 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-guided Cross-view Diffusion for One-to-many Cross-view Image Synthesis
Dec 04, 2024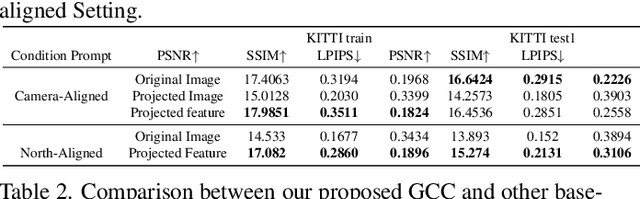
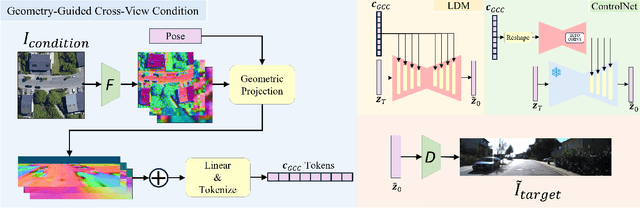
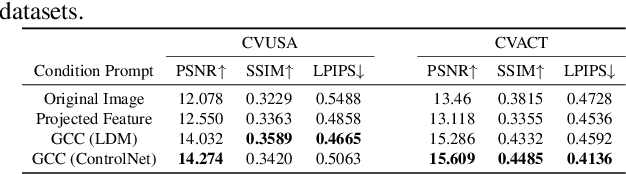
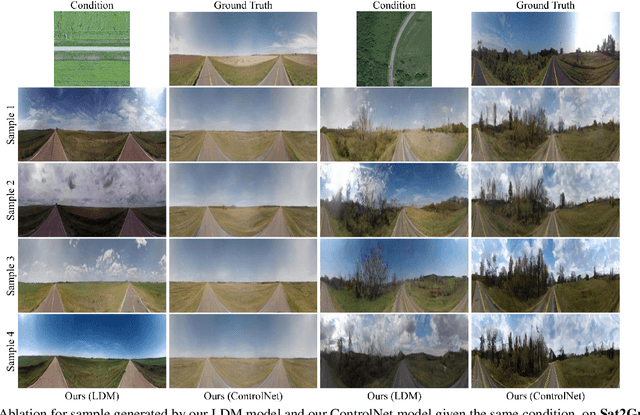
This paper presents a novel approach for cross-view synthesis aimed at generating plausible ground-level images from corresponding satellite imagery or vice versa. We refer to these tasks as satellite-to-ground (Sat2Grd) and ground-to-satellite (Grd2Sat) synthesis, respectively. Unlike previous works that typically focus on one-to-one generation, producing a single output image from a single input image, our approach acknowledges the inherent one-to-many nature of the problem. This recognition stems from the challenges posed by differences in illumination, weather conditions, and occlusions between the two views. To effectively model this uncertainty, we leverage recent advancements in diffusion models. Specifically, we exploit random Gaussian noise to represent the diverse possibilities learnt from the target view data. We introduce a Geometry-guided Cross-view Condition (GCC) strategy to establish explicit geometric correspondences between satellite and street-view features. This enables us to resolve the geometry ambiguity introduced by camera pose between image pairs, boosting the performance of cross-view image synthesis. Through extensive quantitative and qualitative analyses on three benchmark cross-view datasets, we demonstrate the superiority of our proposed geometry-guided cross-view condition over baseline methods, including recent state-of-the-art approaches in cross-view image synthesis. Our method generates images of higher quality, fidelity, and diversity than other state-of-the-art approaches.
Weakly-supervised Camera Localization by Ground-to-satellite Image Registration
Sep 10, 2024
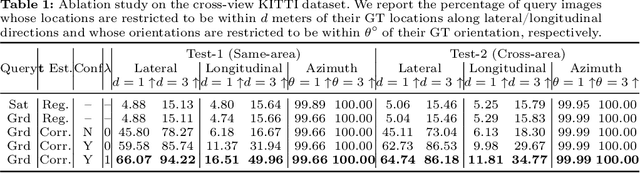
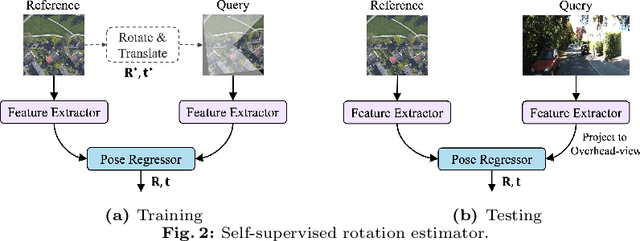

The ground-to-satellite image matching/retrieval was initially proposed for city-scale ground camera localization. This work addresses the problem of improving camera pose accuracy by ground-to-satellite image matching after a coarse location and orientation have been obtained, either from the city-scale retrieval or from consumer-level GPS and compass sensors. Existing learning-based methods for solving this task require accurate GPS labels of ground images for network training. However, obtaining such accurate GPS labels is difficult, often requiring an expensive {\color{black}Real Time Kinematics (RTK)} setup and suffering from signal occlusion, multi-path signal disruptions, \etc. To alleviate this issue, this paper proposes a weakly supervised learning strategy for ground-to-satellite image registration when only noisy pose labels for ground images are available for network training. It derives positive and negative satellite images for each ground image and leverages contrastive learning to learn feature representations for ground and satellite images useful for translation estimation. We also propose a self-supervision strategy for cross-view image relative rotation estimation, which trains the network by creating pseudo query and reference image pairs. Experimental results show that our weakly supervised learning strategy achieves the best performance on cross-area evaluation compared to recent state-of-the-art methods that are reliant on accurate pose labels for supervision.
Dynamically Modulating Visual Place Recognition Sequence Length For Minimum Acceptable Performance Scenarios
Jul 01, 2024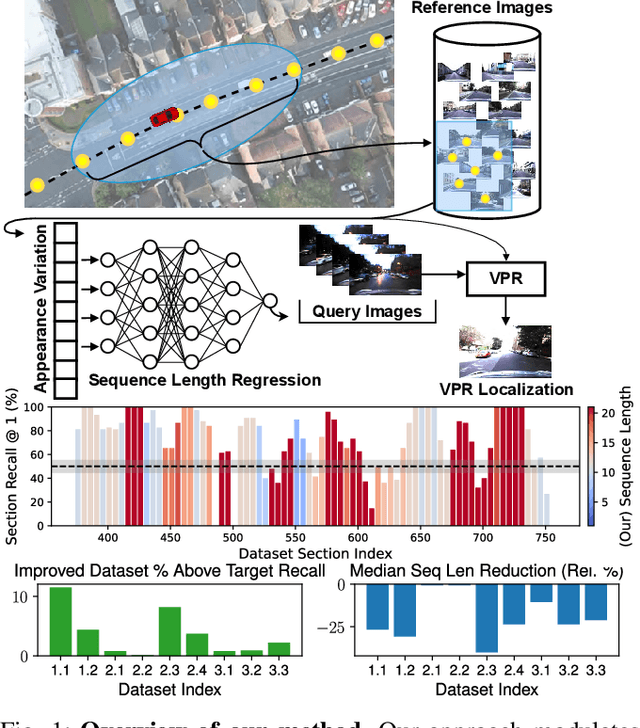
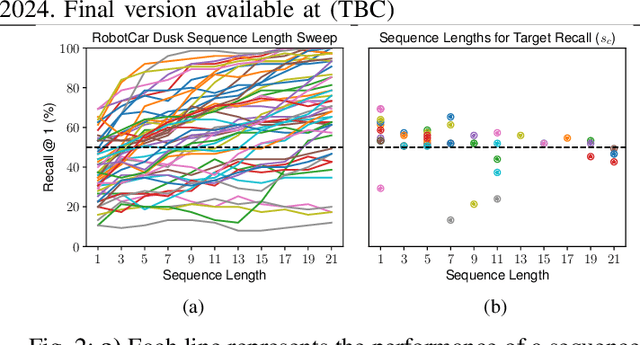

Mobile robots and autonomous vehicles are often required to function in environments where critical position estimates from sensors such as GPS become uncertain or unreliable. Single image visual place recognition (VPR) provides an alternative for localization but often requires techniques such as sequence matching to improve robustness, which incurs additional computation and latency costs. Even then, the sequence length required to localize at an acceptable performance level varies widely; and simply setting overly long fixed sequence lengths creates unnecessary latency, computational overhead, and can even degrade performance. In these scenarios it is often more desirable to meet or exceed a set target performance at minimal expense. In this paper we present an approach which uses a calibration set of data to fit a model that modulates sequence length for VPR as needed to exceed a target localization performance. We make use of a coarse position prior, which could be provided by any other localization system, and capture the variation in appearance across this region. We use the correlation between appearance variation and sequence length to curate VPR features and fit a multilayer perceptron (MLP) for selecting the optimal length. We demonstrate that this method is effective at modulating sequence length to maximize the number of sections in a dataset which meet or exceed a target performance whilst minimizing the median length used. We show applicability across several datasets and reveal key phenomena like generalization capabilities, the benefits of curating features and the utility of non-state-of-the-art feature extractors with nuanced properties.
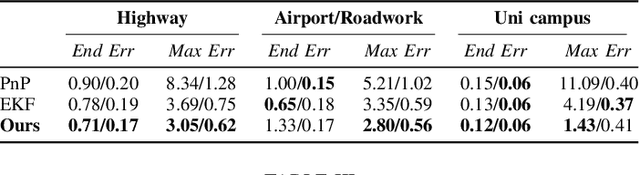
Increasing SLAM Pose Accuracy by Ground-to-Satellite Image Registration
Apr 14, 2024Vision-based localization for autonomous driving has been of great interest among researchers. When a pre-built 3D map is not available, the techniques of visual simultaneous localization and mapping (SLAM) are typically adopted. Due to error accumulation, visual SLAM (vSLAM) usually suffers from long-term drift. This paper proposes a framework to increase the localization accuracy by fusing the vSLAM with a deep-learning-based ground-to-satellite (G2S) image registration method. In this framework, a coarse (spatial correlation bound check) to fine (visual odometry consistency check) method is designed to select the valid G2S prediction. The selected prediction is then fused with the SLAM measurement by solving a scaled pose graph problem. To further increase the localization accuracy, we provide an iterative trajectory fusion pipeline. The proposed framework is evaluated on two well-known autonomous driving datasets, and the results demonstrate the accuracy and robustness in terms of vehicle localization.
A Detection and Filtering Framework for Collaborative Localization
Mar 08, 2024



Increasingly, autonomous vehicles (AVs) are becoming a reality, such as the Advanced Driver Assistance Systems (ADAS) in vehicles that assist drivers in driving and parking functions with vehicles today. The localization problem for AVs relies primarily on multiple sensors, including cameras, LiDARs, and radars. Manufacturing, installing, calibrating, and maintaining these sensors can be very expensive, thereby increasing the overall cost of AVs. This research explores the means to improve localization on vehicles belonging to the ADAS category in a platooning context, where an ADAS vehicle follows a lead "Smart" AV equipped with a highly accurate sensor suite. We propose and produce results by using a filtering framework to combine pose information derived from vision and odometry to improve the localization of the ADAS vehicle that follows the smart vehicle.
View Consistent Purification for Accurate Cross-View Localization
Aug 16, 2023

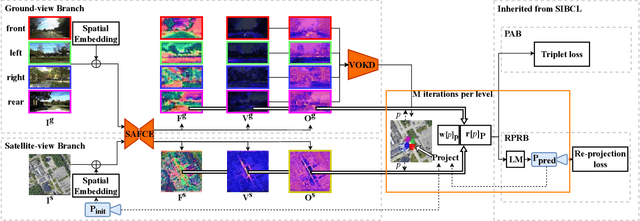

This paper proposes a fine-grained self-localization method for outdoor robotics that utilizes a flexible number of onboard cameras and readily accessible satellite images. The proposed method addresses limitations in existing cross-view localization methods that struggle to handle noise sources such as moving objects and seasonal variations. It is the first sparse visual-only method that enhances perception in dynamic environments by detecting view-consistent key points and their corresponding deep features from ground and satellite views, while removing off-the-ground objects and establishing homography transformation between the two views. Moreover, the proposed method incorporates a spatial embedding approach that leverages camera intrinsic and extrinsic information to reduce the ambiguity of purely visual matching, leading to improved feature matching and overall pose estimation accuracy. The method exhibits strong generalization and is robust to environmental changes, requiring only geo-poses as ground truth. Extensive experiments on the KITTI and Ford Multi-AV Seasonal datasets demonstrate that our proposed method outperforms existing state-of-the-art methods, achieving median spatial accuracy errors below $0.5$ meters along the lateral and longitudinal directions, and a median orientation accuracy error below 2 degrees.
Stereo Visual Odometry with Deep Learning-Based Point and Line Feature Matching using an Attention Graph Neural Network
Aug 02, 2023



Robust feature matching forms the backbone for most Visual Simultaneous Localization and Mapping (vSLAM), visual odometry, 3D reconstruction, and Structure from Motion (SfM) algorithms. However, recovering feature matches from texture-poor scenes is a major challenge and still remains an open area of research. In this paper, we present a Stereo Visual Odometry (StereoVO) technique based on point and line features which uses a novel feature-matching mechanism based on an Attention Graph Neural Network that is designed to perform well even under adverse weather conditions such as fog, haze, rain, and snow, and dynamic lighting conditions such as nighttime illumination and glare scenarios. We perform experiments on multiple real and synthetic datasets to validate the ability of our method to perform StereoVO under low visibility weather and lighting conditions through robust point and line matches. The results demonstrate that our method achieves more line feature matches than state-of-the-art line matching algorithms, which when complemented with point feature matches perform consistently well in adverse weather and dynamic lighting conditions.
Boosting 3-DoF Ground-to-Satellite Camera Localization Accuracy via Geometry-Guided Cross-View Transformer
Jul 20, 2023



Image retrieval-based cross-view localization methods often lead to very coarse camera pose estimation, due to the limited sampling density of the database satellite images. In this paper, we propose a method to increase the accuracy of a ground camera's location and orientation by estimating the relative rotation and translation between the ground-level image and its matched/retrieved satellite image. Our approach designs a geometry-guided cross-view transformer that combines the benefits of conventional geometry and learnable cross-view transformers to map the ground-view observations to an overhead view. Given the synthesized overhead view and observed satellite feature maps, we construct a neural pose optimizer with strong global information embedding ability to estimate the relative rotation between them. After aligning their rotations, we develop an uncertainty-guided spatial correlation to generate a probability map of the vehicle locations, from which the relative translation can be determined. Experimental results demonstrate that our method significantly outperforms the state-of-the-art. Notably, the likelihood of restricting the vehicle lateral pose to be within 1m of its Ground Truth (GT) value on the cross-view KITTI dataset has been improved from $35.54\%$ to $76.44\%$, and the likelihood of restricting the vehicle orientation to be within $1^{\circ}$ of its GT value has been improved from $19.64\%$ to $99.10\%$.
Locking On: Leveraging Dynamic Vehicle-Imposed Motion Constraints to Improve Visual Localization
Jun 30, 2023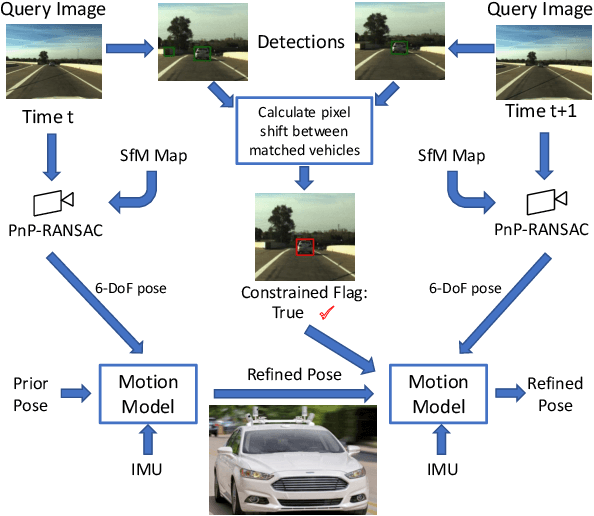
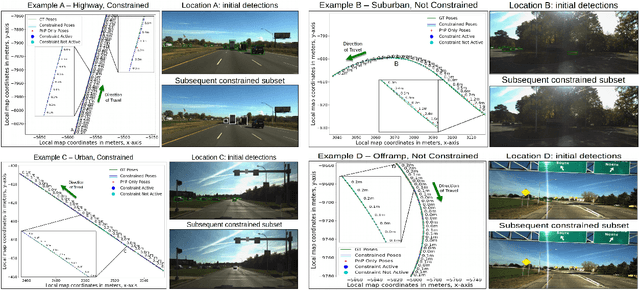

Most 6-DoF localization and SLAM systems use static landmarks but ignore dynamic objects because they cannot be usefully incorporated into a typical pipeline. Where dynamic objects have been incorporated, typical approaches have attempted relatively sophisticated identification and localization of these objects, limiting their robustness or general utility. In this research, we propose a middle ground, demonstrated in the context of autonomous vehicles, using dynamic vehicles to provide limited pose constraint information in a 6-DoF frame-by-frame PnP-RANSAC localization pipeline. We refine initial pose estimates with a motion model and propose a method for calculating the predicted quality of future pose estimates, triggered based on whether or not the autonomous vehicle's motion is constrained by the relative frame-to-frame location of dynamic vehicles in the environment. Our approach detects and identifies suitable dynamic vehicles to define these pose constraints to modify a pose filter, resulting in improved recall across a range of localization tolerances from $0.25m$ to $5m$, compared to a state-of-the-art baseline single image PnP method and its vanilla pose filtering. Our constraint detection system is active for approximately $35\%$ of the time on the Ford AV dataset and localization is particularly improved when the constraint detection is active.
DisPlacing Objects: Improving Dynamic Vehicle Detection via Visual Place Recognition under Adverse Conditions
Jun 30, 2023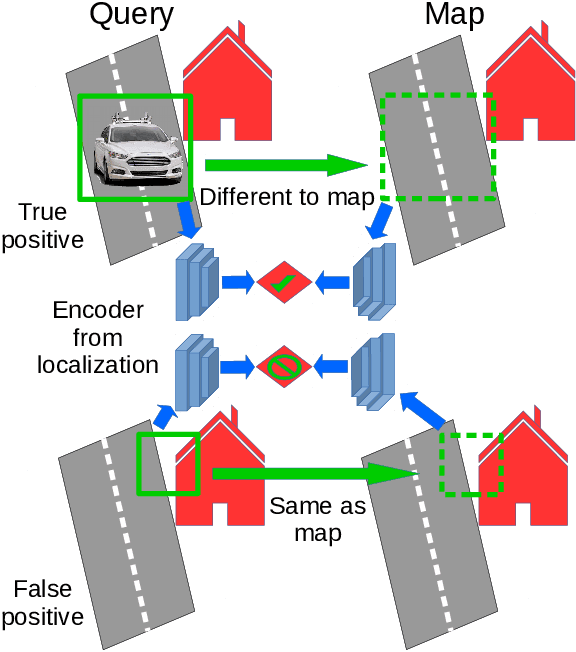
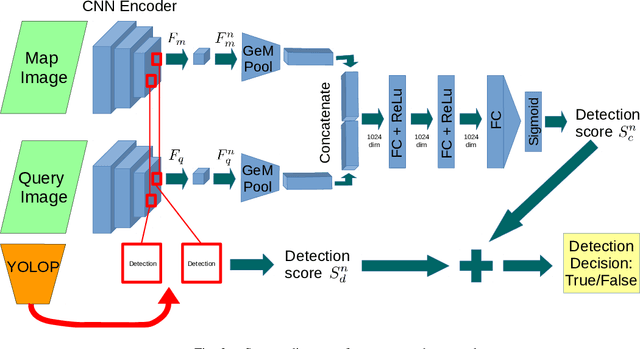
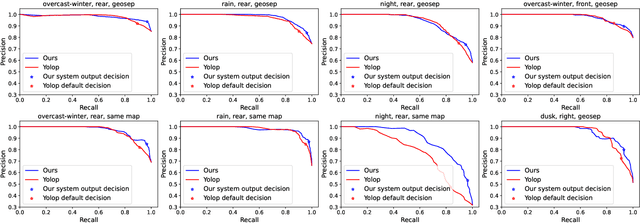

Can knowing where you are assist in perceiving objects in your surroundings, especially under adverse weather and lighting conditions? In this work we investigate whether a prior map can be leveraged to aid in the detection of dynamic objects in a scene without the need for a 3D map or pixel-level map-query correspondences. We contribute an algorithm which refines an initial set of candidate object detections and produces a refined subset of highly accurate detections using a prior map. We begin by using visual place recognition (VPR) to retrieve a reference map image for a given query image, then use a binary classification neural network that compares the query and mapping image regions to validate the query detection. Once our classification network is trained, on approximately 1000 query-map image pairs, it is able to improve the performance of vehicle detection when combined with an existing off-the-shelf vehicle detector. We demonstrate our approach using standard datasets across two cities (Oxford and Zurich) under different settings of train-test separation of map-query traverse pairs. We further emphasize the performance gains of our approach against alternative design choices and show that VPR suffices for the task, eliminating the need for precise ground truth localization.