 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmark Evaluation of Counterfactual Algorithms for XAI: From a White Box to a Black Box
Mar 04, 2022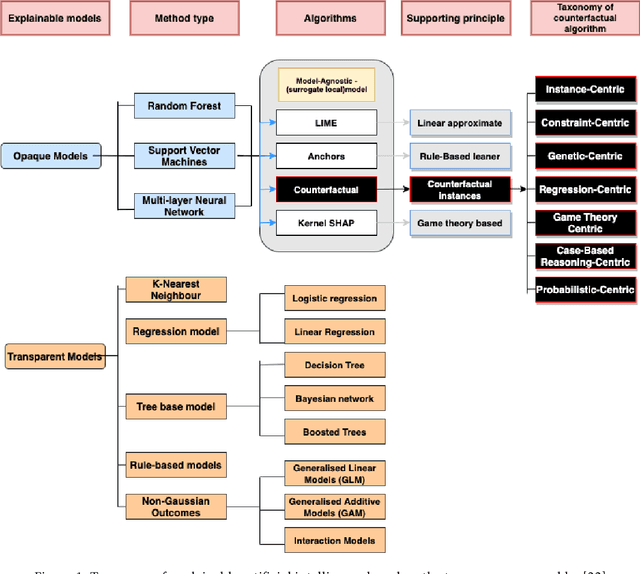

Counterfactual explanations have recently been brought to light as a potentially crucial response to obtaining human-understandable explanations from predictive models in Explainable Artificial Intelligence (XAI). Despite the fact that various counterfactual algorithms have been proposed, the state of the art research still lacks standardised protocols to evaluate the quality of counterfactual explanations. In this work, we conducted a benchmark evaluation across different model agnostic counterfactual algorithms in the literature (DiCE, WatcherCF, prototype, unjustifiedCF), and we investigated the counterfactual generation process on different types of machine learning models ranging from a white box (decision tree) to a grey-box (random forest) and a black box (neural network). We evaluated the different counterfactual algorithms using several metrics including proximity, interpretability and functionality for five datasets. The main findings of this work are the following: (1) without guaranteeing plausibility in the counterfactual generation process, one cannot have meaningful evaluation results. This means that all explainable counterfactual algorithms that do not take into consideration plausibility in their internal mechanisms cannot be evaluated with the current state of the art evaluation metrics; (2) the counterfactual generated are not impacted by the different types of machine learning models; (3) DiCE was the only tested algorithm that was able to generate actionable and plausible counterfactuals, because it provides mechanisms to constraint features; (4) WatcherCF and UnjustifiedCF are limited to continuous variables and can not deal with categorical data.
Counterfactuals and Causability in Explainable Artificial Intelligence: Theory, Algorithms, and Applications
Mar 07, 2021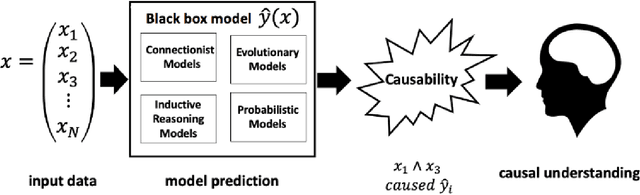



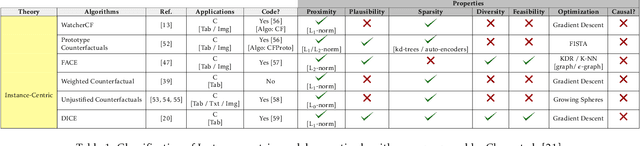
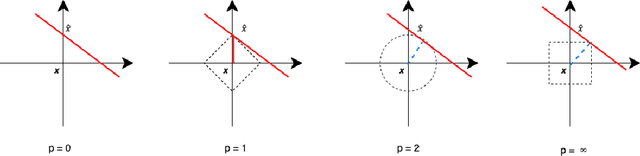
There has been a growing interest in model-agnostic methods that can make deep learning models more transparent and explainable to a user. Some researchers recently argued that for a machine to achieve a certain degree of human-level explainability, this machine needs to provide human causally understandable explanations, also known as causability. A specific class of algorithms that have the potential to provide causability are counterfactuals. This paper presents an in-depth systematic review of the diverse existing body of literature on counterfactuals and causability for explainable artificial intelligence. We performed an LDA topic modelling analysis under a PRISMA framework to find the most relevant literature articles. This analysis resulted in a novel taxonomy that considers the grounding theories of the surveyed algorithms, together with their underlying properties and applications in real-world data. This research suggests that current model-agnostic counterfactual algorithms for explainable AI are not grounded on a causal theoretical formalism and, consequently, cannot promote causability to a human decision-maker. Our findings suggest that the explanations derived from major algorithms in the literature provide spurious correlations rather than cause/effects relationships, leading to sub-optimal, erroneous or even biased explanations. This paper also advances the literature with new directions and challenges on promoting causability in model-agnostic approaches for explainable artificial intelligence.
An Interpretable Probabilistic Approach for Demystifying Black-box Predictive Models
Jul 21, 2020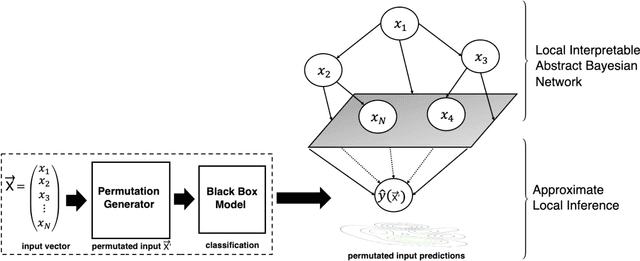

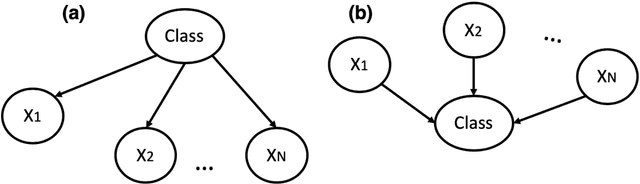
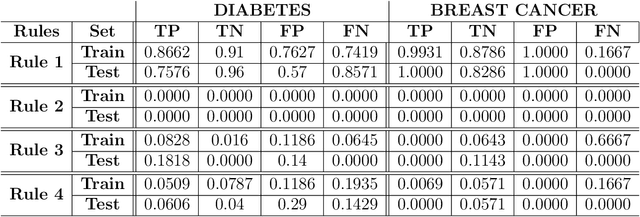
The use of sophisticated machine learning models for critical decision making is faced with a challenge that these models are often applied as a "black-box". This has led to an increased interest in interpretable machine learning, where post hoc interpretation presents a useful mechanism for generating interpretations of complex learning models. In this paper, we propose a novel approach underpinned by an extended framework of Bayesian networks for generating post hoc interpretations of a black-box predictive model. The framework supports extracting a Bayesian network as an approximation of the black-box model for a specific prediction. Compared to the existing post hoc interpretation methods, the contribution of our approach is three-fold. Firstly, the extracted Bayesian network, as a probabilistic graphical model, can provide interpretations about not only what input features but also why these features contributed to a prediction. Secondly, for complex decision problems with many features, a Markov blanket can be generated from the extracted Bayesian network to provide interpretations with a focused view on those input features that directly contributed to a prediction. Thirdly, the extracted Bayesian network enables the identification of four different rules which can inform the decision-maker about the confidence level in a prediction, thus helping the decision-maker assess the reliability of predictions learned by a black-box model. We implemented the proposed approach, applied it in the context of two well-known public datasets and analysed the results, which are made available in an open-source repository.