 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTri-Subspaces Disentanglement for Multimodal Sentiment Analysis
Feb 23, 2026Multimodal Sentiment Analysis (MSA) integrates language, visual, and acoustic modalities to infer human sentiment. Most existing methods either focus on globally shared representations or modality-specific features, while overlooking signals that are shared only by certain modality pairs. This limits the expressiveness and discriminative power of multimodal representations. To address this limitation, we propose a Tri-Subspace Disentanglement (TSD) framework that explicitly factorizes features into three complementary subspaces: a common subspace capturing global consistency, submodally-shared subspaces modeling pairwise cross-modal synergies, and private subspaces preserving modality-specific cues. To keep these subspaces pure and independent, we introduce a decoupling supervisor together with structured regularization losses. We further design a Subspace-Aware Cross-Attention (SACA) fusion module that adaptively models and integrates information from the three subspaces to obtain richer and more robust representations. Experiments on CMU-MOSI and CMU-MOSEI demonstrate that TSD achieves state-of-the-art performance across all key metrics, reaching 0.691 MAE on CMU-MOSI and 54.9% ACC-7 on CMU-MOSEI, and also transfers well to multimodal intent recognition tasks. Ablation studies confirm that tri-subspace disentanglement and SACA jointly enhance the modeling of multi-granular cross-modal sentiment cues.
CLCR: Cross-Level Semantic Collaborative Representation for Multimodal Learning
Feb 23, 2026Multimodal learning aims to capture both shared and private information from multiple modalities. However, existing methods that project all modalities into a single latent space for fusion often overlook the asynchronous, multi-level semantic structure of multimodal data. This oversight induces semantic misalignment and error propagation, thereby degrading representation quality. To address this issue, we propose Cross-Level Co-Representation (CLCR), which explicitly organizes each modality's features into a three-level semantic hierarchy and specifies level-wise constraints for cross-modal interactions. First, a semantic hierarchy encoder aligns shallow, mid, and deep features across modalities, establishing a common basis for interaction. And then, at each level, an Intra-Level Co-Exchange Domain (IntraCED) factorizes features into shared and private subspaces and restricts cross-modal attention to the shared subspace via a learnable token budget. This design ensures that only shared semantics are exchanged and prevents leakage from private channels. To integrate information across levels, the Inter-Level Co-Aggregation Domain (InterCAD) synchronizes semantic scales using learned anchors, selectively fuses the shared representations, and gates private cues to form a compact task representation. We further introduce regularization terms to enforce separation of shared and private features and to minimize cross-level interference. Experiments on six benchmarks spanning emotion recognition, event localization, sentiment analysis, and action recognition show that CLCR achieves strong performance and generalizes well across tasks.
Multi-Horizon Electricity Price Forecasting with Deep Learning in the Australian National Electricity Market
Feb 01, 2026Accurate electricity price forecasting (EPF) is essential for operational planning, trading, and flexible asset scheduling in liberalised power systems, yet remains challenging due to volatility, heavy-tailed spikes, and frequent regime shifts. While deep learning (DL) has been increasingly adopted in EPF to capture complex and nonlinear price dynamics, several important gaps persist: (i) limited attention to multi-day horizons beyond day-ahead forecasting, (ii) insufficient exploration of state-of-the-art (SOTA) time series DL models, and (iii) a predominant reliance on aggregated horizon-level evaluation that obscures time-of-day forecasting variation. To address these gaps, we propose a novel EPF framework that extends the forecast horizon to multi-day-ahead by systematically building forecasting models that leverage benchmarked SOTA time series DL models. We conduct a comprehensive evaluation to analyse time-of-day forecasting performance by integrating model assessment at intraday interval levels across all five regions in the Australian National Electricity Market (NEM). The results show that no single model consistently dominates across regions, metrics, and horizons. Overall, standard DL models deliver superior performance in most regions, while SOTA time series DL models demonstrate greater robustness to forecast horizon extension. Intraday interval-level evaluation reveals pronounced diurnal error patterns, indicating that absolute errors peak during the evening ramp, relative errors inflate during midday negative-price regimes, and directional accuracy degrades during periods of frequent trend changes. These findings suggest that future research on DL-based EPF can benefit from enriched feature representations and modelling strategies that enhance longer-term forecasting robustness while maintaining sensitivity to intraday volatility and structural price dynamics.
Temporal-Spatial Decouple before Act: Disentangled Representation Learning for Multimodal Sentiment Analysis
Jan 20, 2026Multimodal Sentiment Analysis integrates Linguistic, Visual, and Acoustic. Mainstream approaches based on modality-invariant and modality-specific factorization or on complex fusion still rely on spatiotemporal mixed modeling. This ignores spatiotemporal heterogeneity, leading to spatiotemporal information asymmetry and thus limited performance. Hence, we propose TSDA, Temporal-Spatial Decouple before Act, which explicitly decouples each modality into temporal dynamics and spatial structural context before any interaction. For every modality, a temporal encoder and a spatial encoder project signals into separate temporal and spatial body. Factor-Consistent Cross-Modal Alignment then aligns temporal features only with their temporal counterparts across modalities, and spatial features only with their spatial counterparts. Factor specific supervision and decorrelation regularization reduce cross factor leakage while preserving complementarity. A Gated Recouple module subsequently recouples the aligned streams for task. Extensive experiments show that TSDA outperforms baselines. Ablation analysis studies confirm the necessity and interpretability of the design.
Pheromone-Focused Ant Colony Optimization algorithm for path planning
Jan 12, 2026Ant Colony Optimization (ACO) is a prominent swarm intelligence algorithm extensively applied to path planning. However, traditional ACO methods often exhibit shortcomings, such as blind search behavior and slow convergence within complex environments. To address these challenges, this paper proposes the Pheromone-Focused Ant Colony Optimization (PFACO) algorithm, which introduces three key strategies to enhance the problem-solving ability of the ant colony. First, the initial pheromone distribution is concentrated in more promising regions based on the Euclidean distances of nodes to the start and end points, balancing the trade-off between exploration and exploitation. Second, promising solutions are reinforced during colony iterations to intensify pheromone deposition along high-quality paths, accelerating convergence while maintaining solution diversity. Third, a forward-looking mechanism is implemented to penalize redundant path turns, promoting smoother and more efficient solutions. These strategies collectively produce the focused pheromones to guide the ant colony's search, which enhances the global optimization capabilities of the PFACO algorithm, significantly improving convergence speed and solution quality across diverse optimization problems. The experimental results demonstrate that PFACO consistently outperforms comparative ACO algorithms in terms of convergence speed and solution quality.
TabAttackBench: A Benchmark for Adversarial Attacks on Tabular Data
May 27, 2025Adversarial attacks pose a significant threat to machine learning models by inducing incorrect predictions through imperceptible perturbations to input data. While these attacks have been extensively studied in unstructured data like images, their application to tabular data presents new challenges. These challenges arise from the inherent heterogeneity and complex feature interdependencies in tabular data, which differ significantly from those in image data. To address these differences, it is crucial to consider imperceptibility as a key criterion specific to tabular data. Most current research focuses primarily on achieving effective adversarial attacks, often overlooking the importance of maintaining imperceptibility. To address this gap, we propose a new benchmark for adversarial attacks on tabular data that evaluates both effectiveness and imperceptibility. In this study, we assess the effectiveness and imperceptibility of five adversarial attacks across four models using eleven tabular datasets, including both mixed and numerical-only datasets. Our analysis explores how these factors interact and influence the overall performance of the attacks. We also compare the results across different dataset types to understand the broader implications of these findings. The findings from this benchmark provide valuable insights for improving the design of adversarial attack algorithms, thereby advancing the field of adversarial machine learning on tabular data.
ViG3D-UNet: Volumetric Vascular Connectivity-Aware Segmentation via 3D Vision Graph Representation
Apr 18, 2025



Accurate vascular segmentation is essential for coronary visualization and the diagnosis of coronary heart disease. This task involves the extraction of sparse tree-like vascular branches from the volumetric space. However, existing methods have faced significant challenges due to discontinuous vascular segmentation and missing endpoints. To address this issue, a 3D vision graph neural network framework, named ViG3D-UNet, was introduced. This method integrates 3D graph representation and aggregation within a U-shaped architecture to facilitate continuous vascular segmentation. The ViG3D module captures volumetric vascular connectivity and topology, while the convolutional module extracts fine vascular details. These two branches are combined through channel attention to form the encoder feature. Subsequently, a paperclip-shaped offset decoder minimizes redundant computations in the sparse feature space and restores the feature map size to match the original input dimensions. To evaluate the effectiveness of the proposed approach for continuous vascular segmentation, evaluations were performed on two public datasets, ASOCA and ImageCAS. The segmentation results show that the ViG3D-UNet surpassed competing methods in maintaining vascular segmentation connectivity while achieving high segmentation accuracy. Our code will be available soon.
Investigating Imperceptibility of Adversarial Attacks on Tabular Data: An Empirical Analysis
Jul 16, 2024Adversarial attacks are a potential threat to machine learning models, as they can cause the model to make incorrect predictions by introducing imperceptible perturbations to the input data. While extensively studied in unstructured data like images, their application to structured data like tabular data presents unique challenges due to the heterogeneity and intricate feature interdependencies of tabular data. Imperceptibility in tabular data involves preserving data integrity while potentially causing misclassification, underscoring the need for tailored imperceptibility criteria for tabular data. However, there is currently a lack of standardised metrics for assessing adversarial attacks specifically targeted at tabular data. To address this gap, we derive a set of properties for evaluating the imperceptibility of adversarial attacks on tabular data. These properties are defined to capture seven perspectives of perturbed data: proximity to original inputs, sparsity of alterations, deviation to datapoints in the original dataset, sensitivity of altering sensitive features, immutability of perturbation, feasibility of perturbed values and intricate feature interdepencies among tabular features. Furthermore, we conduct both quantitative empirical evaluation and case-based qualitative examples analysis for seven properties. The evaluation reveals a trade-off between attack success and imperceptibility, particularly concerning proximity, sensitivity, and deviation. Although no evaluated attacks can achieve optimal effectiveness and imperceptibility simultaneously, unbounded attacks prove to be more promised for tabular data in crafting imperceptible adversarial examples. The study also highlights the limitation of evaluated algorithms in controlling sparsity effectively. We suggest incorporating a sparsity metric in future attack design to regulate the number of perturbed features.
DALL-M: Context-Aware Clinical Data Augmentation with LLMs
Jul 11, 2024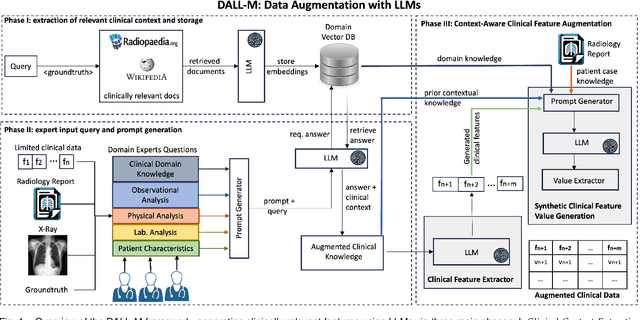


X-ray images are vital in medical diagnostics, but their effectiveness is limited without clinical context. Radiologists often find chest X-rays insufficient for diagnosing underlying diseases, necessitating comprehensive clinical features and data integration. We present a novel technique to enhance the clinical context through augmentation techniques with clinical tabular data, thereby improving its applicability and reliability in AI medical diagnostics. To address this, we introduce a pioneering approach to clinical data augmentation that employs large language models (LLMs) to generate patient contextual synthetic data. This methodology is crucial for training more robust deep learning models in healthcare. It preserves the integrity of real patient data while enriching the dataset with contextually relevant synthetic features, significantly enhancing model performance. DALL-M uses a three-phase feature generation process: (i) clinical context storage, (ii) expert query generation, and (iii) context-aware feature augmentation. DALL-M generates new, clinically relevant features by synthesizing chest X-ray images and reports. Applied to 799 cases using nine features from the MIMIC-IV dataset, it created an augmented set of 91 features. This is the first work to generate contextual values for existing and new features based on patients' X-ray reports, gender, and age and to produce new contextual knowledge during data augmentation. Empirical validation with machine learning models, including Decision Trees, Random Forests, XGBoost, and TabNET, showed significant performance improvements. Incorporating augmented features increased the F1 score by 16.5% and Precision and Recall by approximately 25%. DALL-M addresses a critical gap in clinical data augmentation, offering a robust framework for generating contextually enriched datasets.
Generating Feasible and Plausible Counterfactual Explanations for Outcome Prediction of Business Processes
Mar 14, 2024



In recent years, various machine and deep learning architectures have been successfully introduced to the field of predictive process analytics. Nevertheless, the inherent opacity of these algorithms poses a significant challenge for human decision-makers, hindering their ability to understand the reasoning behind the predictions. This growing concern has sparked the introduction of counterfactual explanations, designed as human-understandable what if scenarios, to provide clearer insights into the decision-making process behind undesirable predictions. The generation of counterfactual explanations, however, encounters specific challenges when dealing with the sequential nature of the (business) process cases typically used in predictive process analytics. Our paper tackles this challenge by introducing a data-driven approach, REVISEDplus, to generate more feasible and plausible counterfactual explanations. First, we restrict the counterfactual algorithm to generate counterfactuals that lie within a high-density region of the process data, ensuring that the proposed counterfactuals are realistic and feasible within the observed process data distribution. Additionally, we ensure plausibility by learning sequential patterns between the activities in the process cases, utilising Declare language templates. Finally, we evaluate the properties that define the validity of counterfactuals.