 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIFF-ERO: A Conformance-Aware Loss for Deep Learning in Process Mining
Jun 12, 2026Deep learning has driven many recent advances in process analytics, especially for predictive and prescriptive monitoring. However, standard objectives such as cross-entropy optimize local next-step likelihoods and only implicitly capture control-flow structure. As a result, models can achieve high token-level accuracy while permitting imprecise global behaviour. We introduce DIFF-ERO, a conformance-aware loss function for deep learning models on process data. DIFF-ERO is a differentiable formulation of entropy-based stochastic conformance that incorporates control-flow information during training. Our approach constructs batch-level stochastic transition matrices with soft edge memberships, allowing structural precision and recall signals to directly inform backpropagation. The loss is model-agnostic and can be applied whenever the final representation parametrizes stochastic transitions. We instantiate DIFF-ERO in transformer encoder-decoder pipelines for next-activity prediction and use it jointly with cross-entropy to analyse its theoretical components with respect to convergence. Across benchmarks comparing other loss functions and targets, DIFF-ERO shows improved predictive performance where structure matters most while maintaining parity elsewhere. At the same time, the learned stochastic automaton converges towards the structural ground truth, indicating that the network internalizes process model structure.
Time Series Foundation Models for Process Model Forecasting
Dec 08, 2025



Process Model Forecasting (PMF) aims to predict how the control-flow structure of a process evolves over time by modeling the temporal dynamics of directly-follows (DF) relations, complementing predictive process monitoring that focuses on single-case prefixes. Prior benchmarks show that machine learning and deep learning models provide only modest gains over statistical baselines, mainly due to the sparsity and heterogeneity of the DF time series. We investigate Time Series Foundation Models (TSFMs), large pre-trained models for generic time series, as an alternative for PMF. Using DF time series derived from real-life event logs, we compare zero-shot use of TSFMs, without additional training, with fine-tuned variants adapted on PMF-specific data. TSFMs generally achieve lower forecasting errors (MAE and RMSE) than traditional and specialized models trained from scratch on the same logs, indicating effective transfer of temporal structure from non-process domains. While fine-tuning can further improve accuracy, the gains are often small and may disappear on smaller or more complex datasets, so zero-shot use remains a strong default. Our study highlights the generalization capability and data efficiency of TSFMs for process-related time series and, to the best of our knowledge, provides the first systematic evaluation of temporal foundation models for PMF.
Achieving Group Fairness through Independence in Predictive Process Monitoring
Dec 06, 2024Predictive process monitoring focuses on forecasting future states of ongoing process executions, such as predicting the outcome of a particular case. In recent years, the application of machine learning models in this domain has garnered significant scientific attention. When using historical execution data, which may contain biases or exhibit unfair behavior, these biases may be encoded into the trained models. Consequently, when such models are deployed to make decisions or guide interventions for new cases, they risk perpetuating this unwanted behavior. This work addresses group fairness in predictive process monitoring by investigating independence, i.e. ensuring predictions are unaffected by sensitive group membership. We explore independence through metrics for demographic parity such as $\Delta$DP, as well as recently introduced, threshold-independent distribution-based alternatives. Additionally, we propose a composite loss functions existing of binary cross-entropy and a distribution-based loss (Wasserstein) to train models that balance predictive performance and fairness, and allow for customizable trade-offs. The effectiveness of both the fairness metrics and the composite loss functions is validated through a controlled experimental setup.
Generating Realistic Adversarial Examples for Business Processes using Variational Autoencoders
Nov 21, 2024



In predictive process monitoring, predictive models are vulnerable to adversarial attacks, where input perturbations can lead to incorrect predictions. Unlike in computer vision, where these perturbations are designed to be imperceptible to the human eye, the generation of adversarial examples in predictive process monitoring poses unique challenges. Minor changes to the activity sequences can create improbable or even impossible scenarios to occur due to underlying constraints such as regulatory rules or process constraints. To address this, we focus on generating realistic adversarial examples tailored to the business process context, in contrast to the imperceptible, pixel-level changes commonly seen in computer vision adversarial attacks. This paper introduces two novel latent space attacks, which generate adversaries by adding noise to the latent space representation of the input data, rather than directly modifying the input attributes. These latent space methods are domain-agnostic and do not rely on process-specific knowledge, as we restrict the generation of adversarial examples to the learned class-specific data distributions by directly perturbing the latent space representation of the business process executions. We evaluate these two latent space methods with six other adversarial attacking methods on eleven real-life event logs and four predictive models. The first three attacking methods directly permute the activities of the historically observed business process executions. The fourth method constrains the adversarial examples to lie within the same data distribution as the original instances, by projecting the adversarial examples to the original data distribution.
Can recurrent neural networks learn process model structure?
Dec 13, 2022Various methods using machine and deep learning have been proposed to tackle different tasks in predictive process monitoring, forecasting for an ongoing case e.g. the most likely next event or suffix, its remaining time, or an outcome-related variable. Recurrent neural networks (RNNs), and more specifically long short-term memory nets (LSTMs), stand out in terms of popularity. In this work, we investigate the capabilities of such an LSTM to actually learn the underlying process model structure of an event log. We introduce an evaluation framework that combines variant-based resampling and custom metrics for fitness, precision and generalization. We evaluate 4 hypotheses concerning the learning capabilities of LSTMs, the effect of overfitting countermeasures, the level of incompleteness in the training set and the level of parallelism in the underlying process model. We confirm that LSTMs can struggle to learn process model structure, even with simplistic process data and in a very lenient setup. Taking the correct anti-overfitting measures can alleviate the problem. However, these measures did not present themselves to be optimal when selecting hyperparameters purely on predicting accuracy. We also found that decreasing the amount of information seen by the LSTM during training, causes a sharp drop in generalization and precision scores. In our experiments, we could not identify a relationship between the extent of parallelism in the model and the generalization capability, but they do indicate that the process' complexity might have impact.
Enhancing Stochastic Petri Net-based Remaining Time Prediction using k-Nearest Neighbors
Jun 27, 2022

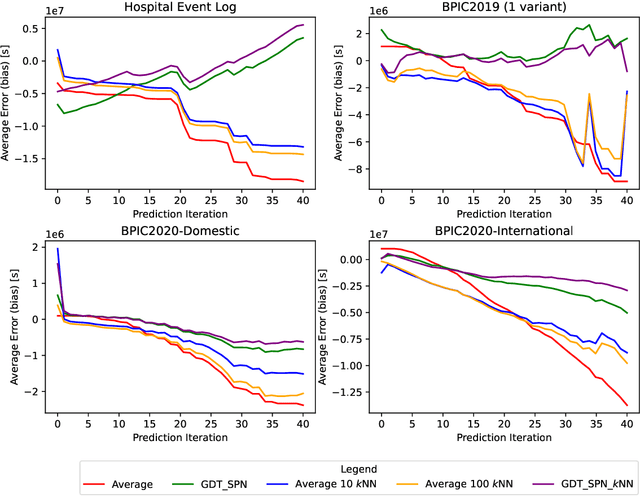
Reliable remaining time prediction of ongoing business processes is a highly relevant topic. One example is order delivery, a key competitive factor in e.g. retailing as it is a main driver of customer satisfaction. For realising timely delivery, an accurate prediction of the remaining time of the delivery process is crucial. Within the field of process mining, a wide variety of remaining time prediction techniques have already been proposed. In this work, we extend remaining time prediction based on stochastic Petri nets with generally distributed transitions with k-nearest neighbors. The k-nearest neighbors algorithm is performed on simple vectors storing the time passed to complete previous activities. By only taking a subset of instances, a more representative and stable stochastic Petri Net is obtained, leading to more accurate time predictions. We discuss the technique and its basic implementation in Python and use different real world data sets to evaluate the predictive power of our extension. These experiments show clear advantages in combining both techniques with regard to predictive power.
Can deep neural networks learn process model structure? An assessment framework and analysis
Feb 24, 2022

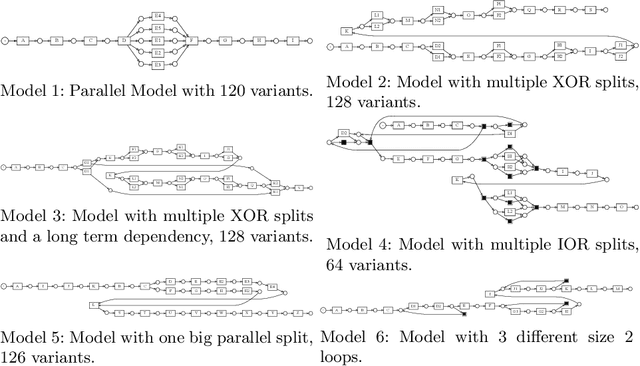
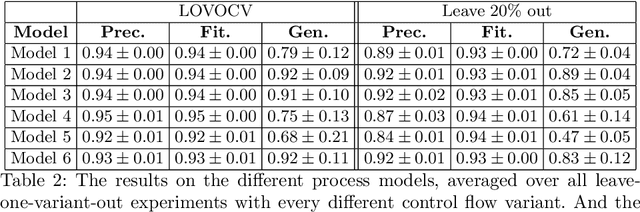
Predictive process monitoring concerns itself with the prediction of ongoing cases in (business) processes. Prediction tasks typically focus on remaining time, outcome, next event or full case suffix prediction. Various methods using machine and deep learning havebeen proposed for these tasks in recent years. Especially recurrent neural networks (RNNs) such as long short-term memory nets (LSTMs) have gained in popularity. However, no research focuses on whether such neural network-based models can truly learn the structure of underlying process models. For instance, can such neural networks effectively learn parallel behaviour or loops? Therefore, in this work, we propose an evaluation scheme complemented with new fitness, precision, and generalisation metrics, specifically tailored towards measuring the capacity of deep learning models to learn process model structure. We apply this framework to several process models with simple control-flow behaviour, on the task of next-event prediction. Our results show that, even for such simplistic models, careful tuning of overfitting countermeasures is required to allow these models to learn process model structure.