 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Realistic Adversarial Examples for Business Processes using Variational Autoencoders
Nov 21, 2024



In predictive process monitoring, predictive models are vulnerable to adversarial attacks, where input perturbations can lead to incorrect predictions. Unlike in computer vision, where these perturbations are designed to be imperceptible to the human eye, the generation of adversarial examples in predictive process monitoring poses unique challenges. Minor changes to the activity sequences can create improbable or even impossible scenarios to occur due to underlying constraints such as regulatory rules or process constraints. To address this, we focus on generating realistic adversarial examples tailored to the business process context, in contrast to the imperceptible, pixel-level changes commonly seen in computer vision adversarial attacks. This paper introduces two novel latent space attacks, which generate adversaries by adding noise to the latent space representation of the input data, rather than directly modifying the input attributes. These latent space methods are domain-agnostic and do not rely on process-specific knowledge, as we restrict the generation of adversarial examples to the learned class-specific data distributions by directly perturbing the latent space representation of the business process executions. We evaluate these two latent space methods with six other adversarial attacking methods on eleven real-life event logs and four predictive models. The first three attacking methods directly permute the activities of the historically observed business process executions. The fourth method constrains the adversarial examples to lie within the same data distribution as the original instances, by projecting the adversarial examples to the original data distribution.
Generating Feasible and Plausible Counterfactual Explanations for Outcome Prediction of Business Processes
Mar 14, 2024



In recent years, various machine and deep learning architectures have been successfully introduced to the field of predictive process analytics. Nevertheless, the inherent opacity of these algorithms poses a significant challenge for human decision-makers, hindering their ability to understand the reasoning behind the predictions. This growing concern has sparked the introduction of counterfactual explanations, designed as human-understandable what if scenarios, to provide clearer insights into the decision-making process behind undesirable predictions. The generation of counterfactual explanations, however, encounters specific challenges when dealing with the sequential nature of the (business) process cases typically used in predictive process analytics. Our paper tackles this challenge by introducing a data-driven approach, REVISEDplus, to generate more feasible and plausible counterfactual explanations. First, we restrict the counterfactual algorithm to generate counterfactuals that lie within a high-density region of the process data, ensuring that the proposed counterfactuals are realistic and feasible within the observed process data distribution. Additionally, we ensure plausibility by learning sequential patterns between the activities in the process cases, utilising Declare language templates. Finally, we evaluate the properties that define the validity of counterfactuals.
Explainable Artificial Intelligence in Process Mining: Assessing the Explainability-Performance Trade-Off in Outcome-Oriented Predictive Process Monitoring
Mar 30, 2022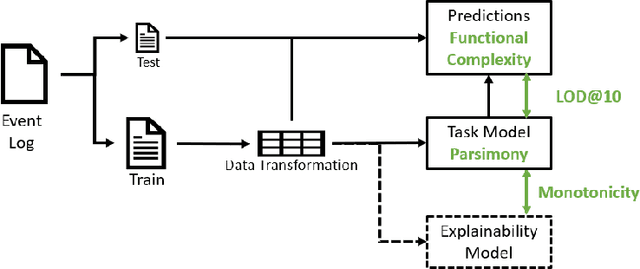
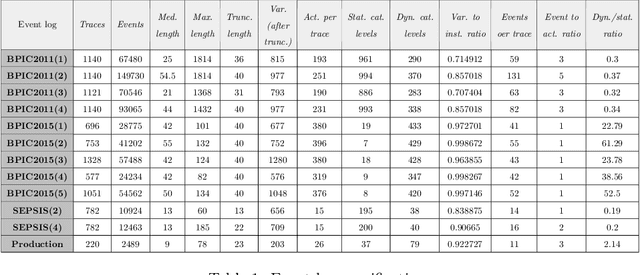
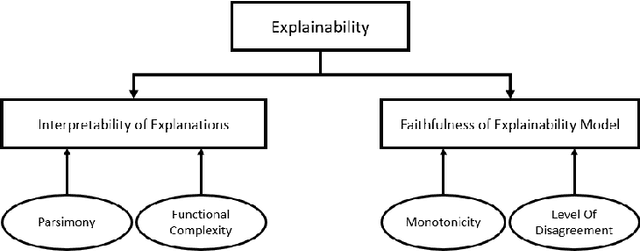
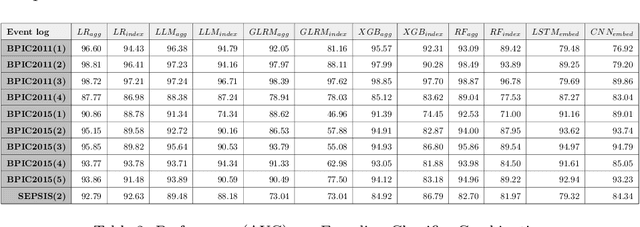
Recently, a shift has been made in the field of Outcome-Oriented Predictive Process Monitoring (OOPPM) to use models from the eXplainable Artificial Intelligence paradigm, however the evaluation still occurs mainly through performance-based metrics not accounting for the implications and lack of actionability of the explanations. In this paper, we define explainability by the interpretability of the explanations (through the widely-used XAI properties parsimony and functional complexity) and the faithfulness of the explainability model (through monotonicity and level of disagreement). The introduced properties are analysed along the event, case, and control flow perspective that are typical of a process-based analysis. This allows to quantitatively compare, inter alia, inherently created explanations (e.g., logistic regression coefficients) with post-hoc explanations (e.g., Shapley values). Moreover, this paper contributes a guideline named X-MOP to practitioners to select the appropriate model based on the event log specifications and the task at hand, by providing insight into how the varying preprocessing, model complexity and post-hoc explainability techniques typical in OOPPM influence the explainability of the model. To this end, we benchmark seven classifiers on thirteen real-life events logs.