 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDALL-M: Context-Aware Clinical Data Augmentation with LLMs
Jul 11, 2024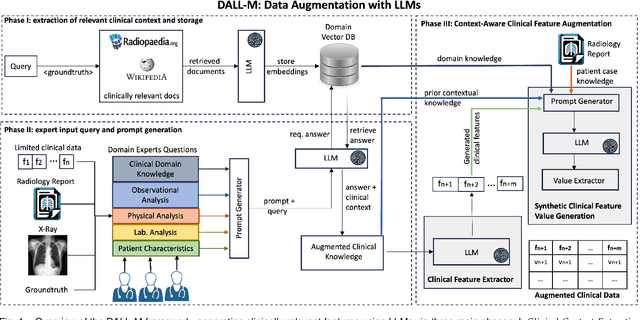


X-ray images are vital in medical diagnostics, but their effectiveness is limited without clinical context. Radiologists often find chest X-rays insufficient for diagnosing underlying diseases, necessitating comprehensive clinical features and data integration. We present a novel technique to enhance the clinical context through augmentation techniques with clinical tabular data, thereby improving its applicability and reliability in AI medical diagnostics. To address this, we introduce a pioneering approach to clinical data augmentation that employs large language models (LLMs) to generate patient contextual synthetic data. This methodology is crucial for training more robust deep learning models in healthcare. It preserves the integrity of real patient data while enriching the dataset with contextually relevant synthetic features, significantly enhancing model performance. DALL-M uses a three-phase feature generation process: (i) clinical context storage, (ii) expert query generation, and (iii) context-aware feature augmentation. DALL-M generates new, clinically relevant features by synthesizing chest X-ray images and reports. Applied to 799 cases using nine features from the MIMIC-IV dataset, it created an augmented set of 91 features. This is the first work to generate contextual values for existing and new features based on patients' X-ray reports, gender, and age and to produce new contextual knowledge during data augmentation. Empirical validation with machine learning models, including Decision Trees, Random Forests, XGBoost, and TabNET, showed significant performance improvements. Incorporating augmented features increased the F1 score by 16.5% and Precision and Recall by approximately 25%. DALL-M addresses a critical gap in clinical data augmentation, offering a robust framework for generating contextually enriched datasets.
MDF-Net: Multimodal Dual-Fusion Network for Abnormality Detection using CXR Images and Clinical Data
Feb 26, 2023This study aims to investigate the effects of including patients' clinical information on the performance of deep learning (DL) classifiers for disease location in chest X-ray images. Although current classifiers achieve high performance using chest X-ray images alone, our interviews with radiologists indicate that clinical data is highly informative and essential for interpreting images and making proper diagnoses. In this work, we propose a novel architecture consisting of two fusion methods that enable the model to simultaneously process patients' clinical data (structured data) and chest X-rays (image data). Since these data modalities are in different dimensional spaces, we propose a spatial arrangement strategy, termed spatialization, to facilitate the multimodal learning process in a Mask R-CNN model. We performed an extensive experimental evaluation comprising three datasets with different modalities: MIMIC CXR (chest X-ray images), MIMIC IV-ED (patients' clinical data), and REFLACX (annotations of disease locations in chest X-rays). Results show that incorporating patients' clinical data in a DL model together with the proposed fusion methods improves the performance of disease localization in chest X-rays by 12\% in terms of Average Precision compared to a standard Mask R-CNN using only chest X-rays. Further ablation studies also emphasize the importance of multimodal DL architectures and the incorporation of patients' clinical data in disease localisation. The architecture proposed in this work is publicly available to promote the scientific reproducibility of our study (https://github.com/ChihchengHsieh/multimodal-abnormalities-detection).
Integrating Eye-Gaze Data into CXR DL Approaches: A Preliminary study
Feb 06, 2023


This paper proposes a novel multimodal DL architecture incorporating medical images and eye-tracking data for abnormality detection in chest x-rays. Our results show that applying eye gaze data directly into DL architectures does not show superior predictive performance in abnormality detection chest X-rays. These results support other works in the literature and suggest that human-generated data, such as eye gaze, needs a more thorough investigation before being applied to DL architectures.
Benchmark Evaluation of Counterfactual Algorithms for XAI: From a White Box to a Black Box
Mar 04, 2022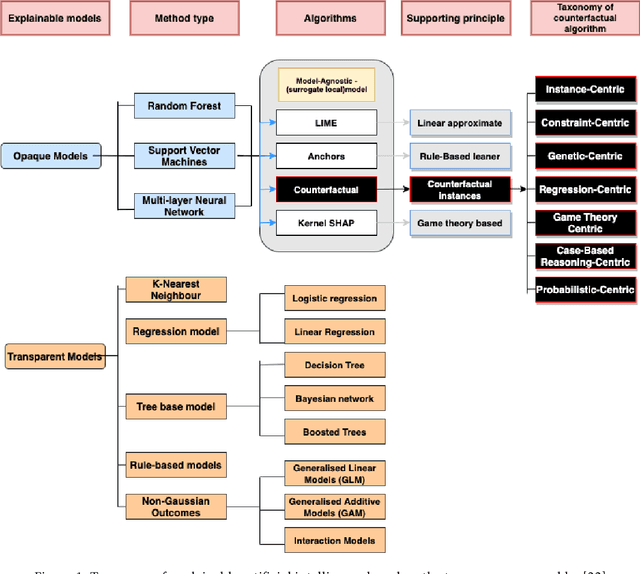
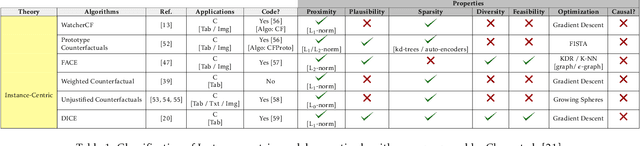
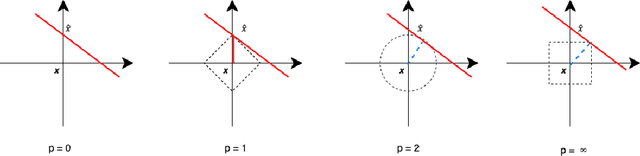

Counterfactual explanations have recently been brought to light as a potentially crucial response to obtaining human-understandable explanations from predictive models in Explainable Artificial Intelligence (XAI). Despite the fact that various counterfactual algorithms have been proposed, the state of the art research still lacks standardised protocols to evaluate the quality of counterfactual explanations. In this work, we conducted a benchmark evaluation across different model agnostic counterfactual algorithms in the literature (DiCE, WatcherCF, prototype, unjustifiedCF), and we investigated the counterfactual generation process on different types of machine learning models ranging from a white box (decision tree) to a grey-box (random forest) and a black box (neural network). We evaluated the different counterfactual algorithms using several metrics including proximity, interpretability and functionality for five datasets. The main findings of this work are the following: (1) without guaranteeing plausibility in the counterfactual generation process, one cannot have meaningful evaluation results. This means that all explainable counterfactual algorithms that do not take into consideration plausibility in their internal mechanisms cannot be evaluated with the current state of the art evaluation metrics; (2) the counterfactual generated are not impacted by the different types of machine learning models; (3) DiCE was the only tested algorithm that was able to generate actionable and plausible counterfactuals, because it provides mechanisms to constraint features; (4) WatcherCF and UnjustifiedCF are limited to continuous variables and can not deal with categorical data.
Interpreting Process Predictions using a Milestone-Aware Counterfactual Approach
Jul 19, 2021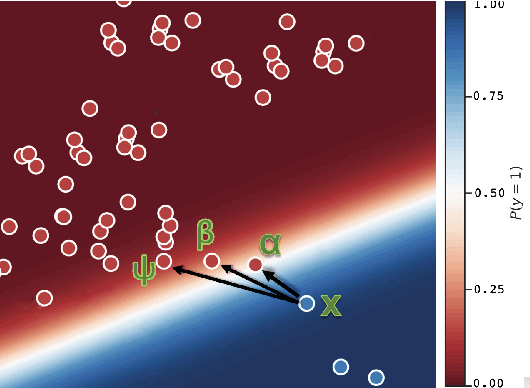


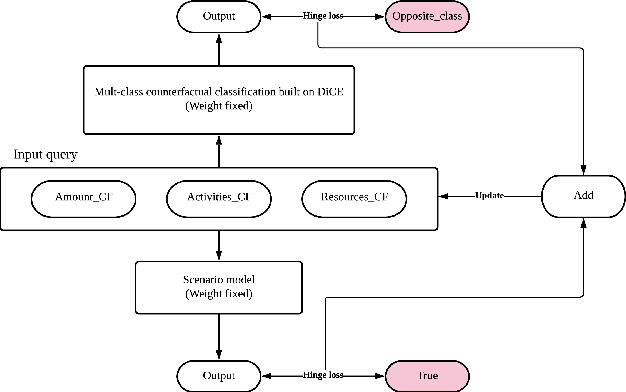
Predictive process analytics often apply machine learning to predict the future states of a running business process. However, the internal mechanisms of many existing predictive algorithms are opaque and a human decision-maker is unable to understand \emph{why} a certain activity was predicted. Recently, counterfactuals have been proposed in the literature to derive human-understandable explanations from predictive models. Current counterfactual approaches consist of finding the minimum feature change that can make a certain prediction flip its outcome. Although many algorithms have been proposed, their application to the sequence and multi-dimensional data like event logs has not been explored in the literature. In this paper, we explore the use of a recent, popular model-agnostic counterfactual algorithm, DiCE, in the context of predictive process analytics. The analysis reveals that the algorithm is limited when being applied to derive explanations of process predictions, due to (1) process domain knowledge not being taken into account, (2) long traces that often tend to be less understandable, and (3) difficulties in optimising the counterfactual search with categorical variables. We design an extension of DiCE that can generate counterfactuals for process predictions, and propose an approach that supports deriving milestone-aware counterfactuals at different stages of a trace to promote interpretability. We apply our approach to BPIC2012 event log and the analysis results demonstrate the effectiveness of the proposed approach.