 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiDEC: Multi-Modal Clustering of Image-Caption Pairs
Paper and Code
Jan 04, 2019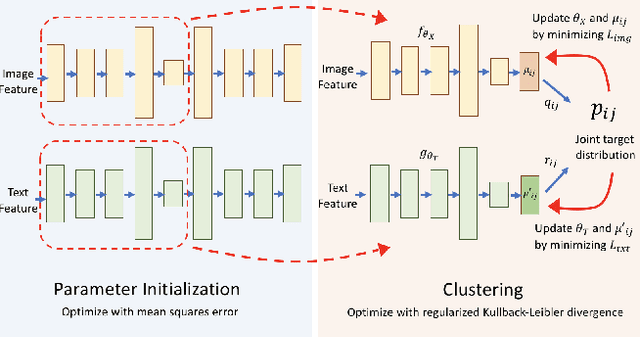

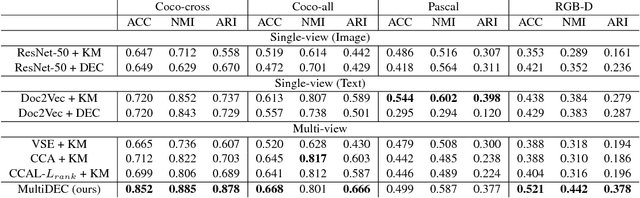
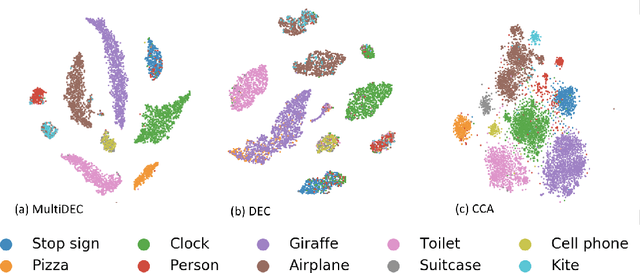
In this paper, we propose a method for clustering image-caption pairs by simultaneously learning image representations and text representations that are constrained to exhibit similar distributions. These image-caption pairs arise frequently in high-value applications where structured training data is expensive to produce but free-text descriptions are common. MultiDEC initializes parameters with stacked autoencoders, then iteratively minimizes the Kullback-Leibler divergence between the distribution of the images (and text) to that of a combined joint target distribution. We regularize by penalizing non-uniform distributions across clusters. The representations that minimize this objective produce clusters that outperform both single-view and multi-view techniques on large benchmark image-caption datasets.