 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering Federated Learning for Massive Models with NVIDIA FLARE
Feb 12, 2024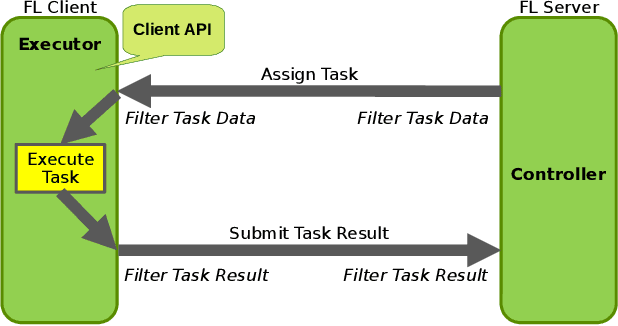

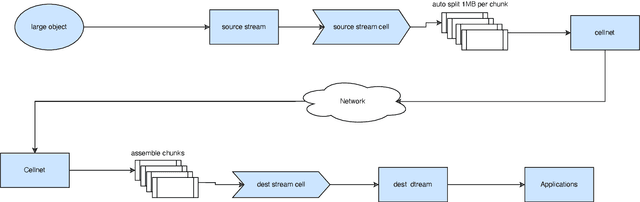
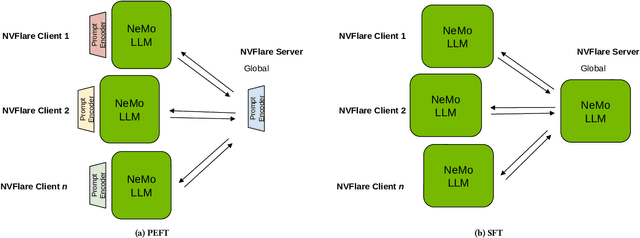
In the ever-evolving landscape of artificial intelligence (AI) and large language models (LLMs), handling and leveraging data effectively has become a critical challenge. Most state-of-the-art machine learning algorithms are data-centric. However, as the lifeblood of model performance, necessary data cannot always be centralized due to various factors such as privacy, regulation, geopolitics, copyright issues, and the sheer effort required to move vast datasets. In this paper, we explore how federated learning enabled by NVIDIA FLARE can address these challenges with easy and scalable integration capabilities, enabling parameter-efficient and full supervised fine-tuning of LLMs for natural language processing and biopharmaceutical applications to enhance their accuracy and robustness.
NVIDIA FLARE: Federated Learning from Simulation to Real-World
Oct 24, 2022



Federated learning (FL) enables building robust and generalizable AI models by leveraging diverse datasets from multiple collaborators without centralizing the data. We created NVIDIA FLARE as an open-source software development kit (SDK) to make it easier for data scientists to use FL in their research and real-world applications. The SDK includes solutions for state-of-the-art FL algorithms and federated machine learning approaches, which facilitate building workflows for distributed learning across enterprises and enable platform developers to create a secure, privacy-preserving offering for multiparty collaboration utilizing homomorphic encryption or differential privacy. The SDK is a lightweight, flexible, and scalable Python package, and allows researchers to bring their data science workflows implemented in any training libraries (PyTorch, TensorFlow, XGBoost, or even NumPy) and apply them in real-world FL settings. This paper introduces the key design principles of FLARE and illustrates some use cases (e.g., COVID analysis) with customizable FL workflows that implement different privacy-preserving algorithms. Code is available at https://github.com/NVIDIA/NVFlare.
Delineating Knowledge Domains in the Scientific Literature Using Visual Information
Aug 12, 2019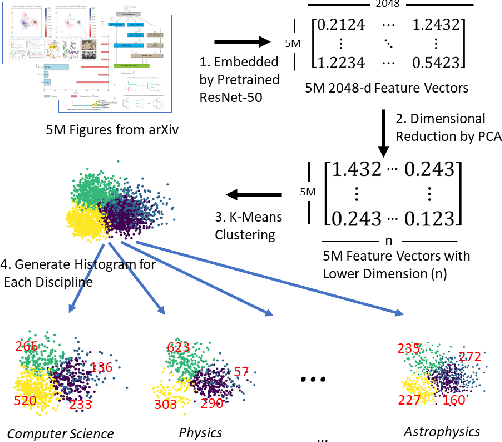
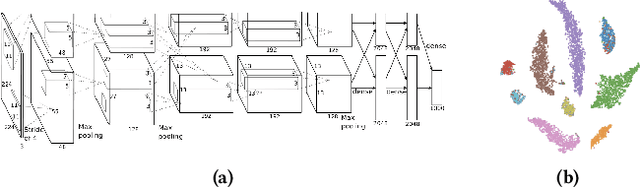
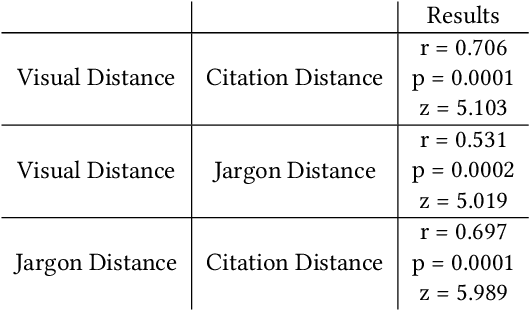
Figures are an important channel for scientific communication, used to express complex ideas, models and data in ways that words cannot. However, this visual information is mostly ignored in analyses of the scientific literature. In this paper, we demonstrate the utility of using scientific figures as markers of knowledge domains in science, which can be used for classification, recommender systems, and studies of scientific information exchange. We encode sets of images into a visual signature, then use distances between these signatures to understand how patterns of visual communication compare with patterns of jargon and citation structures. We find that figures can be as effective for differentiating communities of practice as text or citation patterns. We then consider where these metrics disagree to understand how different disciplines use visualization to express ideas. Finally, we further consider how specific figure types propagate through the literature, suggesting a new mechanism for understanding the flow of ideas apart from conventional channels of text and citations. Our ultimate aim is to better leverage these information-dense objects to improve scientific communication across disciplinary boundaries.
MultiDEC: Multi-Modal Clustering of Image-Caption Pairs
Jan 04, 2019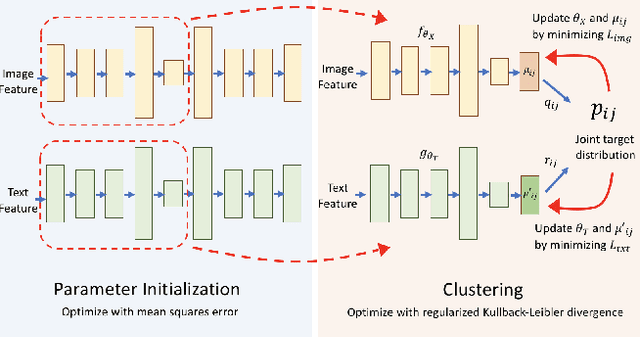

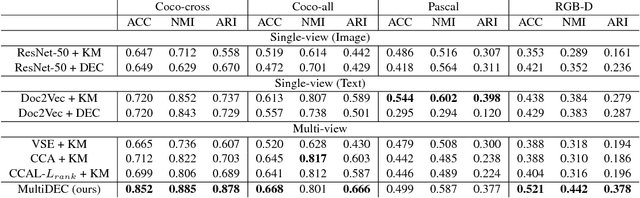
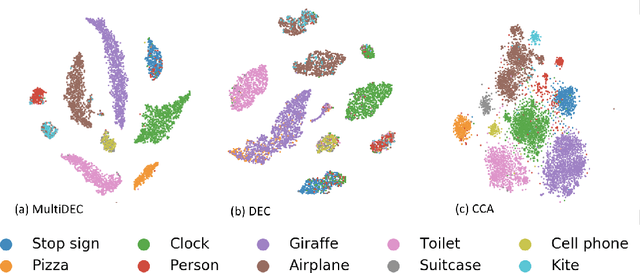
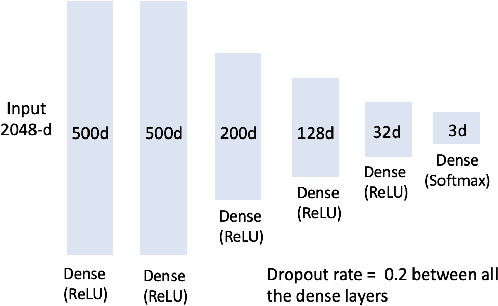
In this paper, we propose a method for clustering image-caption pairs by simultaneously learning image representations and text representations that are constrained to exhibit similar distributions. These image-caption pairs arise frequently in high-value applications where structured training data is expensive to produce but free-text descriptions are common. MultiDEC initializes parameters with stacked autoencoders, then iteratively minimizes the Kullback-Leibler divergence between the distribution of the images (and text) to that of a combined joint target distribution. We regularize by penalizing non-uniform distributions across clusters. The representations that minimize this objective produce clusters that outperform both single-view and multi-view techniques on large benchmark image-caption datasets.
Humans are still the best lossy image compressors
Oct 29, 2018
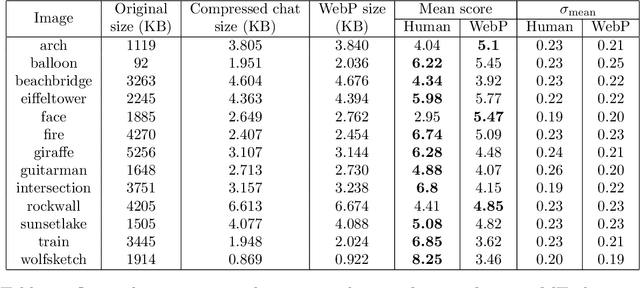
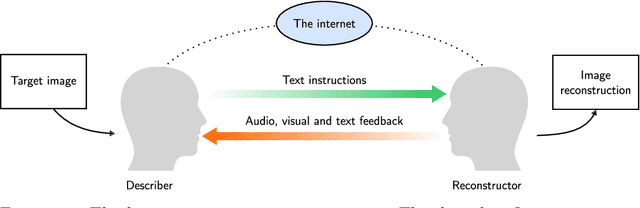
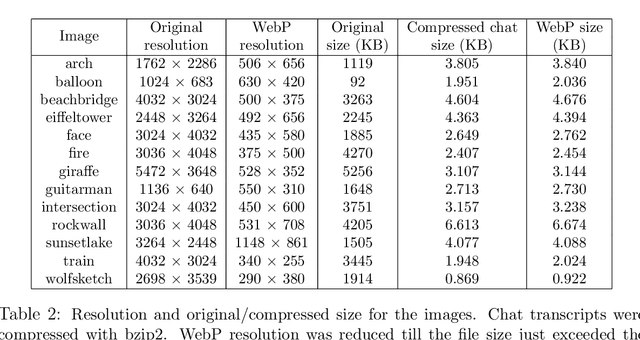
Lossy image compression has been studied extensively in the context of typical loss functions such as RMSE, MS-SSIM, etc. However, it is not well understood what loss function might be most appropriate for human perception. Furthermore, the availability of massive public image datasets appears to have hardly been exploited in image compression. In this work, we perform compression experiments in which one human describes images to another, using publicly available images and text instructions. These image reconstructions are rated by human scorers on the Amazon Mechanical Turk platform and compared to reconstructions obtained by existing image compressors. In our experiments, the humans outperform the state of the art compressor WebP in the MTurk survey on most images, which shows that there is significant room for improvement in image compression for human perception. The images, results and additional data is available at https://compression.stanford.edu/human-compression.