 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINFLECT-DGNN: Influencer Prediction with Dynamic Graph Neural Networks
Jul 16, 2023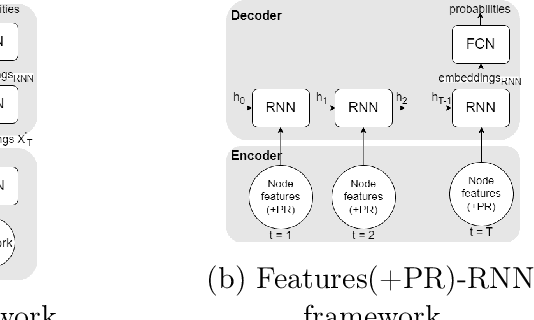

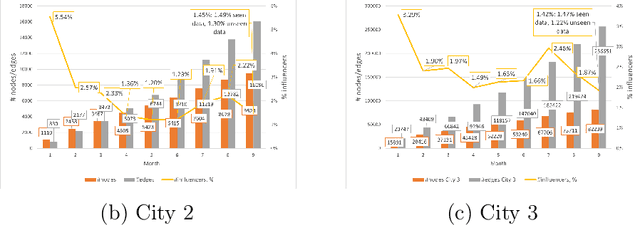
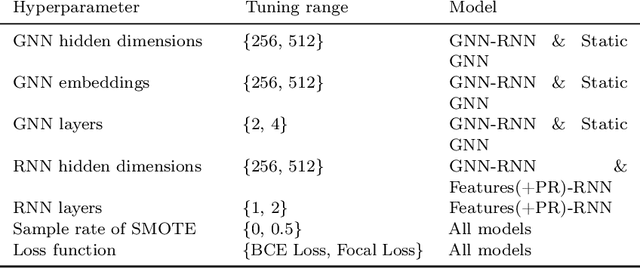
Leveraging network information for predictive modeling has become widespread in many domains. Within the realm of referral and targeted marketing, influencer detection stands out as an area that could greatly benefit from the incorporation of dynamic network representation due to the ongoing development of customer-brand relationships. To elaborate this idea, we introduce INFLECT-DGNN, a new framework for INFLuencer prEdiCTion with Dynamic Graph Neural Networks that combines Graph Neural Networks (GNN) and Recurrent Neural Networks (RNN) with weighted loss functions, the Synthetic Minority Oversampling TEchnique (SMOTE) adapted for graph data, and a carefully crafted rolling-window strategy. To evaluate predictive performance, we utilize a unique corporate data set with networks of three cities and derive a profit-driven evaluation methodology for influencer prediction. Our results show how using RNN to encode temporal attributes alongside GNNs significantly improves predictive performance. We compare the results of various models to demonstrate the importance of capturing graph representation, temporal dependencies, and using a profit-driven methodology for evaluation.
Influencer Detection with Dynamic Graph Neural Networks
Nov 15, 2022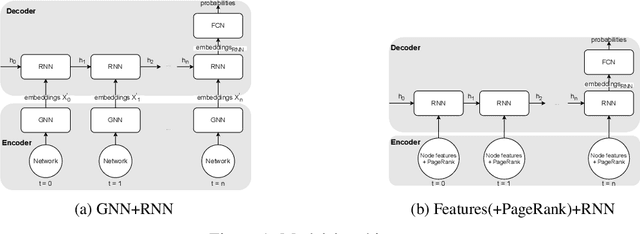
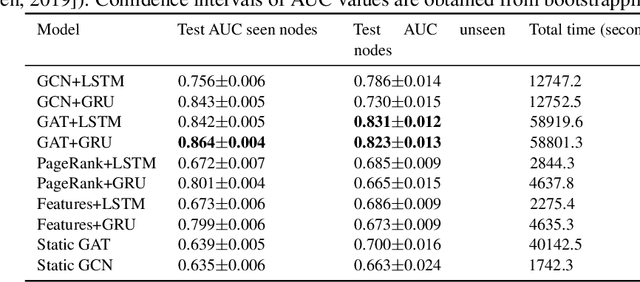
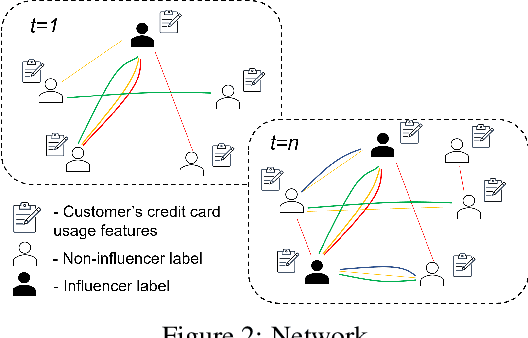
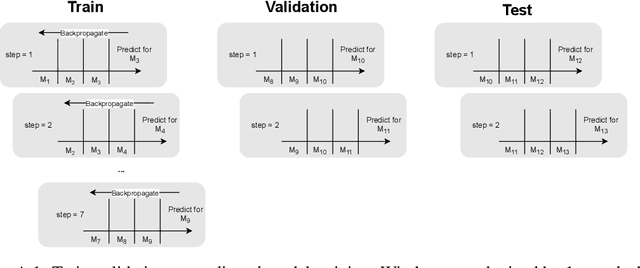
Leveraging network information for prediction tasks has become a common practice in many domains. Being an important part of targeted marketing, influencer detection can potentially benefit from incorporating dynamic network representation. In this work, we investigate different dynamic Graph Neural Networks (GNNs) configurations for influencer detection and evaluate their prediction performance using a unique corporate data set. We show that using deep multi-head attention in GNN and encoding temporal attributes significantly improves performance. Furthermore, our empirical evaluation illustrates that capturing neighborhood representation is more beneficial that using network centrality measures.
Expert-driven Trace Clustering with Instance-level Constraints
Oct 13, 2021



Within the field of process mining, several different trace clustering approaches exist for partitioning traces or process instances into similar groups. Typically, this partitioning is based on certain patterns or similarity between the traces, or driven by the discovery of a process model for each cluster. The main drawback of these techniques, however, is that their solutions are usually hard to evaluate or justify by domain experts. In this paper, we present two constrained trace clustering techniques that are capable to leverage expert knowledge in the form of instance-level constraints. In an extensive experimental evaluation using two real-life datasets, we show that our novel techniques are indeed capable of producing clustering solutions that are more justifiable without a substantial negative impact on their quality.