 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Detection and Filtering Framework for Collaborative Localization
Mar 08, 2024



Increasingly, autonomous vehicles (AVs) are becoming a reality, such as the Advanced Driver Assistance Systems (ADAS) in vehicles that assist drivers in driving and parking functions with vehicles today. The localization problem for AVs relies primarily on multiple sensors, including cameras, LiDARs, and radars. Manufacturing, installing, calibrating, and maintaining these sensors can be very expensive, thereby increasing the overall cost of AVs. This research explores the means to improve localization on vehicles belonging to the ADAS category in a platooning context, where an ADAS vehicle follows a lead "Smart" AV equipped with a highly accurate sensor suite. We propose and produce results by using a filtering framework to combine pose information derived from vision and odometry to improve the localization of the ADAS vehicle that follows the smart vehicle.
Humans are still the best lossy image compressors
Oct 29, 2018
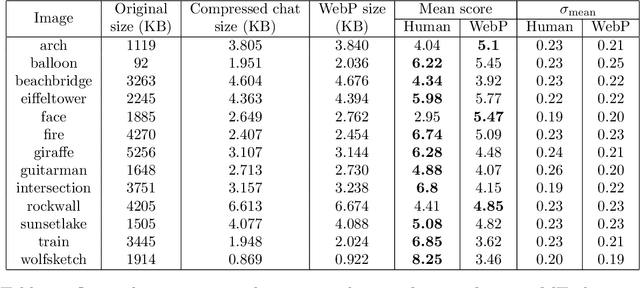
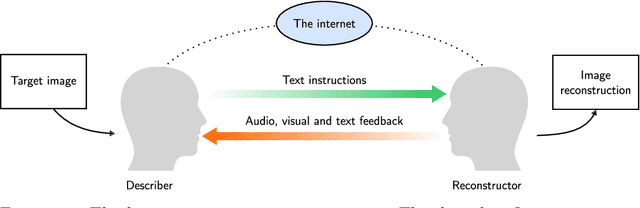
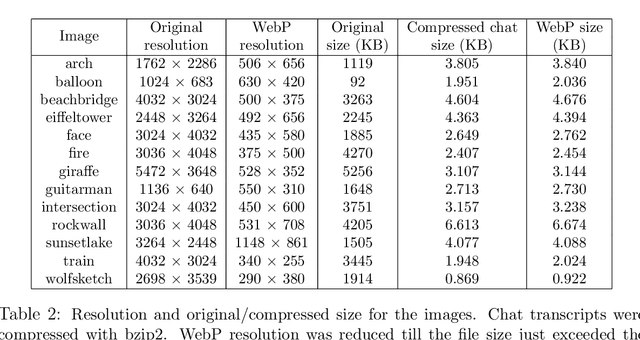
Lossy image compression has been studied extensively in the context of typical loss functions such as RMSE, MS-SSIM, etc. However, it is not well understood what loss function might be most appropriate for human perception. Furthermore, the availability of massive public image datasets appears to have hardly been exploited in image compression. In this work, we perform compression experiments in which one human describes images to another, using publicly available images and text instructions. These image reconstructions are rated by human scorers on the Amazon Mechanical Turk platform and compared to reconstructions obtained by existing image compressors. In our experiments, the humans outperform the state of the art compressor WebP in the MTurk survey on most images, which shows that there is significant room for improvement in image compression for human perception. The images, results and additional data is available at https://compression.stanford.edu/human-compression.