 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Performance of LLMs for Real Estate Appraisal
Jun 13, 2025The real estate market is vital to global economies but suffers from significant information asymmetry. This study examines how Large Language Models (LLMs) can democratize access to real estate insights by generating competitive and interpretable house price estimates through optimized In-Context Learning (ICL) strategies. We systematically evaluate leading LLMs on diverse international housing datasets, comparing zero-shot, few-shot, market report-enhanced, and hybrid prompting techniques. Our results show that LLMs effectively leverage hedonic variables, such as property size and amenities, to produce meaningful estimates. While traditional machine learning models remain strong for pure predictive accuracy, LLMs offer a more accessible, interactive and interpretable alternative. Although self-explanations require cautious interpretation, we find that LLMs explain their predictions in agreement with state-of-the-art models, confirming their trustworthiness. Carefully selected in-context examples based on feature similarity and geographic proximity, significantly enhance LLM performance, yet LLMs struggle with overconfidence in price intervals and limited spatial reasoning. We offer practical guidance for structured prediction tasks through prompt optimization. Our findings highlight LLMs' potential to improve transparency in real estate appraisal and provide actionable insights for stakeholders.
Can recurrent neural networks learn process model structure?
Dec 13, 2022Various methods using machine and deep learning have been proposed to tackle different tasks in predictive process monitoring, forecasting for an ongoing case e.g. the most likely next event or suffix, its remaining time, or an outcome-related variable. Recurrent neural networks (RNNs), and more specifically long short-term memory nets (LSTMs), stand out in terms of popularity. In this work, we investigate the capabilities of such an LSTM to actually learn the underlying process model structure of an event log. We introduce an evaluation framework that combines variant-based resampling and custom metrics for fitness, precision and generalization. We evaluate 4 hypotheses concerning the learning capabilities of LSTMs, the effect of overfitting countermeasures, the level of incompleteness in the training set and the level of parallelism in the underlying process model. We confirm that LSTMs can struggle to learn process model structure, even with simplistic process data and in a very lenient setup. Taking the correct anti-overfitting measures can alleviate the problem. However, these measures did not present themselves to be optimal when selecting hyperparameters purely on predicting accuracy. We also found that decreasing the amount of information seen by the LSTM during training, causes a sharp drop in generalization and precision scores. In our experiments, we could not identify a relationship between the extent of parallelism in the model and the generalization capability, but they do indicate that the process' complexity might have impact.
Can deep neural networks learn process model structure? An assessment framework and analysis
Feb 24, 2022

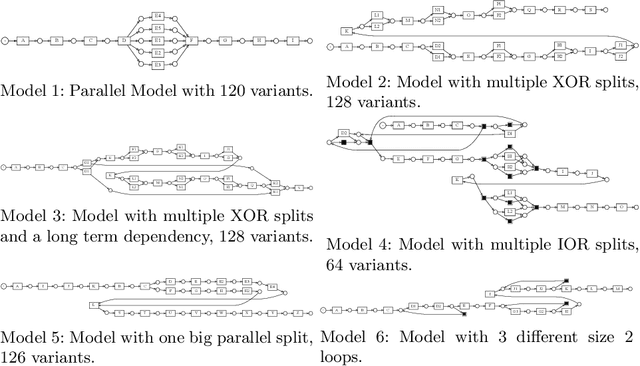
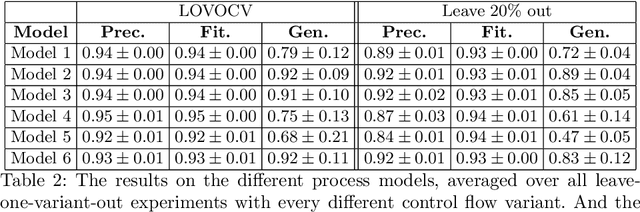
Predictive process monitoring concerns itself with the prediction of ongoing cases in (business) processes. Prediction tasks typically focus on remaining time, outcome, next event or full case suffix prediction. Various methods using machine and deep learning havebeen proposed for these tasks in recent years. Especially recurrent neural networks (RNNs) such as long short-term memory nets (LSTMs) have gained in popularity. However, no research focuses on whether such neural network-based models can truly learn the structure of underlying process models. For instance, can such neural networks effectively learn parallel behaviour or loops? Therefore, in this work, we propose an evaluation scheme complemented with new fitness, precision, and generalisation metrics, specifically tailored towards measuring the capacity of deep learning models to learn process model structure. We apply this framework to several process models with simple control-flow behaviour, on the task of next-event prediction. Our results show that, even for such simplistic models, careful tuning of overfitting countermeasures is required to allow these models to learn process model structure.
Expert-driven Trace Clustering with Instance-level Constraints
Oct 13, 2021



Within the field of process mining, several different trace clustering approaches exist for partitioning traces or process instances into similar groups. Typically, this partitioning is based on certain patterns or similarity between the traces, or driven by the discovery of a process model for each cluster. The main drawback of these techniques, however, is that their solutions are usually hard to evaluate or justify by domain experts. In this paper, we present two constrained trace clustering techniques that are capable to leverage expert knowledge in the form of instance-level constraints. In an extensive experimental evaluation using two real-life datasets, we show that our novel techniques are indeed capable of producing clustering solutions that are more justifiable without a substantial negative impact on their quality.
Profit Driven Decision Trees for Churn Prediction
Dec 21, 2017



Customer retention campaigns increasingly rely on predictive models to detect potential churners in a vast customer base. From the perspective of machine learning, the task of predicting customer churn can be presented as a binary classification problem. Using data on historic behavior, classification algorithms are built with the purpose of accurately predicting the probability of a customer defecting. The predictive churn models are then commonly selected based on accuracy related performance measures such as the area under the ROC curve (AUC). However, these models are often not well aligned with the core business requirement of profit maximization, in the sense that, the models fail to take into account not only misclassification costs, but also the benefits originating from a correct classification. Therefore, the aim is to construct churn prediction models that are profitable and preferably interpretable too. The recently developed expected maximum profit measure for customer churn (EMPC) has been proposed in order to select the most profitable churn model. We present a new classifier that integrates the EMPC metric directly into the model construction. Our technique, called ProfTree, uses an evolutionary algorithm for learning profit driven decision trees. In a benchmark study with real-life data sets from various telecommunication service providers, we show that ProfTree achieves significant profit improvements compared to classic accuracy driven tree-based methods.