 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGARG-AML against Smurfing: A Scalable and Interpretable Graph-Based Framework for Anti-Money Laundering
Jun 04, 2025Money laundering poses a significant challenge as it is estimated to account for 2%-5% of the global GDP. This has compelled regulators to impose stringent controls on financial institutions. One prominent laundering method for evading these controls, called smurfing, involves breaking up large transactions into smaller amounts. Given the complexity of smurfing schemes, which involve multiple transactions distributed among diverse parties, network analytics has become an important anti-money laundering tool. However, recent advances have focused predominantly on black-box network embedding methods, which has hindered their adoption in businesses. In this paper, we introduce GARG-AML, a novel graph-based method that quantifies smurfing risk through a single interpretable metric derived from the structure of the second-order transaction network of each individual node in the network. Unlike traditional methods, GARG-AML strikes an effective balance among computational efficiency, detection power and transparency, which enables its integration into existing AML workflows. To enhance its capabilities, we combine the GARG-AML score calculation with different tree-based methods and also incorporate the scores of the node's neighbours. An experimental evaluation on large-scale synthetic and open-source networks demonstrate that the GARG-AML outperforms the current state-of-the-art smurfing detection methods. By leveraging only the adjacency matrix of the second-order neighbourhood and basic network features, this work highlights the potential of fundamental network properties towards advancing fraud detection.
Independent Component Analysis by Robust Distance Correlation
May 14, 2025Independent component analysis (ICA) is a powerful tool for decomposing a multivariate signal or distribution into fully independent sources, not just uncorrelated ones. Unfortunately, most approaches to ICA are not robust against outliers. Here we propose a robust ICA method called RICA, which estimates the components by minimizing a robust measure of dependence between multivariate random variables. The dependence measure used is the distance correlation (dCor). In order to make it more robust we first apply a new transformation called the bowl transform, which is bounded, one-to-one, continuous, and maps far outliers to points close to the origin. This preserves the crucial property that a zero dCor implies independence. RICA estimates the independent sources sequentially, by looking for the component that has the smallest dCor with the remainder. RICA is strongly consistent and has the usual parametric rate of convergence. Its robustness is investigated by a simulation study, in which it generally outperforms its competitors. The method is illustrated on three applications, including the well-known cocktail party problem.
Advances in Continual Graph Learning for Anti-Money Laundering Systems: A Comprehensive Review
Mar 31, 2025Financial institutions are required by regulation to report suspicious financial transactions related to money laundering. Therefore, they need to constantly monitor vast amounts of incoming and outgoing transactions. A particular challenge in detecting money laundering is that money launderers continuously adapt their tactics to evade detection. Hence, detection methods need constant fine-tuning. Traditional machine learning models suffer from catastrophic forgetting when fine-tuning the model on new data, thereby limiting their effectiveness in dynamic environments. Continual learning methods may address this issue and enhance current anti-money laundering (AML) practices, by allowing models to incorporate new information while retaining prior knowledge. Research on continual graph learning for AML, however, is still scarce. In this review, we critically evaluate state-of-the-art continual graph learning approaches for AML applications. We categorise methods into replay-based, regularization-based, and architecture-based strategies within the graph neural network (GNN) framework, and we provide in-depth experimental evaluations on both synthetic and real-world AML data sets that showcase the effect of the different hyperparameters. Our analysis demonstrates that continual learning improves model adaptability and robustness in the face of extreme class imbalances and evolving fraud patterns. Finally, we outline key challenges and propose directions for future research.
RobPy: a Python Package for Robust Statistical Methods
Nov 04, 2024Robust estimation provides essential tools for analyzing data that contain outliers, ensuring that statistical models remain reliable even in the presence of some anomalous data. While robust methods have long been available in R, users of Python have lacked a comprehensive package that offers these methods in a cohesive framework. RobPy addresses this gap by offering a wide range of robust methods in Python, built upon established libraries including NumPy, SciPy, and scikit-learn. This package includes tools for robust preprocessing, univariate estimation, covariance matrices, regression, and principal component analysis, which are able to detect outliers and to mitigate their effect. In addition, RobPy provides specialized diagnostic plots for visualizing casewise and cellwise outliers. This paper presents the structure of the RobPy package, demonstrates its functionality through examples, and compares its features to existing implementations in other statistical software. By bringing robust methods to Python, RobPy enables more users to perform robust data analysis in a modern and versatile programming language.
Sources of Gain: Decomposing Performance in Conditional Average Dose Response Estimation
Jun 12, 2024



Estimating conditional average dose responses (CADR) is an important but challenging problem. Estimators must correctly model the potentially complex relationships between covariates, interventions, doses, and outcomes. In recent years, the machine learning community has shown great interest in developing tailored CADR estimators that target specific challenges. Their performance is typically evaluated against other methods on (semi-) synthetic benchmark datasets. Our paper analyses this practice and shows that using popular benchmark datasets without further analysis is insufficient to judge model performance. Established benchmarks entail multiple challenges, whose impacts must be disentangled. Therefore, we propose a novel decomposition scheme that allows the evaluation of the impact of five distinct components contributing to CADR estimator performance. We apply this scheme to eight popular CADR estimators on four widely-used benchmark datasets, running nearly 1,500 individual experiments. Our results reveal that most established benchmarks are challenging for reasons different from their creators' claims. Notably, confounding, the key challenge tackled by most estimators, is not an issue in any of the considered datasets. We discuss the major implications of our findings and present directions for future research.
Network Analytics for Anti-Money Laundering -- A Systematic Literature Review and Experimental Evaluation
May 31, 2024Money laundering presents a pervasive challenge, burdening society by financing illegal activities. To more effectively combat and detect money laundering, the use of network information is increasingly being explored, exploiting that money laundering necessarily involves interconnected parties. This has lead to a surge in literature on network analytics (NA) for anti-money laundering (AML). The literature, however, is fragmented and a comprehensive overview of existing work is missing. This results in limited understanding of the methods that may be applied and their comparative detection power. Therefore, this paper presents an extensive and systematic review of the literature. We identify and analyse 97 papers in the Web of Science and Scopus databases, resulting in a taxonomy of approaches following the fraud analytics framework of Bockel-Rickermann et al.. Moreover, this paper presents a comprehensive experimental framework to evaluate and compare the performance of prominent NA methods in a uniform setup. The framework is applied on the publicly available Elliptic data set and implements manual feature engineering, random walk-based methods, and deep learning GNNs. We conclude from the results that network analytics increases the predictive power of the AML model with graph neural networks giving the best results. An open source implementation of the experimental framework is provided to facilitate researchers and practitioners to extend upon these results and experiment on proprietary data. As such, we aim to promote a standardised approach towards the analysis and evaluation of network analytics for AML.
Inferring the relationship between soil temperature and the normalized difference vegetation index with machine learning
Dec 19, 2023



Changes in climate can greatly affect the phenology of plants, which can have important feedback effects, such as altering the carbon cycle. These phenological feedback effects are often induced by a shift in the start or end dates of the growing season of plants. The normalized difference vegetation index (NDVI) serves as a straightforward indicator for assessing the presence of green vegetation and can also provide an estimation of the plants' growing season. In this study, we investigated the effect of soil temperature on the timing of the start of the season (SOS), timing of the peak of the season (POS), and the maximum annual NDVI value (PEAK) in subarctic grassland ecosystems between 2014 and 2019. We also explored the impact of other meteorological variables, including air temperature, precipitation, and irradiance, on the inter-annual variation in vegetation phenology. Using machine learning (ML) techniques and SHapley Additive exPlanations (SHAP) values, we analyzed the relative importance and contribution of each variable to the phenological predictions. Our results reveal a significant relationship between soil temperature and SOS and POS, indicating that higher soil temperatures lead to an earlier start and peak of the growing season. However, the Peak NDVI values showed just a slight increase with higher soil temperatures. The analysis of other meteorological variables demonstrated their impacts on the inter-annual variation of the vegetation phenology. Ultimately, this study contributes to our knowledge of the relationships between soil temperature, meteorological variables, and vegetation phenology, providing valuable insights for predicting vegetation phenology characteristics and managing subarctic grasslands in the face of climate change. Additionally, this work provides a solid foundation for future ML-based vegetation phenology studies.
Tree-based Forecasting of Day-ahead Solar Power Generation from Granular Meteorological Features
Nov 30, 2023
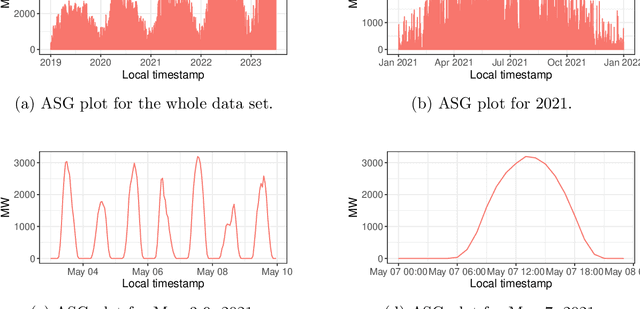
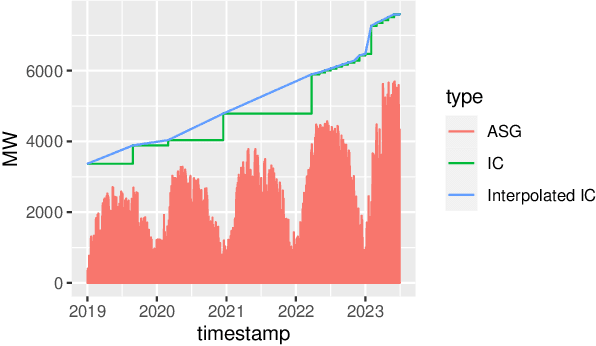

Accurate forecasts for day-ahead photovoltaic (PV) power generation are crucial to support a high PV penetration rate in the local electricity grid and to assure stability in the grid. We use state-of-the-art tree-based machine learning methods to produce such forecasts and, unlike previous studies, we hereby account for (i) the effects various meteorological as well as astronomical features have on PV power production, and this (ii) at coarse as well as granular spatial locations. To this end, we use data from Belgium and forecast day-ahead PV power production at an hourly resolution. The insights from our study can assist utilities, decision-makers, and other stakeholders in optimizing grid operations, economic dispatch, and in facilitating the integration of distributed PV power into the electricity grid.
A Causal Perspective on Loan Pricing: Investigating the Impacts of Selection Bias on Identifying Bid-Response Functions
Sep 07, 2023In lending, where prices are specific to both customers and products, having a well-functioning personalized pricing policy in place is essential to effective business making. Typically, such a policy must be derived from observational data, which introduces several challenges. While the problem of ``endogeneity'' is prominently studied in the established pricing literature, the problem of selection bias (or, more precisely, bid selection bias) is not. We take a step towards understanding the effects of selection bias by posing pricing as a problem of causal inference. Specifically, we consider the reaction of a customer to price a treatment effect. In our experiments, we simulate varying levels of selection bias on a semi-synthetic dataset on mortgage loan applications in Belgium. We investigate the potential of parametric and nonparametric methods for the identification of individual bid-response functions. Our results illustrate how conventional methods such as logistic regression and neural networks suffer adversely from selection bias. In contrast, we implement state-of-the-art methods from causal machine learning and show their capability to overcome selection bias in pricing data.
Learning continuous-valued treatment effects through representation balancing
Sep 07, 2023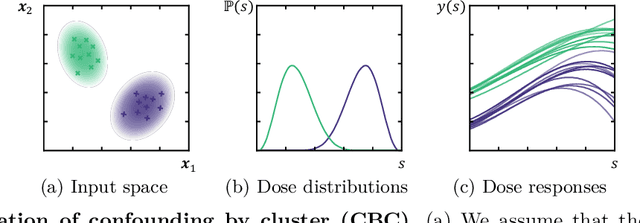
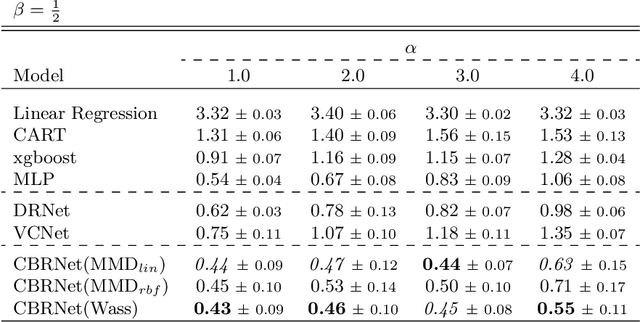
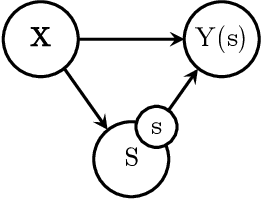
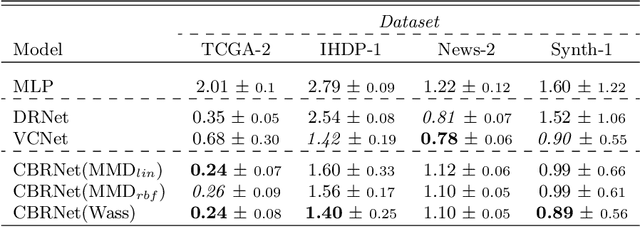
Estimating the effects of treatments with an associated dose on an instance's outcome, the "dose response", is relevant in a variety of domains, from healthcare to business, economics, and beyond. Such effects, also known as continuous-valued treatment effects, are typically estimated from observational data, which may be subject to dose selection bias. This means that the allocation of doses depends on pre-treatment covariates. Previous studies have shown that conventional machine learning approaches fail to learn accurate individual estimates of dose responses under the presence of dose selection bias. In this work, we propose CBRNet, a causal machine learning approach to estimate an individual dose response from observational data. CBRNet adopts the Neyman-Rubin potential outcome framework and extends the concept of balanced representation learning for overcoming selection bias to continuous-valued treatments. Our work is the first to apply representation balancing in a continuous-valued treatment setting. We evaluate our method on a newly proposed benchmark. Our experiments demonstrate CBRNet's ability to accurately learn treatment effects under selection bias and competitive performance with respect to other state-of-the-art methods.