 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Horizon Electricity Price Forecasting with Deep Learning in the Australian National Electricity Market
Feb 01, 2026Accurate electricity price forecasting (EPF) is essential for operational planning, trading, and flexible asset scheduling in liberalised power systems, yet remains challenging due to volatility, heavy-tailed spikes, and frequent regime shifts. While deep learning (DL) has been increasingly adopted in EPF to capture complex and nonlinear price dynamics, several important gaps persist: (i) limited attention to multi-day horizons beyond day-ahead forecasting, (ii) insufficient exploration of state-of-the-art (SOTA) time series DL models, and (iii) a predominant reliance on aggregated horizon-level evaluation that obscures time-of-day forecasting variation. To address these gaps, we propose a novel EPF framework that extends the forecast horizon to multi-day-ahead by systematically building forecasting models that leverage benchmarked SOTA time series DL models. We conduct a comprehensive evaluation to analyse time-of-day forecasting performance by integrating model assessment at intraday interval levels across all five regions in the Australian National Electricity Market (NEM). The results show that no single model consistently dominates across regions, metrics, and horizons. Overall, standard DL models deliver superior performance in most regions, while SOTA time series DL models demonstrate greater robustness to forecast horizon extension. Intraday interval-level evaluation reveals pronounced diurnal error patterns, indicating that absolute errors peak during the evening ramp, relative errors inflate during midday negative-price regimes, and directional accuracy degrades during periods of frequent trend changes. These findings suggest that future research on DL-based EPF can benefit from enriched feature representations and modelling strategies that enhance longer-term forecasting robustness while maintaining sensitivity to intraday volatility and structural price dynamics.
TabAttackBench: A Benchmark for Adversarial Attacks on Tabular Data
May 27, 2025Adversarial attacks pose a significant threat to machine learning models by inducing incorrect predictions through imperceptible perturbations to input data. While these attacks have been extensively studied in unstructured data like images, their application to tabular data presents new challenges. These challenges arise from the inherent heterogeneity and complex feature interdependencies in tabular data, which differ significantly from those in image data. To address these differences, it is crucial to consider imperceptibility as a key criterion specific to tabular data. Most current research focuses primarily on achieving effective adversarial attacks, often overlooking the importance of maintaining imperceptibility. To address this gap, we propose a new benchmark for adversarial attacks on tabular data that evaluates both effectiveness and imperceptibility. In this study, we assess the effectiveness and imperceptibility of five adversarial attacks across four models using eleven tabular datasets, including both mixed and numerical-only datasets. Our analysis explores how these factors interact and influence the overall performance of the attacks. We also compare the results across different dataset types to understand the broader implications of these findings. The findings from this benchmark provide valuable insights for improving the design of adversarial attack algorithms, thereby advancing the field of adversarial machine learning on tabular data.
DePrompt: Desensitization and Evaluation of Personal Identifiable Information in Large Language Model Prompts
Aug 16, 2024Prompt serves as a crucial link in interacting with large language models (LLMs), widely impacting the accuracy and interpretability of model outputs. However, acquiring accurate and high-quality responses necessitates precise prompts, which inevitably pose significant risks of personal identifiable information (PII) leakage. Therefore, this paper proposes DePrompt, a desensitization protection and effectiveness evaluation framework for prompt, enabling users to safely and transparently utilize LLMs. Specifically, by leveraging large model fine-tuning techniques as the underlying privacy protection method, we integrate contextual attributes to define privacy types, achieving high-precision PII entity identification. Additionally, through the analysis of key features in prompt desensitization scenarios, we devise adversarial generative desensitization methods that retain important semantic content while disrupting the link between identifiers and privacy attributes. Furthermore, we present utility evaluation metrics for prompt to better gauge and balance privacy and usability. Our framework is adaptable to prompts and can be extended to text usability-dependent scenarios. Through comparison with benchmarks and other model methods, experimental evaluations demonstrate that our desensitized prompt exhibit superior privacy protection utility and model inference results.
Investigating Imperceptibility of Adversarial Attacks on Tabular Data: An Empirical Analysis
Jul 16, 2024Adversarial attacks are a potential threat to machine learning models, as they can cause the model to make incorrect predictions by introducing imperceptible perturbations to the input data. While extensively studied in unstructured data like images, their application to structured data like tabular data presents unique challenges due to the heterogeneity and intricate feature interdependencies of tabular data. Imperceptibility in tabular data involves preserving data integrity while potentially causing misclassification, underscoring the need for tailored imperceptibility criteria for tabular data. However, there is currently a lack of standardised metrics for assessing adversarial attacks specifically targeted at tabular data. To address this gap, we derive a set of properties for evaluating the imperceptibility of adversarial attacks on tabular data. These properties are defined to capture seven perspectives of perturbed data: proximity to original inputs, sparsity of alterations, deviation to datapoints in the original dataset, sensitivity of altering sensitive features, immutability of perturbation, feasibility of perturbed values and intricate feature interdepencies among tabular features. Furthermore, we conduct both quantitative empirical evaluation and case-based qualitative examples analysis for seven properties. The evaluation reveals a trade-off between attack success and imperceptibility, particularly concerning proximity, sensitivity, and deviation. Although no evaluated attacks can achieve optimal effectiveness and imperceptibility simultaneously, unbounded attacks prove to be more promised for tabular data in crafting imperceptible adversarial examples. The study also highlights the limitation of evaluated algorithms in controlling sparsity effectively. We suggest incorporating a sparsity metric in future attack design to regulate the number of perturbed features.
LetsGo: Large-Scale Garage Modeling and Rendering via LiDAR-Assisted Gaussian Primitives
Apr 15, 2024



Large garages are ubiquitous yet intricate scenes in our daily lives, posing challenges characterized by monotonous colors, repetitive patterns, reflective surfaces, and transparent vehicle glass. Conventional Structure from Motion (SfM) methods for camera pose estimation and 3D reconstruction fail in these environments due to poor correspondence construction. To address these challenges, this paper introduces LetsGo, a LiDAR-assisted Gaussian splatting approach for large-scale garage modeling and rendering. We develop a handheld scanner, Polar, equipped with IMU, LiDAR, and a fisheye camera, to facilitate accurate LiDAR and image data scanning. With this Polar device, we present a GarageWorld dataset consisting of five expansive garage scenes with diverse geometric structures and will release the dataset to the community for further research. We demonstrate that the collected LiDAR point cloud by the Polar device enhances a suite of 3D Gaussian splatting algorithms for garage scene modeling and rendering. We also propose a novel depth regularizer for 3D Gaussian splatting algorithm training, effectively eliminating floating artifacts in rendered images, and a lightweight Level of Detail (LOD) Gaussian renderer for real-time viewing on web-based devices. Additionally, we explore a hybrid representation that combines the advantages of traditional mesh in depicting simple geometry and colors (e.g., walls and the ground) with modern 3D Gaussian representations capturing complex details and high-frequency textures. This strategy achieves an optimal balance between memory performance and rendering quality. Experimental results on our dataset, along with ScanNet++ and KITTI-360, demonstrate the superiority of our method in rendering quality and resource efficiency.
SoK: Comparing Different Membership Inference Attacks with a Comprehensive Benchmark
Jul 12, 2023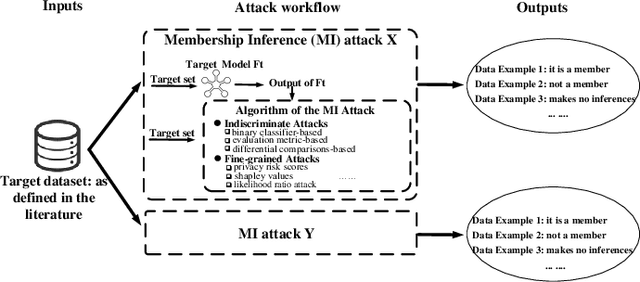
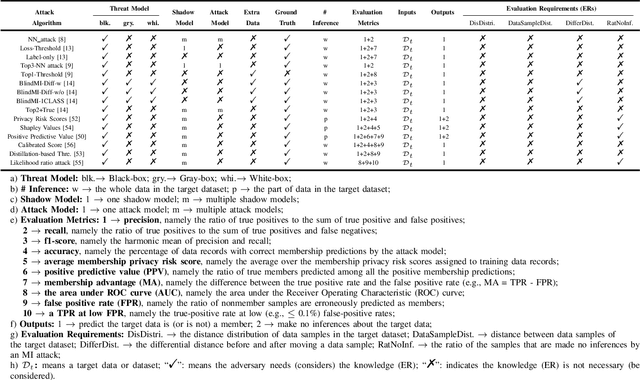

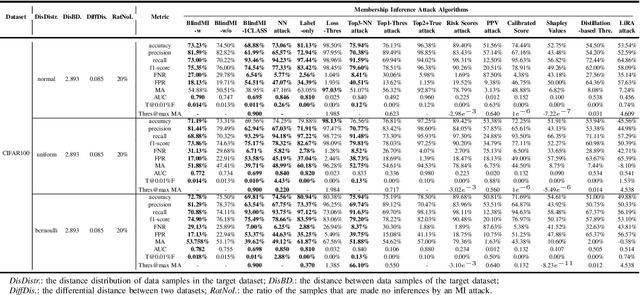
Membership inference (MI) attacks threaten user privacy through determining if a given data example has been used to train a target model. However, it has been increasingly recognized that the "comparing different MI attacks" methodology used in the existing works has serious limitations. Due to these limitations, we found (through the experiments in this work) that some comparison results reported in the literature are quite misleading. In this paper, we seek to develop a comprehensive benchmark for comparing different MI attacks, called MIBench, which consists not only the evaluation metrics, but also the evaluation scenarios. And we design the evaluation scenarios from four perspectives: the distance distribution of data samples in the target dataset, the distance between data samples of the target dataset, the differential distance between two datasets (i.e., the target dataset and a generated dataset with only nonmembers), and the ratio of the samples that are made no inferences by an MI attack. The evaluation metrics consist of ten typical evaluation metrics. We have identified three principles for the proposed "comparing different MI attacks" methodology, and we have designed and implemented the MIBench benchmark with 84 evaluation scenarios for each dataset. In total, we have used our benchmark to fairly and systematically compare 15 state-of-the-art MI attack algorithms across 588 evaluation scenarios, and these evaluation scenarios cover 7 widely used datasets and 7 representative types of models. All codes and evaluations of MIBench are publicly available at https://github.com/MIBench/MIBench.github.io/blob/main/README.md.
Building Interpretable Models for Business Process Prediction using Shared and Specialised Attention Mechanisms
Sep 03, 2021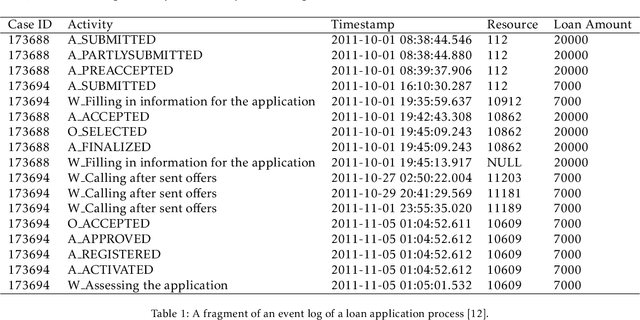
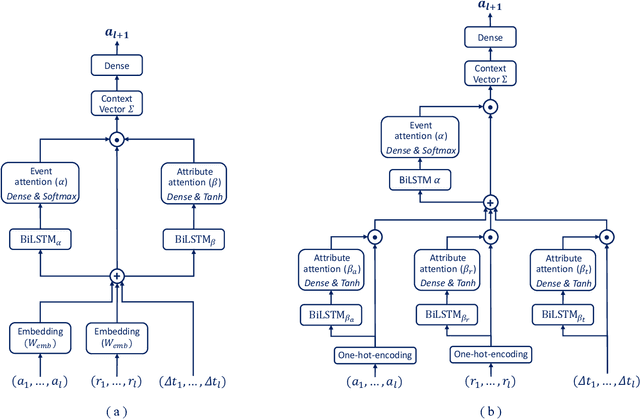
In this paper, we address the "black-box" problem in predictive process analytics by building interpretable models that are capable to inform both what and why is a prediction. Predictive process analytics is a newly emerged discipline dedicated to providing business process intelligence in modern organisations. It uses event logs, which capture process execution traces in the form of multi-dimensional sequence data, as the key input to train predictive models. These predictive models, often built upon deep learning techniques, can be used to make predictions about the future states of business process execution. We apply attention mechanism to achieve model interpretability. We propose i) two types of attentions: event attention to capture the impact of specific process events on a prediction, and attribute attention to reveal which attribute(s) of an event influenced the prediction; and ii) two attention mechanisms: shared attention mechanism and specialised attention mechanism to reflect different design decisions in when to construct attribute attention on individual input features (specialised) or using the concatenated feature tensor of all input feature vectors (shared). These lead to two distinct attention-based models, and both are interpretable models that incorporate interpretability directly into the structure of a process predictive model. We conduct experimental evaluation of the proposed models using real-life dataset, and comparative analysis between the models for accuracy and interpretability, and draw insights from the evaluation and analysis results.