 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Testing and Adapting REST APIs as LLM Tools
Apr 22, 2025Large Language Models (LLMs) are enabling autonomous agents to perform complex workflows using external tools or functions, often provided via REST APIs in enterprise systems. However, directly utilizing these APIs as tools poses challenges due to their complex input schemas, elaborate responses, and often ambiguous documentation. Current benchmarks for tool testing do not adequately address these complexities, leading to a critical gap in evaluating API readiness for agent-driven automation. In this work, we present a novel testing framework aimed at evaluating and enhancing the readiness of REST APIs to function as tools for LLM-based agents. Our framework transforms apis as tools, generates comprehensive test cases for the APIs, translates tests cases into natural language instructions suitable for agents, enriches tool definitions and evaluates the agent's ability t correctly invoke the API and process its inputs and responses. To provide actionable insights, we analyze the outcomes of 750 test cases, presenting a detailed taxonomy of errors, including input misinterpretation, output handling inconsistencies, and schema mismatches. Additionally, we classify these test cases to streamline debugging and refinement of tool integrations. This work offers a foundational step toward enabling enterprise APIs as tools, improving their usability in agent-based applications.
AutoMixer for Improved Multivariate Time-Series Forecasting on Business and IT Observability Data
Nov 02, 2023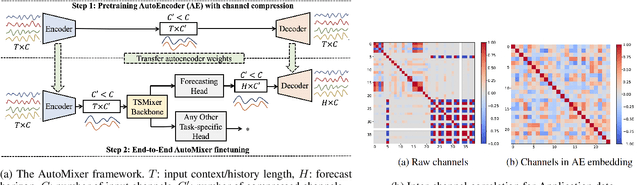
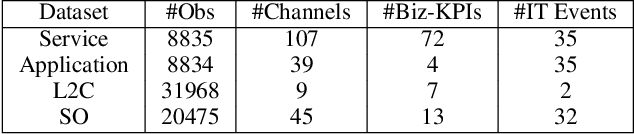
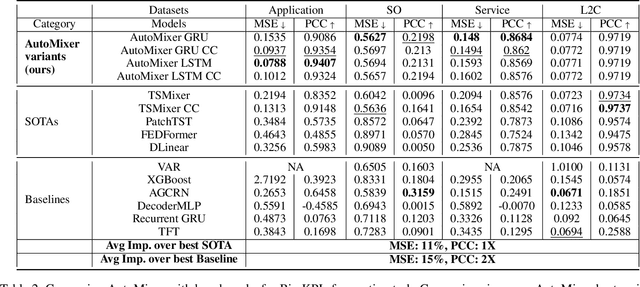
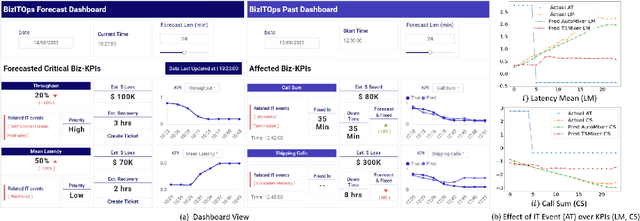
The efficiency of business processes relies on business key performance indicators (Biz-KPIs), that can be negatively impacted by IT failures. Business and IT Observability (BizITObs) data fuses both Biz-KPIs and IT event channels together as multivariate time series data. Forecasting Biz-KPIs in advance can enhance efficiency and revenue through proactive corrective measures. However, BizITObs data generally exhibit both useful and noisy inter-channel interactions between Biz-KPIs and IT events that need to be effectively decoupled. This leads to suboptimal forecasting performance when existing multivariate forecasting models are employed. To address this, we introduce AutoMixer, a time-series Foundation Model (FM) approach, grounded on the novel technique of channel-compressed pretrain and finetune workflows. AutoMixer leverages an AutoEncoder for channel-compressed pretraining and integrates it with the advanced TSMixer model for multivariate time series forecasting. This fusion greatly enhances the potency of TSMixer for accurate forecasts and also generalizes well across several downstream tasks. Through detailed experiments and dashboard analytics, we show AutoMixer's capability to consistently improve the Biz-KPI's forecasting accuracy (by 11-15\%) which directly translates to actionable business insights.
Goal-Oriented Next Best Activity Recommendation using Reinforcement Learning
May 06, 2022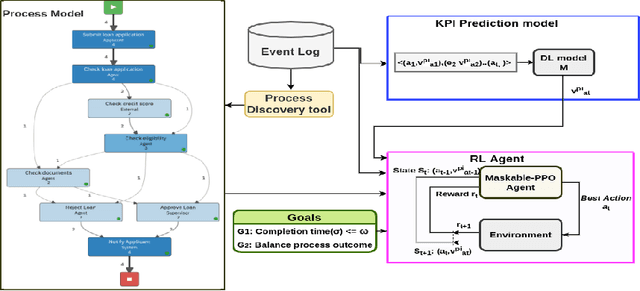
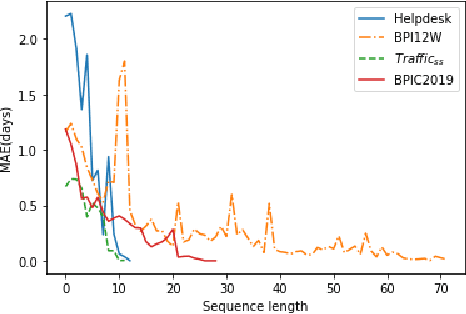
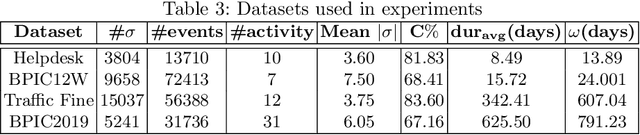
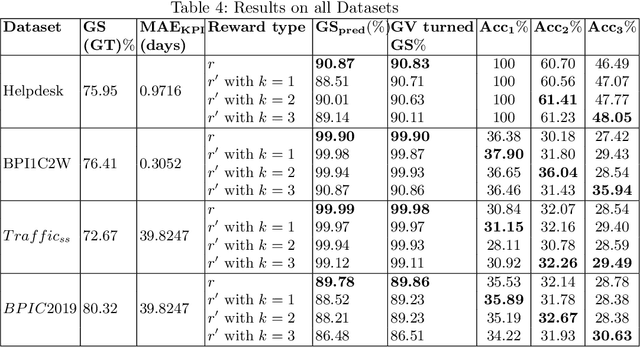
Recommending a sequence of activities for an ongoing case requires that the recommendations conform to the underlying business process and meet the performance goal of either completion time or process outcome. Existing work on next activity prediction can predict the future activity but cannot provide guarantees of the prediction being conformant or meeting the goal. Hence, we propose a goal-oriented next best activity recommendation. Our proposed framework uses a deep learning model to predict the next best activity and an estimated value of a goal given the activity. A reinforcement learning method explores the sequence of activities based on the estimates likely to meet one or more goals. We further address a real-world problem of multiple goals by introducing an additional reward function to balance the outcome of a recommended activity and satisfy the goal. We demonstrate the effectiveness of the proposed method on four real-world datasets with different characteristics. The results show that the recommendations from our proposed approach outperform in goal satisfaction and conformance compared to the existing state-of-the-art next best activity recommendation techniques.
Building Interpretable Models for Business Process Prediction using Shared and Specialised Attention Mechanisms
Sep 03, 2021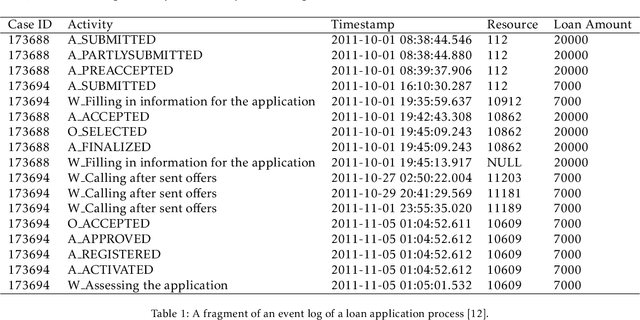
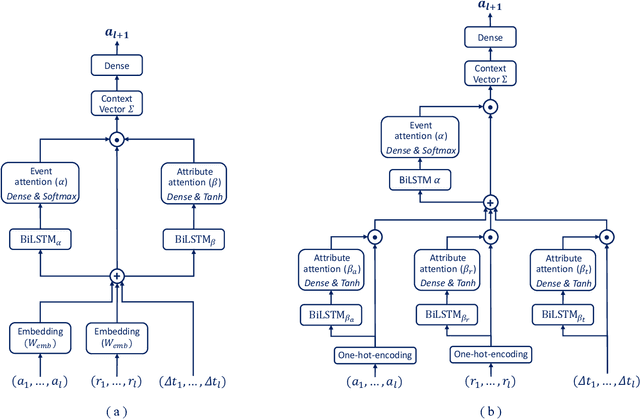
In this paper, we address the "black-box" problem in predictive process analytics by building interpretable models that are capable to inform both what and why is a prediction. Predictive process analytics is a newly emerged discipline dedicated to providing business process intelligence in modern organisations. It uses event logs, which capture process execution traces in the form of multi-dimensional sequence data, as the key input to train predictive models. These predictive models, often built upon deep learning techniques, can be used to make predictions about the future states of business process execution. We apply attention mechanism to achieve model interpretability. We propose i) two types of attentions: event attention to capture the impact of specific process events on a prediction, and attribute attention to reveal which attribute(s) of an event influenced the prediction; and ii) two attention mechanisms: shared attention mechanism and specialised attention mechanism to reflect different design decisions in when to construct attribute attention on individual input features (specialised) or using the concatenated feature tensor of all input feature vectors (shared). These lead to two distinct attention-based models, and both are interpretable models that incorporate interpretability directly into the structure of a process predictive model. We conduct experimental evaluation of the proposed models using real-life dataset, and comparative analysis between the models for accuracy and interpretability, and draw insights from the evaluation and analysis results.
Explainable AI Enabled Inspection of Business Process Prediction Models
Jul 16, 2021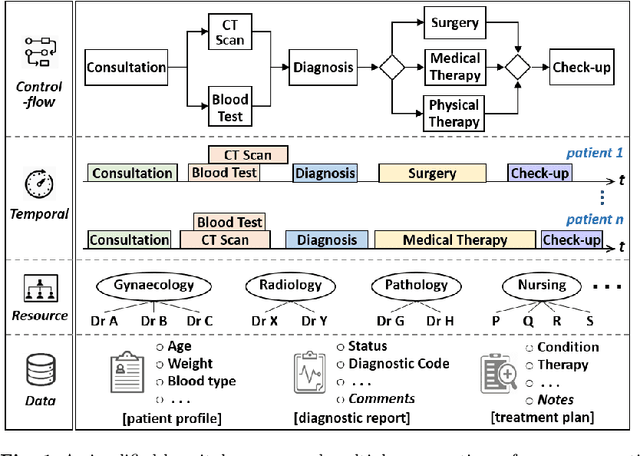

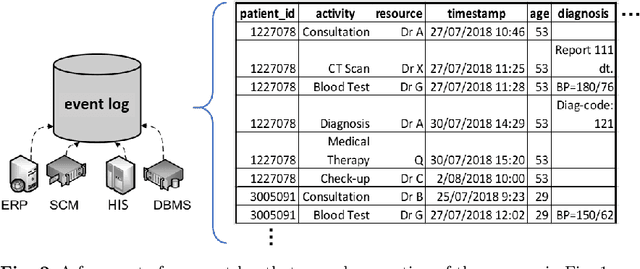
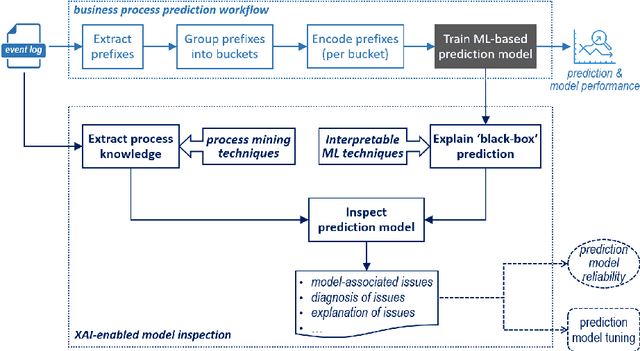
Modern data analytics underpinned by machine learning techniques has become a key enabler to the automation of data-led decision making. As an important branch of state-of-the-art data analytics, business process predictions are also faced with a challenge in regard to the lack of explanation to the reasoning and decision by the underlying `black-box' prediction models. With the development of interpretable machine learning techniques, explanations can be generated for a black-box model, making it possible for (human) users to access the reasoning behind machine learned predictions. In this paper, we aim to present an approach that allows us to use model explanations to investigate certain reasoning applied by machine learned predictions and detect potential issues with the underlying methods thus enhancing trust in business process prediction models. A novel contribution of our approach is the proposal of model inspection that leverages both the explanations generated by interpretable machine learning mechanisms and the contextual or domain knowledge extracted from event logs that record historical process execution. Findings drawn from this work are expected to serve as a key input to developing model reliability metrics and evaluation in the context of business process predictions.
Developing a Fidelity Evaluation Approach for Interpretable Machine Learning
Jun 16, 2021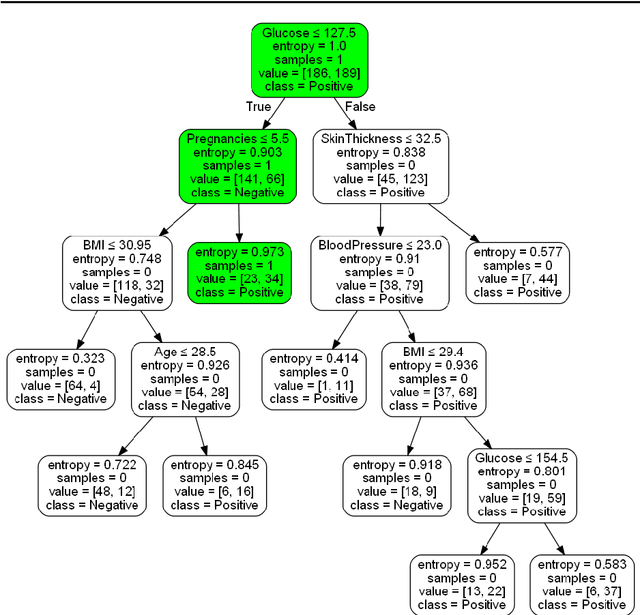
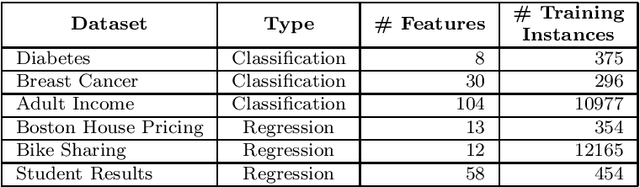
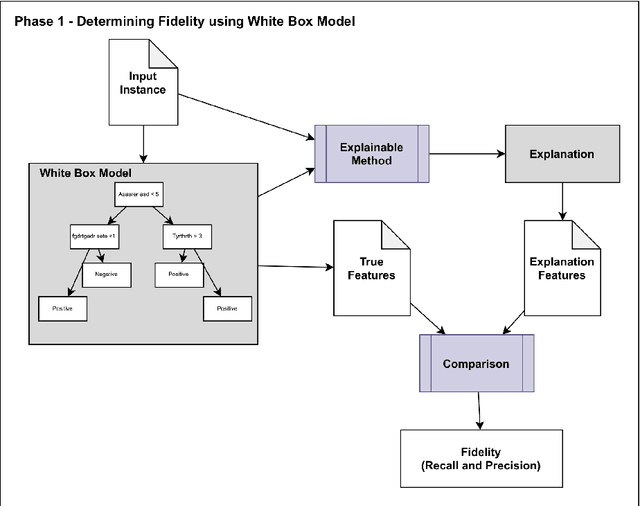
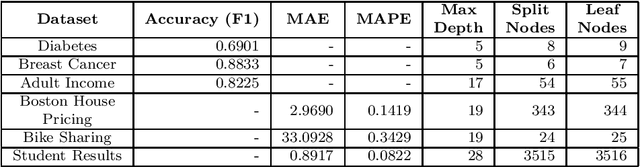
Although modern machine learning and deep learning methods allow for complex and in-depth data analytics, the predictive models generated by these methods are often highly complex, and lack transparency. Explainable AI (XAI) methods are used to improve the interpretability of these complex models, and in doing so improve transparency. However, the inherent fitness of these explainable methods can be hard to evaluate. In particular, methods to evaluate the fidelity of the explanation to the underlying black box require further development, especially for tabular data. In this paper, we (a) propose a three phase approach to developing an evaluation method; (b) adapt an existing evaluation method primarily for image and text data to evaluate models trained on tabular data; and (c) evaluate two popular explainable methods using this evaluation method. Our evaluations suggest that the internal mechanism of the underlying predictive model, the internal mechanism of the explainable method used and model and data complexity all affect explanation fidelity. Given that explanation fidelity is so sensitive to context and tools and data used, we could not clearly identify any specific explainable method as being superior to another.
Evaluating Explainable Methods for Predictive Process Analytics: A Functionally-Grounded Approach
Dec 08, 2020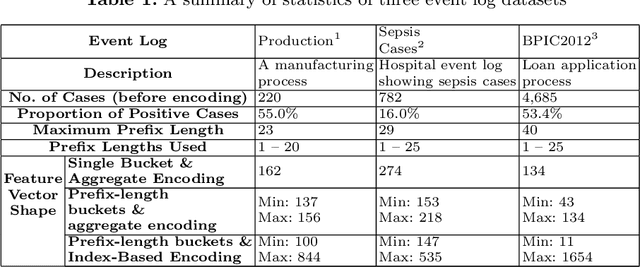
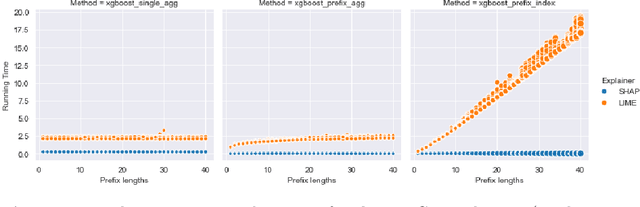
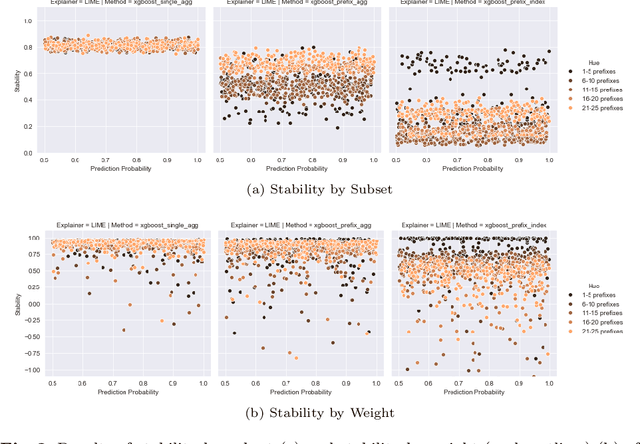
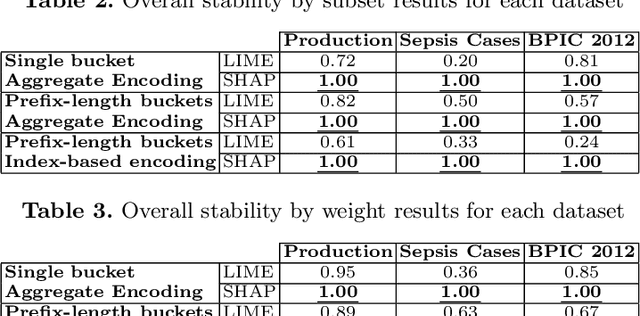
Predictive process analytics focuses on predicting the future states of running instances of a business process. While advanced machine learning techniques have been used to increase accuracy of predictions, the resulting predictive models lack transparency. Current explainable machine learning methods, such as LIME and SHAP, can be used to interpret black box models. However, it is unclear how fit for purpose these methods are in explaining process predictive models. In this paper, we draw on evaluation measures used in the field of explainable AI and propose functionally-grounded evaluation metrics for assessing explainable methods in predictive process analytics. We apply the proposed metrics to evaluate the performance of LIME and SHAP in interpreting process predictive models built on XGBoost, which has been shown to be relatively accurate in process predictions. We conduct the evaluation using three open source, real-world event logs and analyse the evaluation results to derive insights. The research contributes to understanding the trustworthiness of explainable methods for predictive process analytics as a fundamental and key step towards human user-oriented evaluation.
An Interpretable Probabilistic Approach for Demystifying Black-box Predictive Models
Jul 21, 2020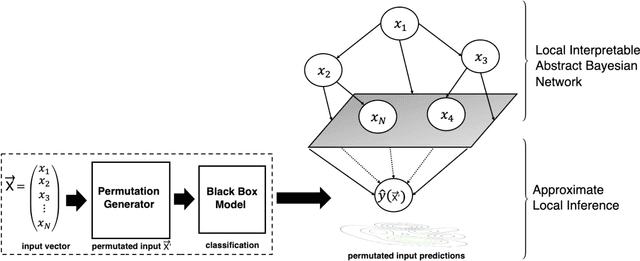

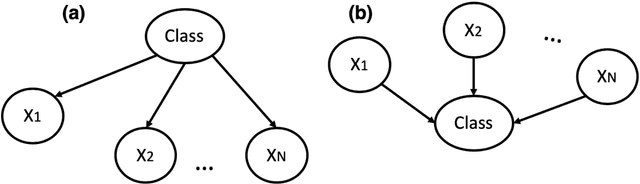
The use of sophisticated machine learning models for critical decision making is faced with a challenge that these models are often applied as a "black-box". This has led to an increased interest in interpretable machine learning, where post hoc interpretation presents a useful mechanism for generating interpretations of complex learning models. In this paper, we propose a novel approach underpinned by an extended framework of Bayesian networks for generating post hoc interpretations of a black-box predictive model. The framework supports extracting a Bayesian network as an approximation of the black-box model for a specific prediction. Compared to the existing post hoc interpretation methods, the contribution of our approach is three-fold. Firstly, the extracted Bayesian network, as a probabilistic graphical model, can provide interpretations about not only what input features but also why these features contributed to a prediction. Secondly, for complex decision problems with many features, a Markov blanket can be generated from the extracted Bayesian network to provide interpretations with a focused view on those input features that directly contributed to a prediction. Thirdly, the extracted Bayesian network enables the identification of four different rules which can inform the decision-maker about the confidence level in a prediction, thus helping the decision-maker assess the reliability of predictions learned by a black-box model. We implemented the proposed approach, applied it in the context of two well-known public datasets and analysed the results, which are made available in an open-source repository.
An Investigation of Interpretability Techniques for Deep Learning in Predictive Process Analytics
Feb 21, 2020
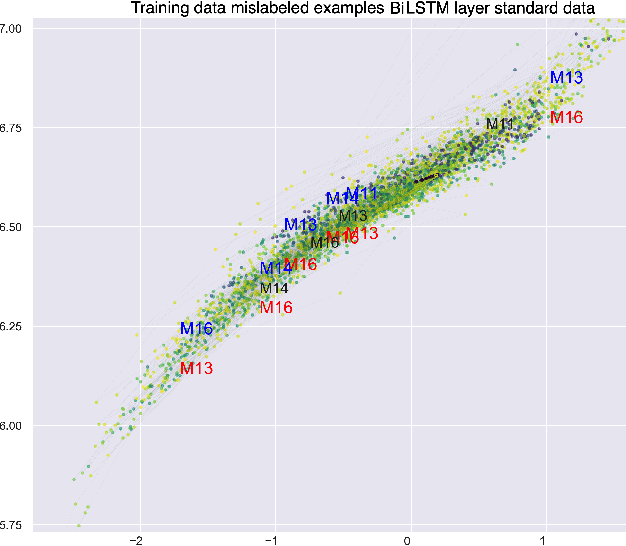
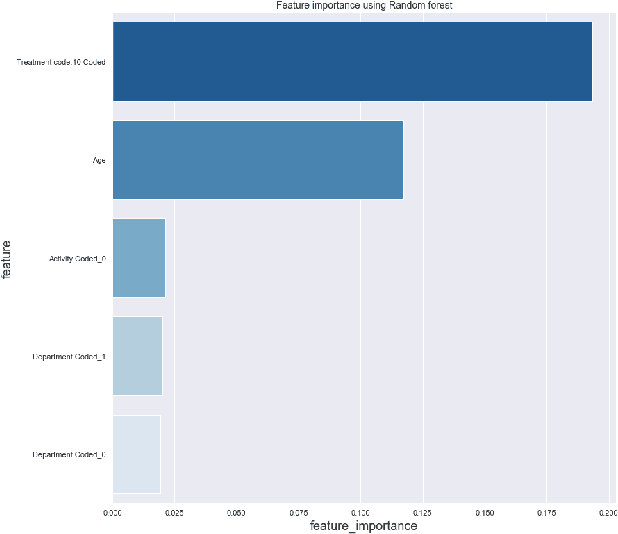

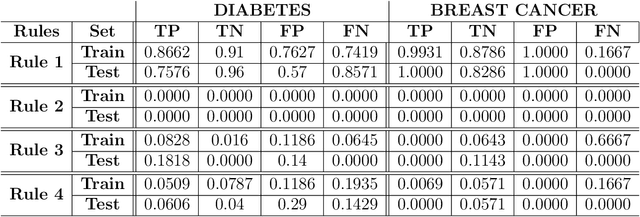
This paper explores interpretability techniques for two of the most successful learning algorithms in medical decision-making literature: deep neural networks and random forests. We applied these algorithms in a real-world medical dataset containing information about patients with cancer, where we learn models that try to predict the type of cancer of the patient, given their set of medical activity records. We explored different algorithms based on neural network architectures using long short term deep neural networks, and random forests. Since there is a growing need to provide decision-makers understandings about the logic of predictions of black boxes, we also explored different techniques that provide interpretations for these classifiers. In one of the techniques, we intercepted some hidden layers of these neural networks and used autoencoders in order to learn what is the representation of the input in the hidden layers. In another, we investigated an interpretable model locally around the random forest's prediction. Results show learning an interpretable model locally around the model's prediction leads to a higher understanding of why the algorithm is making some decision. Use of local and linear model helps identify the features used in prediction of a specific instance or data point. We see certain distinct features used for predictions that provide useful insights about the type of cancer, along with features that do not generalize well. In addition, the structured deep learning approach using autoencoders provided meaningful prediction insights, which resulted in the identification of nonlinear clusters correspondent to the patients' different types of cancer.
Interpreting Predictive Process Monitoring Benchmarks
Dec 22, 2019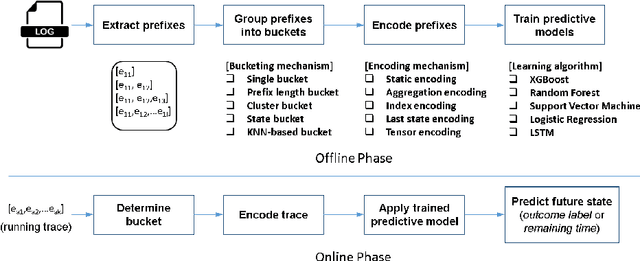

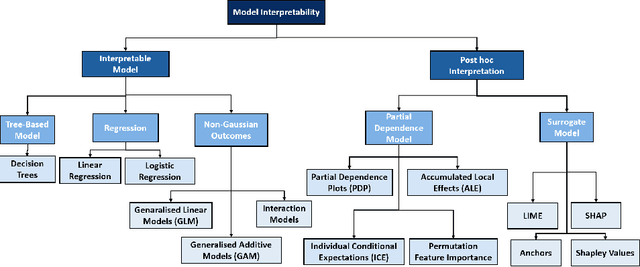
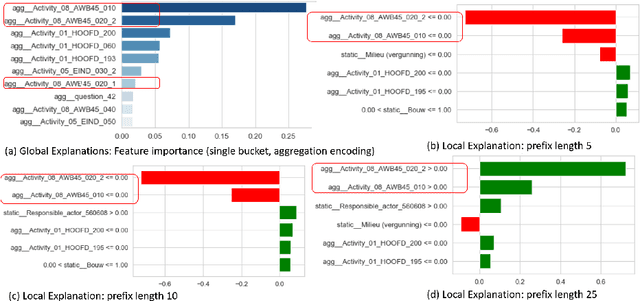
Predictive process analytics has recently gained significant attention, and yet its successful adoption in organisations relies on how well users can trust the predictions of the underlying machine learning algorithms that are often applied and recognised as a `black-box'. Without understanding the rationale of the black-box machinery, there will be a lack of trust in the predictions, a reluctance to use the predictions, and in the worse case, consequences of an incorrect decision based on the prediction. In this paper, we emphasise the importance of interpreting the predictive models in addition to the evaluation using conventional metrics, such as accuracy, in the context of predictive process monitoring. We review existing studies on business process monitoring benchmarks for predicting process outcomes and remaining time. We derive explanations that present the behaviour of the entire predictive model as well as explanations describing a particular prediction. These explanations are used to reveal data leakages, assess the interpretability of features used by the model, and the degree of the use of process knowledge in the existing benchmark models. Findings from this exploratory study motivate the need to incorporate interpretability in predictive process analytics.