 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCityGo: Lightweight Urban Modeling and Rendering with Proxy Buildings and Residual Gaussians
May 28, 2025



Accurate and efficient modeling of large-scale urban scenes is critical for applications such as AR navigation, UAV based inspection, and smart city digital twins. While aerial imagery offers broad coverage and complements limitations of ground-based data, reconstructing city-scale environments from such views remains challenging due to occlusions, incomplete geometry, and high memory demands. Recent advances like 3D Gaussian Splatting (3DGS) improve scalability and visual quality but remain limited by dense primitive usage, long training times, and poor suit ability for edge devices. We propose CityGo, a hybrid framework that combines textured proxy geometry with residual and surrounding 3D Gaussians for lightweight, photorealistic rendering of urban scenes from aerial perspectives. Our approach first extracts compact building proxy meshes from MVS point clouds, then uses zero order SH Gaussians to generate occlusion-free textures via image-based rendering and back-projection. To capture high-frequency details, we introduce residual Gaussians placed based on proxy-photo discrepancies and guided by depth priors. Broader urban context is represented by surrounding Gaussians, with importance-aware downsampling applied to non-critical regions to reduce redundancy. A tailored optimization strategy jointly refines proxy textures and Gaussian parameters, enabling real-time rendering of complex urban scenes on mobile GPUs with significantly reduced training and memory requirements. Extensive experiments on real-world aerial datasets demonstrate that our hybrid representation significantly reduces training time, achieving on average 1.4x speedup, while delivering comparable visual fidelity to pure 3D Gaussian Splatting approaches. Furthermore, CityGo enables real-time rendering of large-scale urban scenes on mobile consumer GPUs, with substantially reduced memory usage and energy consumption.
DynOPETs: A Versatile Benchmark for Dynamic Object Pose Estimation and Tracking in Moving Camera Scenarios
Mar 25, 2025In the realm of object pose estimation, scenarios involving both dynamic objects and moving cameras are prevalent. However, the scarcity of corresponding real-world datasets significantly hinders the development and evaluation of robust pose estimation models. This is largely attributed to the inherent challenges in accurately annotating object poses in dynamic scenes captured by moving cameras. To bridge this gap, this paper presents a novel dataset DynOPETs and a dedicated data acquisition and annotation pipeline tailored for object pose estimation and tracking in such unconstrained environments. Our efficient annotation method innovatively integrates pose estimation and pose tracking techniques to generate pseudo-labels, which are subsequently refined through pose graph optimization. The resulting dataset offers accurate pose annotations for dynamic objects observed from moving cameras. To validate the effectiveness and value of our dataset, we perform comprehensive evaluations using 18 state-of-the-art methods, demonstrating its potential to accelerate research in this challenging domain. The dataset will be made publicly available to facilitate further exploration and advancement in the field.
BevSplat: Resolving Height Ambiguity via Feature-Based Gaussian Primitives for Weakly-Supervised Cross-View Localization
Feb 13, 2025
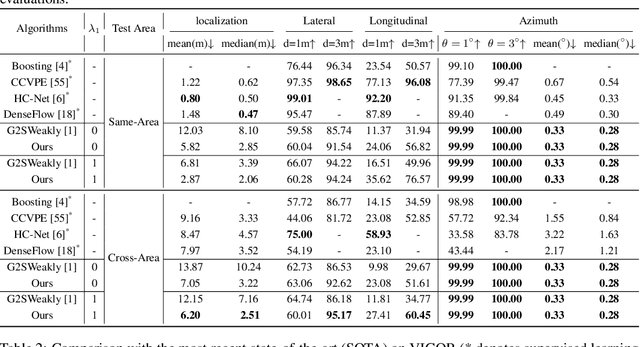
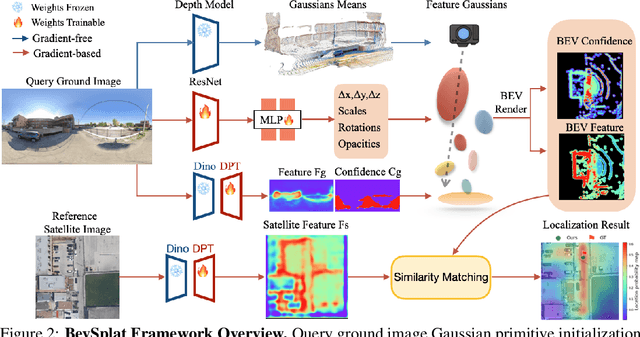
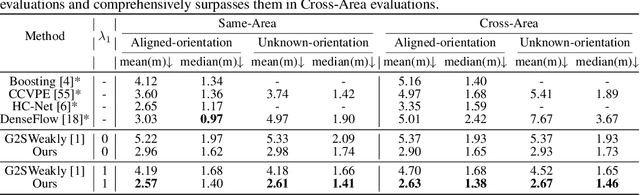
This paper addresses the problem of weakly supervised cross-view localization, where the goal is to estimate the pose of a ground camera relative to a satellite image with noisy ground truth annotations. A common approach to bridge the cross-view domain gap for pose estimation is Bird's-Eye View (BEV) synthesis. However, existing methods struggle with height ambiguity due to the lack of depth information in ground images and satellite height maps. Previous solutions either assume a flat ground plane or rely on complex models, such as cross-view transformers. We propose BevSplat, a novel method that resolves height ambiguity by using feature-based Gaussian primitives. Each pixel in the ground image is represented by a 3D Gaussian with semantic and spatial features, which are synthesized into a BEV feature map for relative pose estimation. Additionally, to address challenges with panoramic query images, we introduce an icosphere-based supervision strategy for the Gaussian primitives. We validate our method on the widely used KITTI and VIGOR datasets, which include both pinhole and panoramic query images. Experimental results show that BevSplat significantly improves localization accuracy over prior approaches.
Controllable Satellite-to-Street-View Synthesis with Precise Pose Alignment and Zero-Shot Environmental Control
Feb 05, 2025
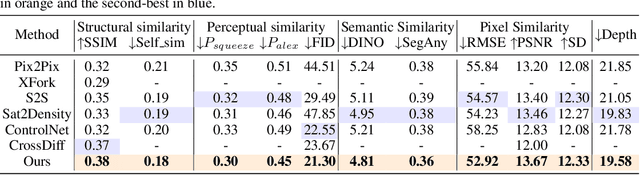
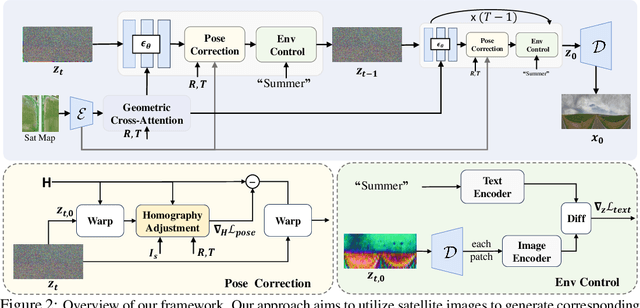
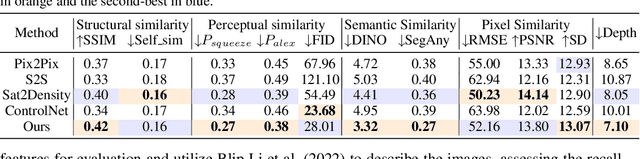
Generating street-view images from satellite imagery is a challenging task, particularly in maintaining accurate pose alignment and incorporating diverse environmental conditions. While diffusion models have shown promise in generative tasks, their ability to maintain strict pose alignment throughout the diffusion process is limited. In this paper, we propose a novel Iterative Homography Adjustment (IHA) scheme applied during the denoising process, which effectively addresses pose misalignment and ensures spatial consistency in the generated street-view images. Additionally, currently, available datasets for satellite-to-street-view generation are limited in their diversity of illumination and weather conditions, thereby restricting the generalizability of the generated outputs. To mitigate this, we introduce a text-guided illumination and weather-controlled sampling strategy that enables fine-grained control over the environmental factors. Extensive quantitative and qualitative evaluations demonstrate that our approach significantly improves pose accuracy and enhances the diversity and realism of generated street-view images, setting a new benchmark for satellite-to-street-view generation tasks.
CADSpotting: Robust Panoptic Symbol Spotting on Large-Scale CAD Drawings
Dec 10, 2024We introduce CADSpotting, an efficient method for panoptic symbol spotting in large-scale architectural CAD drawings. Existing approaches struggle with the diversity of symbols, scale variations, and overlapping elements in CAD designs. CADSpotting overcomes these challenges by representing each primitive with dense points instead of a single primitive point, described by essential attributes like coordinates and color. Building upon a unified 3D point cloud model for joint semantic, instance, and panoptic segmentation, CADSpotting learns robust feature representations. To enable accurate segmentation in large, complex drawings, we further propose a novel Sliding Window Aggregation (SWA) technique, combining weighted voting and Non-Maximum Suppression (NMS). Moreover, we introduce a large-scale CAD dataset named LS-CAD to support our experiments. Each floorplan in LS-CAD has an average coverage of 1,000 square meter(versus 100 square meter in the existing dataset), providing a valuable benchmark for symbol spotting research. Experimental results on FloorPlanCAD and LS-CAD datasets demonstrate that CADSpotting outperforms existing methods, showcasing its robustness and scalability for real-world CAD applications.
Geometry-guided Cross-view Diffusion for One-to-many Cross-view Image Synthesis
Dec 04, 2024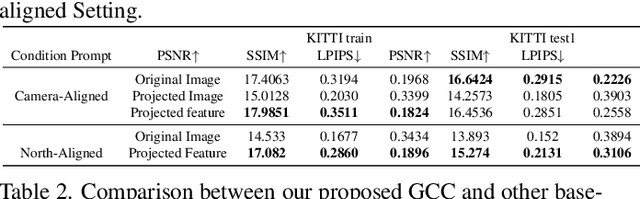
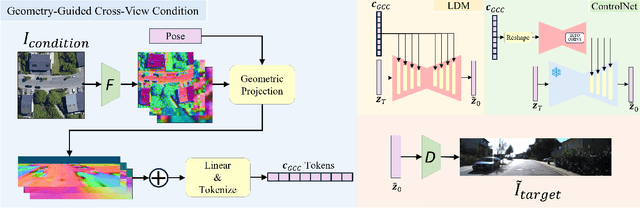
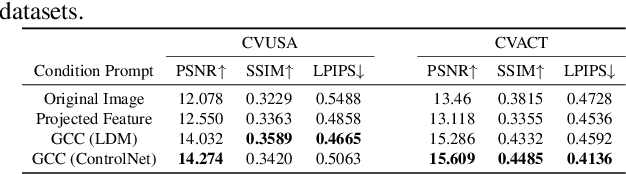
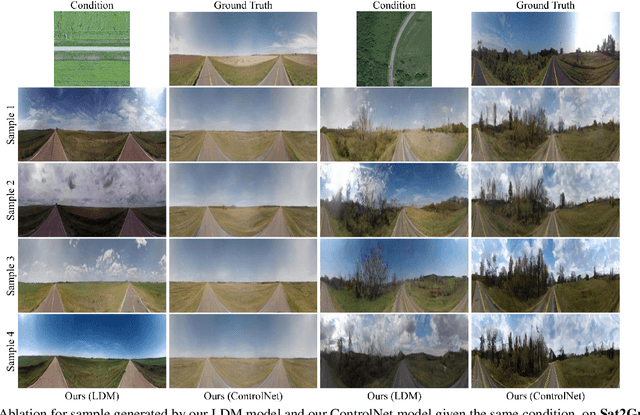
This paper presents a novel approach for cross-view synthesis aimed at generating plausible ground-level images from corresponding satellite imagery or vice versa. We refer to these tasks as satellite-to-ground (Sat2Grd) and ground-to-satellite (Grd2Sat) synthesis, respectively. Unlike previous works that typically focus on one-to-one generation, producing a single output image from a single input image, our approach acknowledges the inherent one-to-many nature of the problem. This recognition stems from the challenges posed by differences in illumination, weather conditions, and occlusions between the two views. To effectively model this uncertainty, we leverage recent advancements in diffusion models. Specifically, we exploit random Gaussian noise to represent the diverse possibilities learnt from the target view data. We introduce a Geometry-guided Cross-view Condition (GCC) strategy to establish explicit geometric correspondences between satellite and street-view features. This enables us to resolve the geometry ambiguity introduced by camera pose between image pairs, boosting the performance of cross-view image synthesis. Through extensive quantitative and qualitative analyses on three benchmark cross-view datasets, we demonstrate the superiority of our proposed geometry-guided cross-view condition over baseline methods, including recent state-of-the-art approaches in cross-view image synthesis. Our method generates images of higher quality, fidelity, and diversity than other state-of-the-art approaches.
AerialGo: Walking-through City View Generation from Aerial Perspectives
Nov 29, 2024



High-quality 3D urban reconstruction is essential for applications in urban planning, navigation, and AR/VR. However, capturing detailed ground-level data across cities is both labor-intensive and raises significant privacy concerns related to sensitive information, such as vehicle plates, faces, and other personal identifiers. To address these challenges, we propose AerialGo, a novel framework that generates realistic walking-through city views from aerial images, leveraging multi-view diffusion models to achieve scalable, photorealistic urban reconstructions without direct ground-level data collection. By conditioning ground-view synthesis on accessible aerial data, AerialGo bypasses the privacy risks inherent in ground-level imagery. To support the model training, we introduce AerialGo dataset, a large-scale dataset containing diverse aerial and ground-view images, paired with camera and depth information, designed to support generative urban reconstruction. Experiments show that AerialGo significantly enhances ground-level realism and structural coherence, providing a privacy-conscious, scalable solution for city-scale 3D modeling.
FastGrasp: Efficient Grasp Synthesis with Diffusion
Nov 22, 2024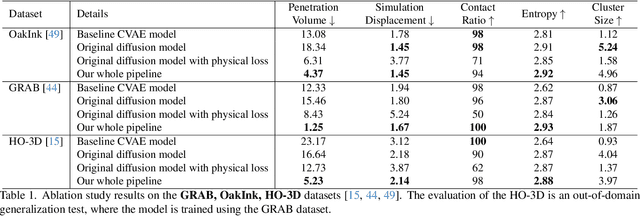
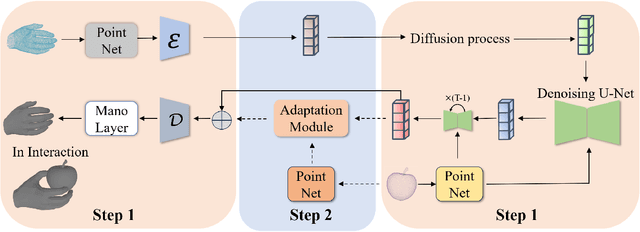
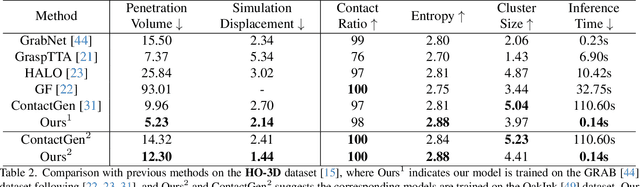
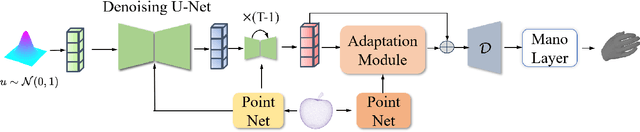
Effectively modeling the interaction between human hands and objects is challenging due to the complex physical constraints and the requirement for high generation efficiency in applications. Prior approaches often employ computationally intensive two-stage approaches, which first generate an intermediate representation, such as contact maps, followed by an iterative optimization procedure that updates hand meshes to capture the hand-object relation. However, due to the high computation complexity during the optimization stage, such strategies often suffer from low efficiency in inference. To address this limitation, this work introduces a novel diffusion-model-based approach that generates the grasping pose in a one-stage manner. This allows us to significantly improve generation speed and the diversity of generated hand poses. In particular, we develop a Latent Diffusion Model with an Adaptation Module for object-conditioned hand pose generation and a contact-aware loss to enforce the physical constraints between hands and objects. Extensive experiments demonstrate that our method achieves faster inference, higher diversity, and superior pose quality than state-of-the-art approaches. Code is available at \href{https://github.com/wuxiaofei01/FastGrasp}{https://github.com/wuxiaofei01/FastGrasp.}
Weakly-supervised Camera Localization by Ground-to-satellite Image Registration
Sep 10, 2024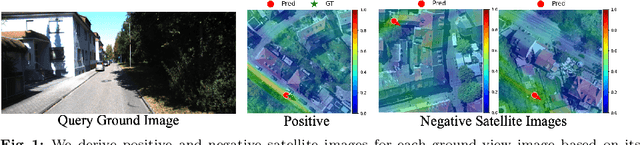
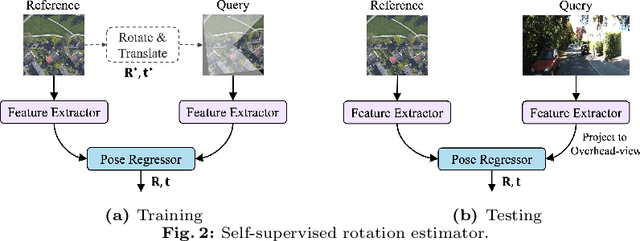

The ground-to-satellite image matching/retrieval was initially proposed for city-scale ground camera localization. This work addresses the problem of improving camera pose accuracy by ground-to-satellite image matching after a coarse location and orientation have been obtained, either from the city-scale retrieval or from consumer-level GPS and compass sensors. Existing learning-based methods for solving this task require accurate GPS labels of ground images for network training. However, obtaining such accurate GPS labels is difficult, often requiring an expensive {\color{black}Real Time Kinematics (RTK)} setup and suffering from signal occlusion, multi-path signal disruptions, \etc. To alleviate this issue, this paper proposes a weakly supervised learning strategy for ground-to-satellite image registration when only noisy pose labels for ground images are available for network training. It derives positive and negative satellite images for each ground image and leverages contrastive learning to learn feature representations for ground and satellite images useful for translation estimation. We also propose a self-supervision strategy for cross-view image relative rotation estimation, which trains the network by creating pseudo query and reference image pairs. Experimental results show that our weakly supervised learning strategy achieves the best performance on cross-area evaluation compared to recent state-of-the-art methods that are reliant on accurate pose labels for supervision.
Adapting Fine-Grained Cross-View Localization to Areas without Fine Ground Truth
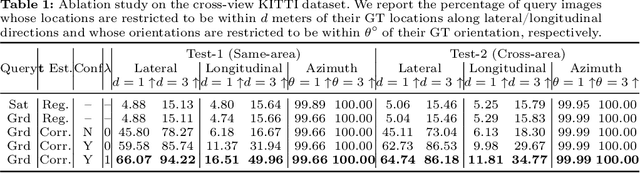
Jun 01, 2024Given a ground-level query image and a geo-referenced aerial image that covers the query's local surroundings, fine-grained cross-view localization aims to estimate the location of the ground camera inside the aerial image. Recent works have focused on developing advanced networks trained with accurate ground truth (GT) locations of ground images. However, the trained models always suffer a performance drop when applied to images in a new target area that differs from training. In most deployment scenarios, acquiring fine GT, i.e. accurate GT locations, for target-area images to re-train the network can be expensive and sometimes infeasible. In contrast, collecting images with noisy GT with errors of tens of meters is often easy. Motivated by this, our paper focuses on improving the performance of a trained model in a new target area by leveraging only the target-area images without fine GT. We propose a weakly supervised learning approach based on knowledge self-distillation. This approach uses predictions from a pre-trained model as pseudo GT to supervise a copy of itself. Our approach includes a mode-based pseudo GT generation for reducing uncertainty in pseudo GT and an outlier filtering method to remove unreliable pseudo GT. Our approach is validated using two recent state-of-the-art models on two benchmarks. The results demonstrate that it consistently and considerably boosts the localization accuracy in the target area.