brain is definitively known to be performed using a fixed-size neural encoding framework - the place, head-direction and grid cells found in the mammalian hippocampus and entorhinal cortex. Particularly paradoxically, one of the main encoding centers - the grid cells - represents the world using a highly aliased, repetitive encoding structure where one neuron represents an unbounded number of places in the world. Inspired by this system, in this paper we invert the normal approach used in forming mapping and localization algorithms, by developing a novel place recognition algorithm that seeks out and leverages repetitive, mutually complementary landmark frequencies in the world. The combinatorial encoding capacity of multiple different frequencies enables not only the ability to achieve efficient data storage, but also the potential for sub-linear storage growth in a learning and recall system. Using both ground-based and aerial camera datasets, we demonstrate the system finding and utilizing these frequencies to achieve successful place recognition, and discuss how this approach might scale to arbitrarily large global datasets and dimensions.
Improving Condition- and Environment-Invariant Place Recognition with Semantic Place Categorization
Jun 22, 2017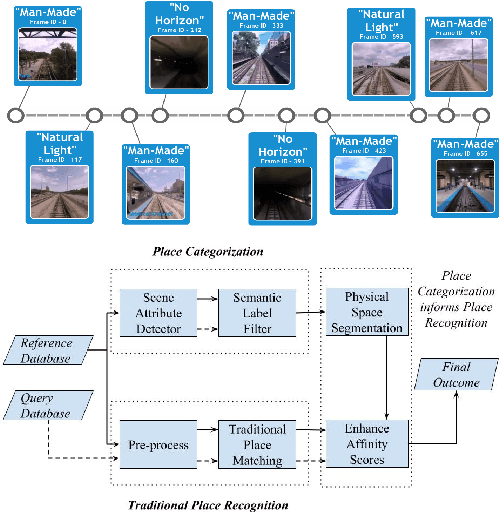

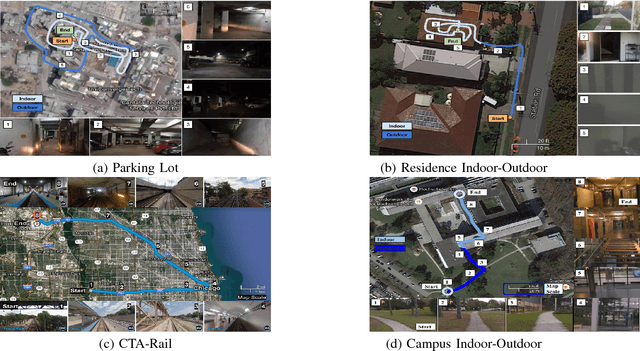

The place recognition problem comprises two distinct subproblems; recognizing a specific location in the world ("specific" or "ordinary" place recognition) and recognizing the type of place (place categorization). Both are important competencies for mobile robots and have each received significant attention in the robotics and computer vision community, but usually as separate areas of investigation. In this paper, we leverage the powerful complementary nature of place recognition and place categorization processes to create a new hybrid place recognition system that uses place context to inform place recognition. We show that semantic place categorization creates an informative natural segmenting of physical space that in turn enables significantly better place recognition performance in comparison to existing techniques. In particular, this new semantically informed approach adds robustness to significant local changes within the environment, such as transitioning between indoor and outdoor environments or between dark and light rooms in a house, complementing the capabilities of current condition-invariant techniques that are robust to globally consistent change (such as day to night cycles). We perform experiments using 4 benchmark and new datasets and show that semantically-informed place recognition outperforms the previous state-of-the-art systems. Like it does for object recognition [1], we believe that semantics can play a key role in boosting conventional place recognition and navigation performance for robotic systems.
Deep Learning Features at Scale for Visual Place Recognition
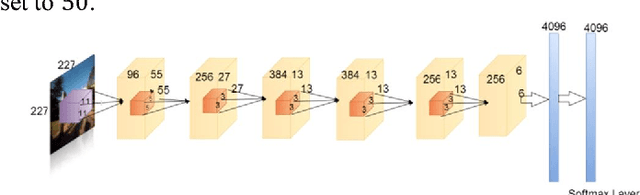
Jan 18, 2017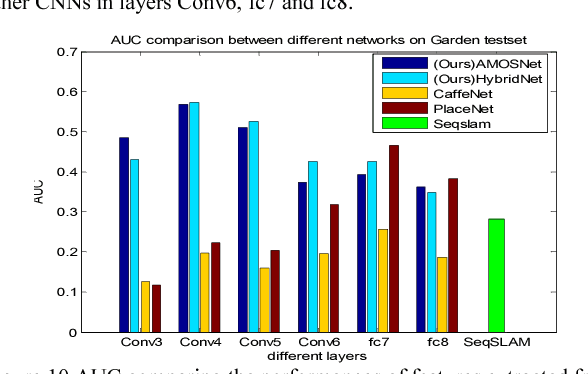


The success of deep learning techniques in the computer vision domain has triggered a range of initial investigations into their utility for visual place recognition, all using generic features from networks that were trained for other types of recognition tasks. In this paper, we train, at large scale, two CNN architectures for the specific place recognition task and employ a multi-scale feature encoding method to generate condition- and viewpoint-invariant features. To enable this training to occur, we have developed a massive Specific PlacEs Dataset (SPED) with hundreds of examples of place appearance change at thousands of different places, as opposed to the semantic place type datasets currently available. This new dataset enables us to set up a training regime that interprets place recognition as a classification problem. We comprehensively evaluate our trained networks on several challenging benchmark place recognition datasets and demonstrate that they achieve an average 10% increase in performance over other place recognition algorithms and pre-trained CNNs. By analyzing the network responses and their differences from pre-trained networks, we provide insights into what a network learns when training for place recognition, and what these results signify for future research in this area.